Carregar apresentação
A apresentação está carregando. Por favor, espere

1
1- Experimentos com Um Único Fator: A Análise de Variância (ANOVA)
Fator é uma variável independente em estudo, por exemplo, solventes, aditivos. Estes fatores geralmente envolvem diversos níveis. A ANOVA é utilizada para verificar se existem diferenças significativas entre os níveis dos fatores (tratamentos). Aqui assume-se que o delineamento é completamente casualizado. Estes experimentos só podem ser realizados quando as unidades experimentais são homogêneas. Por exemplo, 12 leitões da mesma raça, mesmo sexo, mesma idade e com pesos iniciais próximos. 1.1 Um exemplo. Uma bioquímica (Tecnologia de Alimentos) está interessada em estudar a extração de pigmentos naturais, com aplicação como corante em alimentos. Numa primeira etapa tem-se a necessidade de escolher o melhor solvente extrator. A escolha do(s) melhor(es) solventes foi realizada através da medida da absorbância de um pigmento natural do fruto de baguaçú. Fator = solventes; a=5 níveis; n=5 repetições.
. Aqui. assume-se que o delineamento é completamente casualizado. Estes experimentos só. podem ser realizados quando as unidades experimentais são homogêneas. Por. exemplo, 12 leitões da mesma raça, mesmo sexo, mesma idade e com pesos iniciais. próximos. 1.1 Um exemplo. Uma bioquímica (Tecnologia de Alimentos) está interessada em. estudar a extração de pigmentos naturais, com aplicação como corante em alimentos. Numa primeira etapa tem-se a necessidade de escolher o melhor solvente extrator. A escolha do(s) melhor(es) solventes foi realizada através da medida da absorbância. de um pigmento natural do fruto de baguaçú. Fator = solventes; a=5 níveis; n=5 repetições.")
2
As observações obtidas de absorbância são mostradas na tabela 1.1
Unidade experimental: 10 gramas de polpa do fruto de baguaçú. Casualização: a partir de 1 kg de polpa, foram sendo retiradas amostras de 10gr, onde foram aplicados os tratamentos, numa ordem aleatória. As observações obtidas de absorbância são mostradas na tabela 1.1 Tabela 1.1 Dados de absorbância de cada um dos solventes

3
Desenho esquemático para absorbância de cada solvente
Existe uma forte suspeita de que o tipo de solvente esteja afetando a absorbância. Distribuições assimétricas. Valor discrepante.

4
1-2 A Análise de Variância
Objetivo: testar se existe diferenças nas médias de absorbância para os a=5 tipos (níveis) de solventes.
 de solventes.")
5
Modelo estatístico (one-way):
i=1,2,...,a j=1,2,...,n yij= é a ij-ésima observação; é uma constante para todas as observações (média geral); i é o efeito do i-ésimo tratamento; ij é o erro aleatório(erros de medida, fatores não controláveis, diferenças entre as unidades experimentais, etc.). Pressuposições: 1) os erros aleatórios são independentes; 2) os erros aleatórios são normalmente distribuídos; 3) os erros aleatórios tem média 0 (zero) e variância 2; 4) a variância, 2, deve ser constante para todos os níveis do fator. 5) as observações são adequadamente descritas pelo modelo Ou, então:
; i é o efeito do i-ésimo tratamento; ij é o erro aleatório(erros de medida, fatores não controláveis, diferenças entre as unidades experimentais, etc.). Pressuposições: 1) os erros aleatórios são independentes; 2) os erros aleatórios são normalmente distribuídos; 3) os erros aleatórios tem média 0 (zero) e variância 2; 4) a variância, 2, deve ser constante para todos os níveis do fator. 5) as observações são adequadamente descritas pelo modelo. Ou, então:")
6
SSTotal = SSTratamentos + SSErro
Duas situações: 1) modelo de efeito fixo (níveis selecionados pelo pesquisador); 2) modelo de efeito aleatório (amostra aleatória). Neste caso, vamos estimar e testar hipóteses sobre a variabilidade de i 1-3 Análise de Variância do Modelo de Efeito Fixo Hipóteses: H0: 1= 2=...= a H1: i j para pelo menos um par (i,j) 1-3.1 Decomposição da soma de quadrados total Corrigida para a média SSTotal = SSTratamentos + SSErro
 modelo de efeito fixo (níveis selecionados pelo pesquisador); 2) modelo de efeito aleatório (amostra aleatória). Neste caso, vamos. estimar e testar hipóteses sobre a variabilidade de i. 1-3 Análise de Variância do Modelo de Efeito Fixo. Hipóteses: H0: 1= 2=...= a. H1: i j para pelo menos um par (i,j) Decomposição da soma de quadrados total. Corrigida para a média. SSTotal = SSTratamentos + SSErro.")
7
Considere a SQErro A parte dentro dos colchetes dividida por (n-1) é a variância do tratamento i. A variância combinada dos a tratamentos é: 7 7 7

8
Considere a SQTrat A parte dentro dos colchetes dividido por a-1 é a variância entre tratamentos. 8 8 8

9
Graus de liberdade: SSTotal tem an-1 graus de liberdade; SSTratamentos tem a-1 g.l. e SSerro tem a(n-1) g.l. Quadrados médios: Esperanças dos quadrados médios: Teste de hipótese:

10
1-3.2 Análise Estatística F0 = QMTratamentos / QMErro Critério para rejeição de H0: F0 > F,a-1,N-a . Pode-se usar o valor p (em inglês: p-value: É a probabilidade de rejeitar a hipótese nula devido a variações aleatórias. Exemplo: para = 5%, assim, se o valor p for menor do que 0,05 rejeitar H0, caso contrário, não rejeitar H0. Fórmulas operacionais para o cálculo das somas de quadrados:

11
Valor p N = an

12
Coeficiente de variação (CV)= 7,95%
Exemplo 1-1. O experimento de absorbância Coeficiente de variação (CV)= 7,95% F.05;4;20=2, F,01;4;20=4,43 Rejeita-se H0, e concluímos que as médias de tratamentos diferem entre si; os solventes afetam signifi- cativamente as médias de absorbância.
= 7,95% F.05;4;20=2,87 F,01;4;20=4,43. Rejeita-se H0, e concluímos que as médias de tratamentos diferem entre si; os solventes afetam signifi- cativamente as médias de absorbância.")
13
1-3.3 Estimação dos parâmetros do modelo
Estimativas da média geral e dos efeitos dos tratamentos: Estimativa pontual de i: dado i= + i, temos: Um intervalo de confiança para i é dado por:

14
Exemplo 1-3. Dados de absorbância
Intervalo de confiança para a diferença entre qualquer duas médias i-j: Exemplo 1-3. Dados de absorbância

15
Critério de rejeição de H0: i. -j. = 0
Critério de rejeição de H0: i.-j..= 0. Se o intervalo de confiança contém o valor da hipótese nula não se rejeita a hipótese de nulidade, caso contrário rejeita-se a hipótese. 1-3.4 Dados desbalanceados. O número de observações dentro de cada tratamento é diferente. Nesse caso, as SQTotal e SQTratamentos são dadas por:

16
1-4 Diagnóstico do Modelo
Verificar se as pressuposições básicas do modelo são válidas. Isso é realizado através de uma análise de resíduos. Define-se o resíduo da ij-ésima observação como: 1-4.1 A suposição de normalidade Vamos usar o gráfico normal de probabilidades: sob normalidade dos erros, estes devem seguir uma reta de 45o.

17
Alguns valores negativos dos resíduos(mais extremos) deveriam ser maiores; alguns valores positivos dos resíduos deveriam ser menores, com exceção do último valor que deveria ser maior. Contudo este gráfico não é grosseiramente não normal. Existe um resíduo que é muito maior que os demais, este valor é denominado outlier. É um problema sério. Deve-se fazer uma investigação sobre esse valor (erro de cálculo, digitação, algum fato experimental). Só eliminar um outlier se tiver uma justificativa não estatística, caso contrário, fazer duas análises: uma com e outra sem o outlier. Usar métodos não paramétricos. Transformação. Outlier: dij=eij/RQ(QMErro). Se algum resíduo padronizado for maior do que |3| ele é um outlier. Obs. RQ = raíz quadrada.
. Só eliminar um outlier se tiver uma justificativa não estatística, caso contrário, fazer duas análises: uma com e outra sem o outlier. Usar métodos não paramétricos. Transformação. Outlier: dij=eij/RQ(QMErro). Se algum resíduo padronizado for maior do que |3| ele é um outlier. Obs. RQ = raíz quadrada.")
18
1-4.2 Gráfico de resíduos no tempo
Para verificar se existe correlação entre os resíduos. Uma tendência de ter resíduos positivos e negativos indica uma correlação positiva. Isto implica que a suposição de independência dos erros foi violada. Isto é um problema sério, e até difícil de resolver. Se possível evitar este problema. A casualização adequada pode garantir a independência.

19
1-4.3 Gráfico dos resíduos versos valores preditos
A distribuição dos pontos é aleatória. Útil para verificar se as variâncias são heterogêneas (forma de megafone). Devido a presença de um outlier as variâncias não são homogêneas. Na presença de heterogeneidade de variâncias é usual aplicar uma transformação nos dados. Pode-se usar os testes não-paramétricos. A heterogeneidade de variância também ocorre nos casos de distribuições assimétricas, pois a variância tende a ser função da média.
. Devido a presença de um outlier as variâncias não são homogêneas. Na presença de heterogeneidade de variâncias é usual aplicar uma transformação nos dados. Pode-se usar os testes não-paramétricos. A heterogeneidade de variância também ocorre nos casos de distribuições assimétricas, pois a variância tende a ser função da média.")
20
Teste de Bartlett para igualdade de variâncias
Algumas transformações para homogeneizar as variâncias são dadas a seguir. As conclusões são realizadas para os dados transformados. Poisson: y*=y ou y*=1+y; dados de contagens, variância é função da média. Log normal: y*=log y; somente valores positivos, variável contínua com assimetria. Binomial: y*=arco seno y. dados na forma de proporções. Teste de Bartlett para igualdade de variâncias O teste estatístico é dado por: Onde:

21
é a variância amostral do i-ésimo tratamento.
Rejeita-se H0 quando Exemplo 1-4 Conclui-se que as 5 variâncias são iguais. Mesma conclusão com o uso do valor p (= 0,0691).
.")
22
Teste de Levene 1) Calcular os resíduos da análise de variância;
2) Fazer uma análise de variância dos valores absolutos desses resíduos; 3) Se as variâncias são homogêneas, o resultado do teste F será não significativo. Exemplo: dados de absorbância. Aceita-se a hipótese de que as variâncias são homogêneas
 Fazer uma análise de variância dos valores absolutos desses resíduos; 3) Se as variâncias são homogêneas, o resultado do teste F será não significativo. Exemplo: dados de absorbância. Aceita-se a hipótese de que as variâncias são homogêneas.")
23
1-4.4 Escolha da transformação para estabilizar a variância
Escolha empírica da transformação Em muitos experimentos onde há repetições, podemos estimar o parâmetro através da equação de regressão: Como e são desconhecidos, usamos as suas estimativas s e y(barra), esta é a média da amostra.
, esta é a média da amostra.")
24
Exemplo 1-5 (Arquivo: plasma.sas)
Um pesquisador está interessado em estudar a influência das idades de crianças doentes no nível de plasma, foram testadas 5 idades distintas, ou sejam, ID1= 0 ano, ID2=1 ano, ID3=2 anos, ID4=3 anos e ID5=4 anos. Os resultados de nível de plasma foram:

25
O teste F da ANAVA indica que as 5 médias de níveis de plasma diferem significativamente entre si. O gráfico dos resíduos indica heterogeneidade de variâncias.

26
Para estudar a possibilidade de uma transformação nos dados, plotamos log do desvio padrão versus log da média. A equação de uma regressão linear simples para os dados é dada por:

27
Como o coeficiente angular é próximo de 1,5 e, de acordo com a tabela, podemos usar a transformação INVERSO DA RAÍZ QUADRADA.

28
Normalidade: de acordo com o gráfico abaixo podemos considerar que os dados seguem uma distribuição normal.

29
Transformação: logarítmica (base 10).
.")
30
1-4.5 Gráfico dos resíduos versus outras variáveis
Se a distribuição dos pontos no gráfico mostrar algum padrão (tendência, isto é, se os pontos não estão distribuídos aleatoriamente no gráfico) a variável afeta a resposta, assim, esta variável deve ser melhor controlada ou incluída na análise. Por exemplo, as análises foram feitas com dois espectrofotômetros.
 a variável afeta a resposta, assim, esta variável deve ser melhor controlada ou incluída na análise. Por exemplo, as análises foram feitas com dois espectrofotômetros.")
31
Dois espectrofotômetros

32
1-5 Interpretando os resultados
1-5.1 Comparações entre médias de tratamentos (Fatores qualitativos) Quando o teste F da análise de variância for significativo, indica que existe diferenças entre as médias reais de tratamentos. Entre quais médias ou grupos? 1-5.2 Contrastes Desejamos verificar se a médias dos solventes E50, EAW e E70 não diferem da média dos solventes MAW e MM. Esta hipótese é escrita como: Temos o contraste: A soma de quadrados é dada por: Com 1 grau de liberdade (sempre).
 Quando o teste F da análise de variância for significativo, indica que existe diferenças entre as médias reais de tratamentos. Entre quais médias ou grupos Contrastes. Desejamos verificar se a médias dos solventes E50, EAW e E70 não diferem da média dos solventes MAW e MM. Esta hipótese é escrita como: Temos o contraste: A soma de quadrados é dada por: Com 1 grau de liberdade (sempre).")
33
1-5.3 Contrastes Ortogonais
Se o delineamento é desbalanceado então: TESTE: SQc/QMErro. Vamos obter uma estatística F com 1 e N-a graus de liberdade. 1-5.3 Contrastes Ortogonais Dois contrastes com coeficientes ci e di são ortogonais se: Exemplo: vamos considerar um experimento com 3 tratamentos (a=3), sendo um deles o controle. ortogonais
, sendo um deles o controle. ortogonais.")
34
Os contrastes devem ser escolhidos antes de realizar o experimento.
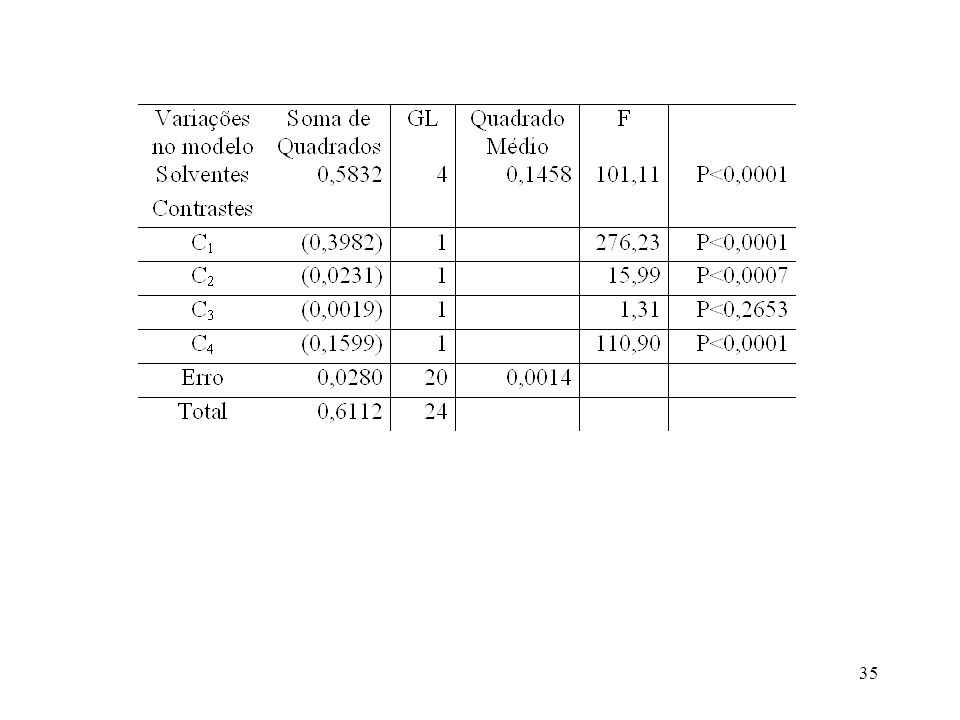
Para a tratamentos podemos ter a-1 contrastes ortogonais; podemos ter vários conjuntos de a-1 contrastes ortogonais. Exemplo: dados de absorbância. Temos 5 médias de tratamentos e, portanto, g.l. 4 contrastes ortogonais. Contrastes C1=2y1.+2y2.-3y3.+2y4.-3y5. C2= y1.+ y y4. C3= y1.- y2. C4= y y5. Hipóteses: C1=7,7286; C2=-0,8316; C3=-0,1376; C4=1,2644 SQC1=0,3982; SQC2=0,0231; SQC3=0,0019; SQC4=0,1599

36
1-5.4 Método de Scheffé para comparação de contrastes
1 - Não sabe a priori quais contrastes comparar 2 - Deseja comparar mais do que a-1 contrastes Considere m contrastes de médias: A estimativa do contraste é dado por: O erro padrão do contraste é dado por:

37
Critério do teste: o valor com o qual Cu deve ser comparado é dado por:
Se |Cu| S,u, então rejeita-se a hipótese de que o contraste u é igual a zero. Exemplo 1-1. Dados de absorbância. Considere os 2 contrastes de interesse As estimativas desses contrastes são:

38
Erros padrões dos contrastes:
Os valores críticos ( = 0,01) são dados por: Como |C1| S0,01;1 conclui-se que o contraste C1 é diferente de zero, isto é, os tratamentos E50, EAW e E70 em média diferem dos tratamentos MAW e M1M. Como |C2| S0,01;2 conclui-se que o contraste C2 é igual a zero, portanto, os tratamentos E50 e EAW, em média, não diferem do tratamento E70.
 são dados por: Como |C1| S0,01;1 conclui-se que o contraste C1 é diferente de zero, isto é, os tratamentos E50, EAW e E70 em média diferem dos tratamentos MAW e M1M. Como |C2| S0,01;2 conclui-se que o contraste C2 é igual a zero, portanto, os tratamentos E50 e EAW, em média, não diferem do tratamento E70.")
39
1-5.5 Comparações entre Pares de Médias
Hipótese: Número de comparações: a(a-1)/2. Devem ser realizadas após o teste F da análise de variância rejeitar a hipótese nula Método da Diferença Mínima Significativa (LSD) A estatística a ser utilizada é dada por: Para um teste bilateral, o par de médias, i e j, é significativamente diferente se: LSD
/2. Devem ser realizadas após o teste F da análise de variância rejeitar a hipótese nula. Método da Diferença Mínima Significativa (LSD) A estatística a ser utilizada é dada por: Para um teste bilateral, o par de médias, i e j, é significativamente diferente se: LSD.")
40
* diferença significativa para =5%.
Critério do teste: se concluímos que o par de médias i e j, difere significativamente. Exemplo: dados de absorbância. Para =0,05, o valor da LSD é: * diferença significativa para =5%.

41
Teste de Tukey Duas médias são diferentes significativamente se a diferença das médias amostrais (em valor absoluto) for superior a DMS (Diferença Mínima Significativa): Onde q é um apropriado nível de confiança superior da amplitude studentizada para k médias (tratamentos) e f graus de liberdade associados a estimativa s2 de 2 (QMErro). Exemplo: dados de absorbância. O valor da Diferença Mínima Significativa é: Conclusão: pelo teste de Tukey, ao nível de significância de 5%, as médias dos tratamentos E50 e EAW, assim como as médias dos tratamentos EAW e E70 não apresentam diferenças significantes. As médias dos tratamentos E50 e E70 apresentam diferença significante.
 for superior a DMS (Diferença Mínima Significativa): Onde q é um apropriado nível de confiança superior da amplitude studentizada para k médias (tratamentos) e f graus de liberdade associados a estimativa s2 de 2 (QMErro). Exemplo: dados de absorbância. O valor da Diferença Mínima Significativa é: Conclusão: pelo teste de Tukey, ao nível de significância de 5%, as médias dos tratamentos E50 e EAW, assim como as médias dos tratamentos EAW e E70 não apresentam diferenças significantes. As médias dos tratamentos E50 e E70 apresentam diferença significante.")
42
E70 = 0, A EAW = 0, A B E50 = 0, B MAW = 0, C M1M = 0, D Médias seguidas de mesma letra, em uma mesma coluna, não apresentam diferenças significantes, ao nível de significância de 5%, pelo teste de Tukey.

43
Teste de Dunnett: comparação com um controle
Interesse é comparar cada uma das a-1 médias com a média do tratamento controle, assim temos a-1 comparações. Deseja-se testar a hipótese: Onde a é a média do tratamento controle. A hipótese de nulidade é rejeitada, ao nível de significância , se Exemplo: dados de absorbância. Considere o tratamento M1M como sendo o controle. Neste exemplo, a=5, a-1=4 e f=20 e ni=na=5. Para =5%, da tabela (valores críticos do teste de Dunnett) obtemos d0,05(4;20)=2,65. Assim, o valor crítico é dado por:
 obtemos d0,05(4;20)=2,65. Assim, o valor crítico é dado por:")
44
Conclusão: todas as médias diferem significativamente da média do tratamento controle.
Qual teste usar? O LSD é eficiente para detectar diferenças verdadeiras nas médias se ele for aplicado apenas depois do teste F da ANOVA se significativo a 5%. Idem para o Duncan. Estes métodos não contém o erro tipo I (erro geral ou experimentwise error). Como o Tukey controla este erro ele é o preferido pelos estatísticos. O SNK é mais conservador do que o Duncan.
. Como o Tukey controla este erro ele é o preferido pelos estatísticos. O SNK é mais conservador do que o Duncan.")
45
1-5.6 Modelo de Regressão Doses de fósforo Observações Totais Médias
Fator quantitativo: interesse em encontrar uma equação de regressão que leva em conta toda a faixa de valores análise de regressão Exemplo: produção de milho em kg/parcela. Doses de fósforo Observações Totais Médias 0 kg/ha 2,38 6,77 3,50 5,94 18,59 4,65 25 kg/ha 6,15 8,78 8,99 9,10 33,02 8,26 50 kg/ha 9,07 8,73 6,92 8,48 33,20 8,30 Desvio Padrão 2,05 1,40 0,95 0,69 75 kg/ha 9,55 8,95 10,24 8,66 37,40 9,35 0,40 100 kg/ha 9,14 10,17 9,75 9,50 38,56 9,64

46
Os traços no gráfico representam os valores médios para cada uma das doses.
Pelo gráfico de dispersão, verifica-se claramente que a relação não é linear. Podemos ajustar um polinômio de 20 grau para representar este relacionamento, isto é, Onde 0, 1 e 2 são parâmetros desconhecidos e que devem ser estimados e é o erro aleatório. Para o exemplo a equação ajustada é dada por: . R2=66,9%66,9 % da variabilidade dos dados é explicada pelo modelo quadrático.

47
- Estimar a produção média de milho para
doses dentro da região de experimentação; -Otimização. Estimação: X=90 Ŷ=9, ,6E(Y)10,5 Otimização:
10,5. Otimização:")
48
1-6 Modelo de Efeito Aleatório
Se o pesquisador seleciona aleatoriamente a níveis de um fator de uma população de níveis desse fator, então o fator é dito aleatório. A inferência é feita para toda a população de níveis. Exemplo: uma pesquisadora estudou o conteúdo de sódio em cervejas selecionando aleatoriamente 6 marcas de um grande número de marcas dos EUA e do Canadá. Ela, então, escolheu 8 garrafas de cada marca aleatoriamente de supermercados e mediu a quantidade de sódio (em miligramas) de cada garrafa.
 de cada garrafa.")
49
O modelo estatístico: i é o efeito do i-ésimo tratamento e assume-se que seja NID(0,2) ij é o erro aleatório e assume-se que sejam NID(0, 2) i e ij são independentes Testar hipóteses sobre os efeitos dos tratamentos não faz sentido, assim, vamos testar as hipóteses sobre a variância dos tratamentos.

50
Se 2=0, então todos os tratamentos são idênticos; mas se 2>0 a variabilidade entre tratamentos é significativa. Quando temos um modelo de efeitos aleatórios o interesse está em estimarmos os componentes de variâncias: 2 e 2. Prova-se que: Portanto,

51
Exemplo: Dados de sódio
Exemplo: Dados de sódio. Os resultados da análise de variância são mostrados na tabela abaixo - Arquivo: conteudodesoddiocervejas.sas Conclusão: rejeita-se H0: Os componentes de variância são estimados por: Um uso importante: isolar diferentes fontes de variabilidade que afetam um produto ou um sistema. Identificar fatores com maior variabilidade (Exemplo: Lotes, amostras e réplicas).
.")
52
2- Mais Sobre Experimentos com Um Fator
2-1 Escolha do Tamanho da Amostra 2-1.1 Curvas Características de Operação Curva característica de operação: é um gráfico em que no eixo das ordenadas temos a probabilidade de erro tipo II (aceitar a hipótese de nulidade quando na verdade deveríamos ter rejeitado) e no eixo das abcissas temos a precisão desejada pelo pesquisador. Probabilidade de erro tipo II para o modelo de efeito fixo e igual tamanho de amostra por tratamento. As CCO dadas no ábaco V (Apêndice), são usadas para avaliar o valor de . Essas CCO são um gráfico de (ordenadas) versus (abcissas), onde:
 e no eixo das abcissas temos a precisão desejada pelo pesquisador. Probabilidade de erro tipo II para o modelo de efeito fixo e igual tamanho de amostra por tratamento. As CCO dadas no ábaco V (Apêndice), são usadas para avaliar o valor de . Essas CCO são um gráfico de (ordenadas) versus (abcissas), onde:")
53
O cálculo de apresenta algumas dificuldades práticas:
2) necessita-se de uma estimativa de 2 (experiência, um experimento piloto, bibliografia) Exemplo: dados de absorbância. Suponha que a pesquisadora deseja rejeitar a hipótese nula com pelo menos 90% de probabilidade(1-=90%) se as 5 médias dos trat/os são: Ela deseja usar =0,05, e neste caso a média geral vale 0,52. Assim, De um ensaio preliminar encontramos 2=0,06.
 necessita-se de uma estimativa de 2 (experiência, um experimento piloto, bibliografia) Exemplo: dados de absorbância. Suponha que a pesquisadora deseja rejeitar a hipótese nula com pelo menos 90% de probabilidade(1-=90%) se as 5 médias dos trat/os são: Ela deseja usar =0,05, e neste caso a média geral vale 0,52. Assim, De um ensaio preliminar encontramos 2=0,06.")
54
Temos: Assim, a pesquisadora deve utilizar n=5 repetições para realizar o teste com o poder desejado. Alternativa: é selecionar um tamanho de amostra tal que, se a diferença entre qualquer duas médias exceder um valor especificado, a hipótese de nulidade deve ser rejeitada. Seja D este valor (precisão), então: Exemplo: dados de absorbância: suponha que a pesquisadora deseja rejeitar a hipótese de nulidade com probabilidade igual a 0,90 (Poder do teste (1-)) se a diferença entre qualquer duas médias for igual a 0,30. Considere uma estimativa para 2=0,015, portanto, = 0,1225.
, então: Exemplo: dados de absorbância: suponha que a pesquisadora deseja rejeitar a hipótese de nulidade com probabilidade igual a 0,90 (Poder do teste (1-)) se a diferença entre qualquer duas médias for igual a 0,30. Considere uma estimativa para 2=0,015, portanto, = 0,1225.")
55
Conclui-se que n=7 repetições devem ser usadas para ter a precisão e confiança desejadas.
Modelo de efeitos aleatórios: a probabilidade de erro tipo II para esse caso é: As CCO (Ábaco VI, Apêndice) são gráficos onde na ordenada temos a probabilidade de erro tipo II e na a abcissa temos , onde é dado por:
 são gráficos onde na ordenada temos a probabilidade de erro tipo II e na a abcissa temos , onde é dado por:")
56
2 : quanto da variabilidade na população dos tratamentos deseja-se detectar;
2 : pode ser obtido através de algum experimento ou experiência anterior, bibliografia. Exemplo: conteúdo de sódio. O pesquisador deseja rejeitar a hipótese de nulidade com 99% de probabilidade se 2 =10. De um experimento anterior sabe-se que 2 =1,0. Método do Intervalo de Confiança Assume-se que o pesquisador deseja expressar os resultados em termos de intervalos de confiança dos efeitos dos tratamentos. Especifica à priori a amplitude dos mesmos.

57
A semi-amplitude do intervalo de confiança (precisão que o pesquisador deseja, isto é, a diferença entre a média obtida no experimento e a média verdadeira) ) é dada por: Exemplo: dados de absorbância: o pesquisador deseja construir com confiança de 95%, um intervalo com semi-amplitude de 0,15. Considere 2=0,015. Para n=5 repetições, a semi-amplitude do intervalo de confiança é dada por: O qual apresenta uma precisão menor do que a desejada, portanto, vamos aumentar o tamanho da amostra. Para n=6 repetições, temos: Para n=6 repetições encontramos a precisão desejada.

58
2-2 Encontrando efeitos de dispersão
O interesse é descobrir se os diferentes níveis do fator afetam a variabilidade efeitos de dispersão. Neste caso, a variável resposta a ser utilizada será a variância, desvio padrão ou outra medida de variabilidade. Exemplo. Na fabricação de pão utiliza-se farinha de trigo e de um número menor de outros ingredientes permitidos (fatores em estudo). O objetivo de um programa de qualidade foi a de identificar uma combinação desses ingredientes os quais produzem um alto volume específico de pão e que seja tolerante a flutuações no processo de fabricação. Para esse fim, foi realizado um experimento com 4 formulações (1, 2, 3 e 4), sendo a última uma formulação padrão. Os dados médios de volume específico e desvio padrão estão na tabela a seguir.
. O objetivo de um programa de qualidade foi a de identificar uma combinação desses ingredientes os quais produzem um alto volume específico de pão e que seja tolerante a flutuações no processo de fabricação. Para esse fim, foi realizado um experimento com 4 formulações (1, 2, 3 e 4), sendo a última uma formulação padrão. Os dados médios de volume específico e desvio padrão estão na tabela a seguir.")
59
O teste F da ANOVA para os valores médios de volume específico de pão não foi significativo(F=0,2667 e valor do nível descritivo igual a 0,8482), indicando que não existe diferenças entre as 4 formulações. Para investigar possíveis efeitos de dispersão, usualmente utiliza-se LN(s),como sendo a variável resposta (a transformação logarítmica estabiliza a variância). Os resultados da ANOVA estão na tabela a seguir. Observa-se que as formulações afetam o desvio padrão do volume específico do pão, isto é, as formulações tem um efeito de dispersão.
,como sendo a variável resposta (a transformação logarítmica estabiliza a variância). Os resultados da ANOVA estão na tabela a seguir. Observa-se que as formulações afetam o desvio padrão do volume específico do pão, isto é, as formulações tem um efeito de dispersão.")
60
2-3 Ajustando curvas de respostas
LSD test; variable LNDESPAD (volumpao.sta) Probabilities for Post Hoc Tests MAIN EFFECT: VAR1 {1} {2} {3} {4} 3, , , ,582091 1 {1} , , ,526936 2 {2} , , ,006118 3 {3} , , ,793393 4 {4} , ,0, ,793393 Dos resultados do teste LSD, conclui-se que a formulação 2 produz menos dispersão do que as demais; As formulações 1, 3 e 4, são estatisticamente equivalentes. 2-3 Ajustando curvas de respostas Quando os níveis do fator são quantitativos, podemos realizar uma regressão polinomial. Duas etapas: 1) desdobramento dos graus de liberdade de tratamentos (a-1),em regressão linear, quadrática, cúbica, 4 grau, e assim por diante. Geralmente ajusta-se uma regressão quadrática. 2) obter a equação de regressão.
 Probabilities for Post Hoc Tests. MAIN EFFECT: VAR1. {1} {2} {3} {4} 3, , , , {1} , , , {2} , , , {3} , , , {4} , ,0, , Dos resultados do teste LSD, conclui-se que a formulação 2 produz menos dispersão do que as demais; As formulações 1, 3 e 4, são estatisticamente equivalentes. 2-3 Ajustando curvas de respostas. Quando os níveis do fator são quantitativos, podemos realizar uma regressão polinomial. Duas etapas: 1) desdobramento dos graus de liberdade de tratamentos (a-1),em regressão linear, quadrática, cúbica, 4 grau, e assim por diante. Geralmente ajusta-se uma regressão quadrática. 2) obter a equação de regressão.")
61
Exemplo: produção de milho, em kg/unidade experimental.
44,32 -22,52 11,21 -25,33 Efeito: Soma de quadrados: 49,11 9,06 3,14 2,29

62
O novo quadro da ANOVA fica:
Observamos que o efeito quadrático foi significativo, o efeito cúbico e 4. grau não foram significativos, portanto, vamos ajustar um polinômio de segunda ordem aos dados, dado por: Onde Pu(x) é um polinômio de u-ésima ordem.. Os 3 primeiros polinômios ortogonais são:
 é um polinômio de u-ésima ordem.. Os 3 primeiros polinômios ortogonais são:")
63
Onde d é a distância entre dois níveis de x, a é o total de níveis, e i são constantes obtidas em tabelas. As estimativas de mínimos quadrados dos parâmetros no modelo polinomial ortogonal são:

64
Para os dados de adubação em milho, as estimativas dos parâmetros do modelo são:

65
2-4 Métodos não paramétricos na análise de variância
A equação de regressão é dada por: (R2 = 66,9%) 2-4 Métodos não paramétricos na análise de variância 2-4.1 O Teste de Kruskal-Wallis Quando as pressuposições básicas da ANOVA não forem atendidas, por exemplo, a variável em estudo não apresenta distribuição normal (notas em escala), heterogeneidade de variâncias, outliers. É usado para testar a hipótese de que a tratamentos são idênticos contra a hipótese alternativa de que pelo menos dois deles diferem entre si.
 2-4 Métodos não paramétricos na análise de variância O Teste de Kruskal-Wallis. Quando as pressuposições básicas da ANOVA não forem atendidas, por exemplo, a variável em estudo não apresenta distribuição normal (notas em escala), heterogeneidade de variâncias, outliers. É usado para testar a hipótese de que a tratamentos são idênticos contra a hipótese alternativa de que pelo menos dois deles diferem entre si.")
66
Pressuposições: 1) as observações são todas independentes.
2) as a populações são aproximadamente da mesma forma e contínuas (pode ser abrandada, desde que consigamos ordenar os dados, exemplo, escala ordinal). Hipóteses: Método: procedemos a classificação conjunta (em ordem crescente) das N observações, dando ordem 1 à menor e ordem N à maior delas, e substituímos às observações pelos seus postos (ranks). No caso de empates (observações com o mesmo valor), designa-se o posto médio para as observações empatadas. Seja Ri a somas dos ranks do i-ésimo tratamento. O teste estatístico é dado por: ni é o número de observações do i-ésimo tratamento e N é o número total de observações.
 as a populações são aproximadamente da mesma forma e contínuas. (pode ser abrandada, desde que consigamos ordenar os dados, exemplo, escala ordinal). Hipóteses: Método: procedemos a classificação conjunta (em ordem crescente) das N observações, dando ordem 1 à menor e ordem N à maior delas, e substituímos às observações pelos seus postos (ranks). No caso de empates (observações com o mesmo valor), designa-se o posto médio para as observações empatadas. Seja Ri a somas dos ranks do i-ésimo tratamento. O teste estatístico é dado por: ni é o número de observações do i-ésimo tratamento e N é o número total de observações.")
67
Sem empates: E o teste estatístico simplifica-se: Critério do teste: para ni5, H tem distribuição aproximada de 2a-1 sob H0.. Assim, se Olhar o valor p rejeita-se H0. Exemplo: dados de absorbância.

68
O valor p para H=22,3987 com 4 g.l. é 0,0002, portanto, rejeita-se H0.
* Teste de comparação de médias não paramétrico.

69
2-5 Medidas Repetidas É preciso levar em consideração duas fontes de variabilidade: entre unidades e dentro de unidades (between subjects and within subjects). SUBJECTS=JULGADORES.. Cada degustador usa os a tratamentosdelineamento com medidas repetidas. A tabela geral dos dados para este delineamento é dada como:
. SUBJECTS=JULGADORES.. Cada degustador usa os a tratamentosdelineamento com medidas repetidas. A tabela geral dos dados para este delineamento é dada como:")
70
O modelo estatístico: Onde i é o efeito do i-ésimo tratamento e j é o efeito da j-ésima unidade. Assume-se que: tratamentos de efeito fixo e subjects de efeito aleatório (Modelo Misto). Partição da soma de quadrados total: S.Q. Total = S.Q Entre julgadores + S.Q.Dentro julgadores
. Partição da soma de quadrados total: S.Q. Total = S.Q Entre julgadores + S.Q.Dentro julgadores.")
71
Graus de liberdade: na-1 = (n-1) + n(a-1)
S.Q. Dentro de julgadores = S.Q.Tratamentos + S.Q. Erro Graus de liberdade: n(a-1) = (a-1) + (a-1)(n-1) Hipóteses: Critério do teste: Rejeita-se H0 se:
 = (a-1) + (a-1)(n-1) Hipóteses: Critério do teste: Rejeita-se H0 se:")
72
Exemplo: hamburger de pescado, variável sabor.
Teste para julgadores: Portanto, rejeita-se H0, isto é, o comportamento dos julgadores não é o mesmo, não são equivalentes.

73
2-6 Análise de Covariância
Intervalos de confiança: 2-6 Análise de Covariância É utilizada para melhorar a precisão (fazer um ajuste) na comparação entre os tratamentos do experimento. Suponha um experimento que junto com uma variável resposta Y (população de staphilococus), tenha uma variável X (população inicial de staphilococus), e que Y e X estejam relacionadas linearmente. Além disso, suponha que X não pode ser controlada pelo pesquisador, mas pode ser observada junto com Y. A variável X é chamada covariável. A ANCOVA é um ajuste da variável resposta para os efeitos de uma variável perturbadora (nuisance variable). Se este ajuste não for feito, a covariável pode inflacionar o quadrado médio do erro e fazer com que diferenças reais entre os tratamentos sejam difíceis de serem detectadas. A covariável, X, não deve ser afetada pelos tratamentos. Por exemplo, experimento com tratamento de sementes, Y = produção da cultura e X = stand inicial (plantas que germinaram). Observação: A blocagem pode ser usada para eliminar o efeito de variáveis perturbadoras que podem ser controladas pelo pesquisador.
 na comparação entre os tratamentos do experimento. Suponha um experimento que junto com uma variável resposta Y (população de staphilococus), tenha uma variável X (população inicial de staphilococus), e que Y e X estejam relacionadas linearmente. Além disso, suponha que X não pode ser controlada pelo pesquisador, mas pode ser observada junto com Y. A variável X é chamada covariável. A ANCOVA é um ajuste da variável resposta para os efeitos de uma variável perturbadora (nuisance variable). Se este ajuste não for feito, a covariável pode inflacionar o quadrado médio do erro e fazer com que diferenças reais entre os tratamentos sejam difíceis de serem detectadas. A covariável, X, não deve ser afetada pelos tratamentos. Por exemplo, experimento com tratamento de sementes, Y = produção da cultura e X = stand inicial (plantas que germinaram). Observação: A blocagem pode ser usada para eliminar o efeito de variáveis perturbadoras que podem ser controladas pelo pesquisador.")
74
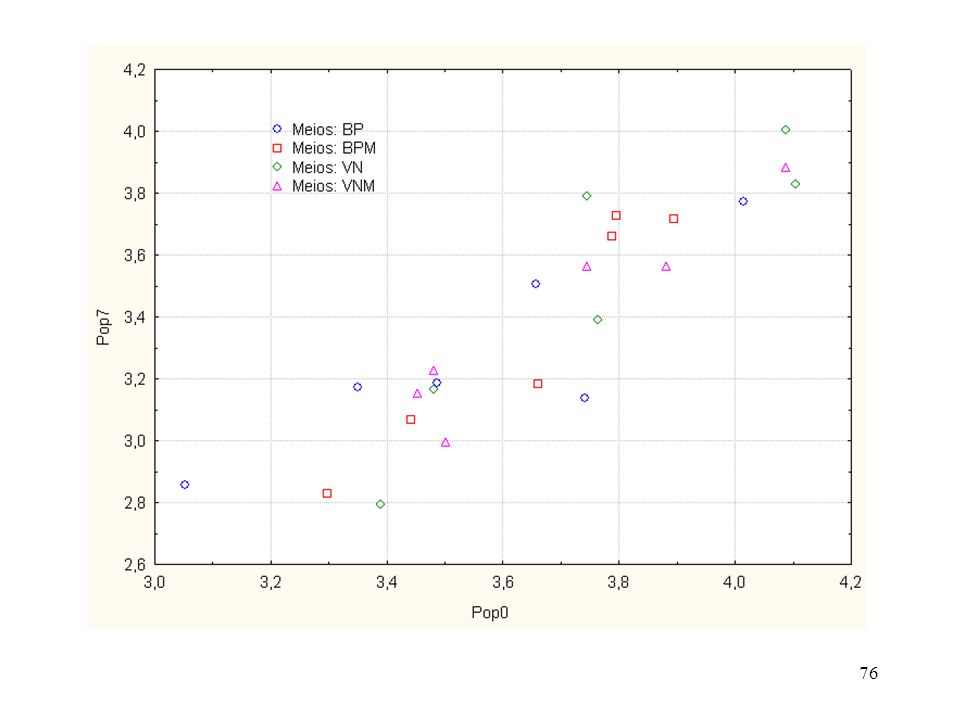
Exemplo: dados de população de Staphilococus aureus, em frango, mantidos sob refrigeração doméstica (-18 graus). O objetivo do experimento é comparar meios de cultura, quais sejam: Baird Paker, Baird Paker Modificado, Vermelho Neutro e Vermelho Neutro Modificado com relação à variável sobrevivência de Staphilococus aos 7 dias de armazenamento. Os dados são mostradas na tabela a seguir. Vamos considerar que são os mesmos frangos medidos no tempo 0 e tempo 7 dias.

75
Médias: Resultados da ANOVA.

77
A figura mostra um tendência linear entre y = pop7 e x = pop0, isto é, a população aos 7 dias é afetada pela população inicial (0 dia).
.")
78
2-6.1 Descrição do procedimento
Modelo estatístico (1): para i=1,2,...,a e j=1,2,...,n. Yij é a j-ésima observação da v. resposta tomada no i-ésimo tratamento; xij é a medida feita na covariável correspondente a yij; é a média dos valores de xij, é a média geral; i é o efeito do i-ésimo trat/o; é o coeficiente angular da regressão linear entre X e Y e ij é o erro aleatório.
: para i=1,2,...,a e j=1,2,...,n. Yij é a j-ésima observação da v. resposta tomada no i-ésimo tratamento; xij é a medida feita na covariável correspondente a yij; é a média dos valores de xij, é a média geral; i é o efeito do i-ésimo trat/o; é o coeficiente angular da regressão linear entre X e Y e ij é o erro aleatório.")
79
Suposição:

80
Para descrever a análise utiliza-se a notação:

81
Somas de quadrados: Graus de liberdade: Regressão: 1 Tratamentos(ajustado): a-1 Erro: a(n-1)-1 Total: na-1 Teste da hipótese: ou Rejeita-se H0 se: Use o valor p

82
Deve-se ajustar as médias: médias de mínimos quadrados
Erro padrão de qualquer média ajustada de tratamento: Hipótese: Rejeita-se H0 se: Use o valor p

83
Exemplo: dados de população de Staphilococus
Exemplo: dados de população de Staphilococus. (Arquivo: staplilocousanalisedecovariancia) Não podemos rejeitar a hipótese H0:i=0, isto é, os valores médios dos meios são estatisticamente equivalentes, com valor p de 0,9739. Rejeita-se a hipótese H0:=0, com valor p < 0,0001, isto significa que foi importante remover o efeito da população inicial de Staphilococus. Os valores das médias ajustadas com os seus erros padrões são:
 Não podemos rejeitar a hipótese H0:i=0, isto é, os valores médios dos meios são estatisticamente equivalentes, com valor p de 0,9739. Rejeita-se a hipótese H0:=0, com valor p < 0,0001, isto significa que foi importante remover o efeito da população inicial de Staphilococus. Os valores das médias ajustadas com os seus erros padrões são:")
84
A estimativa do coeficiente de regressão é:
Diagnóstico do modelo: os resíduos são dados por: Exemplo: e11=3,1710-3,2718-1,2066(3,3507-3,55033) = 0,140074 Os resíduos estão aleatoriamente distribuídos em torno do valor zero. A faixa de distribuição, -0,5 a 0,5, é curta; não tem outliers. Variâncias homogêneas.
 = 0, Os resíduos estão aleatoriamente distribuídos em torno do valor zero. A faixa de distribuição, -0,5 a 0,5, é curta; não tem outliers. Variâncias homogêneas.")
85
A suposição de normalidade é satisfeita.

86
Valores aleatoriamente distribuídos em torno de zero.
Conclusão: de acordo com os gráficos, os resultados da análise estatística podem ser utilizados, pois eles não revelam qualquer problema quanto as suposições do modelo.

87
2-6.2 Comparações entre Pares de Médias Ajustadas
Hipótese: Número de comparações: a(a-1)/2. Devem ser realizadas após o teste F da análise de variância rejeitar a hipótese nula Método da Diferença Mínima Significativa (LSD) Para um teste bilateral, o par de médias, i e j, é significativamente diferente se: LSD Onde t é um valor da distribuição t de Student com N-a-1 graus de liberdade e nível de significância .
/2. Devem ser realizadas após o teste F da análise de variância rejeitar a hipótese nula. Método da Diferença Mínima Significativa (LSD) Para um teste bilateral, o par de médias, i e j, é significativamente diferente se: LSD. Onde t é um valor da distribuição t de Student com N-a-1 graus de liberdade e nível de significância .")
88
Comparando a média ajustada de BP com a média ajustada de BPM
Portanto, as médias não apresentam diferença significante ao nível de significância de 5%.

Apresentações semelhantes









. Nenhuns direitos reservados, excepto para fins comerciais. Por favor, não coloque.>")









