Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Análise Exploratória de Dados R – 03 de junho de 2008

2
Objetivos representar graficamente as duas variáveis combinadas; definir e calcular uma medida de associação entre as variáveis. Análise bivariada: uma variável qualitativa e uma quantitativa :

3
Exemplo 1 Os dados referem-se ao exemplo 2.1 do livro-texto (Bussab e Morettin, pag. 11) Arquivo: ciaMB.txt Conteúdo: informações sobre estado civil, grau de instrução, número de filhos, salário (expresso como fração do salário mínimo), idade (medida em anos e meses) e procedência de 36 empregados da seção de orçamentos da Companhia MB.
 Arquivo: ciaMB.txt Conteúdo: informações sobre estado civil, grau de instrução, número de filhos, salário (expresso como fração do salário mínimo), idade (medida em anos e meses) e procedência de 36 empregados da seção de orçamentos da Companhia MB..")
4
Exemplo 1: nomes das variáveis no arquivo ecivil: variável nominal cujos níveis são solteiro ou casado. instrucao: variável ordinal cujos níveis são F(Ensino Fundamental), M(Ensino Médio) e S(Ensino Superior). nfilhos: número de filhos (apenas para os funcionários casados), entre os solteiros a informação está como NA.
, M(Ensino Médio) e S(Ensino Superior). nfilhos: número de filhos (apenas para os funcionários casados), entre os solteiros a informação está como NA..")
5
Exemplo 1: nomes das variáveis no arquivo sal: salário expresso como fração do salário mínimo idadea: idade em anos completos idadem: meses rp: região de procedência (interior, capital e outros).
.")
6
Exemplo 1:salário versus nível de instrução Suponha que estejamos interessados em analisar o comportamento dos salários dentro de cada nível de instrução, ou seja, investigar o comportamento conjunto das variáveis sal e instrucao. Para facilitar, vamos primeiro ordenar os dados numa nova base (dadosord) pela variável instrução.
 pela variável instrução..")
7
Ordenando por instrução dados=read.table(“http://www.im.ufrj.br/~flavia/aed06/ciaMB.txt”,header=T) indice=order(dados$instrucao) dadosord=dados[indice,] table(dados$instrucao) F M S 12 18 6 Logo, em dadosord as observações de 1 a 12 são de empregados com Ensino Fundamental, de 13 a 30 com Ensino Médio e de 31 a 36 com Ensino Superior.
![Ordenando por instrução dados=read.table( ,header=T) indice=order(dados$instrucao) dadosord=dados[indice,] table(dados$instrucao) F M S Logo, em dadosord as observações de 1 a 12 são de empregados com Ensino Fundamental, de 13 a 30 com Ensino Médio e de 31 a 36 com Ensino Superior.](http://images.slideplayer.com.br/17/5322049/slides/slide_7.jpg "Ordenando por instrução dados=read.table( ,header=T) indice=order(dados$instrucao) dadosord=dados[indice,] table(dados$instrucao) F M S Logo, em dadosord as observações de 1 a 12 são de empregados com Ensino Fundamental, de 13 a 30 com Ensino Médio e de 31 a 36 com Ensino Superior.")
8
ecivil instrucao filhos sal idadea idadem rp 1 solteiro F NA 4.00 26 3 interior 2 casado F 1 4.56 32 10 capital 3 casado F 2 5.25 36 5 capital 5 solteiro F NA 6.26 40 7 outra 6 casado F 0 6.66 28 0 interior 7 solteiro F NA 6.86 41 0 interior 8 solteiro F NA 7.39 43 4 capital 12 solteiro F NA 8.46 27 11 capital 14 casado F 3 8.95 44 2 outra 18 casado F 2 9.80 39 7 outra 23 solteiro F NA 12.00 41 0 outra 27 solteiro F NA 13.85 46 7 outra 4 solteiro M NA 5.73 20 10 outra 9 casado M 1 7.59 34 10 capital 10 solteiro M NA 7.44 23 6 outra 11 casado M 2 8.12 33 6 interior 13 solteiro M NA 8.74 37 5 outra 15 casado M 0 9.13 30 5 interior 16 solteiro M NA 9.35 38 8 outra 17 casado M 1 9.77 31 7 capital 20 solteiro M NA 10.76 37 4 interior 21 casado M 1 11.06 30 9 outra 22 solteiro M NA 11.59 34 2 capital 25 casado M 2 13.23 32 5 interior 26 casado M 2 13.60 35 0 outra 28 casado M 0 14.69 29 8 interior 29 casado M 5 14.71 40 6 interior 30 casado M 2 15.99 35 10 capital 32 casado M 1 16.61 36 4 interior 35 casado M 2 19.40 48 11 capital 19 solteiro S NA 10.53 25 8 interior 24 casado S 0 12.79 26 1 outra 31 solteiro S NA 16.22 31 5 outra 33 casado S 3 17.26 43 7 capital 34 solteiro S NA 18.75 33 7 capital 36 casado S 3 23.30 42 0 interior dadosord observações de 1 a 12 em dadosord observações de 13 a 30 em dadosord observações de 31 a 36 em dadosord

9
Medidas resumo por nível de instrução Vamos começar descrevendo o comportamento dos salários por nível de instrução, a partir das estatísticas resumo dentro de cada nível. sink(“a:\\relatorio1.txt”) #gera um relatório no disquete “Comportamento de salários para Ensino Fundamental” summary(dadosord$sal[1:12]) “Desvio-padrão:” sd(dados$sal[1:12]) “Comportamento de salários para Ensino Médio” summary(dadosordsal[13:30]) “Desvio-padrão:” sd(dadosord$sal[13:30]) “Comportamento de salários para Ensino Superior” summary(dadosord$sal[31:36]) “Desvio-padrão:” sd(dadosord$sal[31:36]) sink() #fecha o relatório
 #gera um relatório no disquete Comportamento de salários para Ensino Fundamental summary(dadosord$sal[1:12]) Desvio-padrão: sd(dados$sal[1:12]) Comportamento de salários para Ensino Médio summary(dadosordsal[13:30]) Desvio-padrão: sd(dadosord$sal[13:30]) Comportamento de salários para Ensino Superior summary(dadosord$sal[31:36]) Desvio-padrão: sd(dadosord$sal[31:36]) sink() #fecha o relatório.")
10
Lista de comandos source(“http://www.im.ufrj.br/~flavia/aed06/instrusal.txt”) O conteúdo será gravado no arquivo relatorio1.txt no disquete no drive A Se você preferir, edite o arquivo instrusal.txt e na primeira linha altere o endereço e/ou o nome do arquivo que conterá os resultados.
 O conteúdo será gravado no arquivo relatorio1.txt no disquete no drive A Se você preferir, edite o arquivo instrusal.txt e na primeira linha altere o endereço e/ou o nome do arquivo que conterá os resultados.")
11
[1] "Comportamento de salários para Ensino Fundamental" Min. 1st Qu. Median Mean 3rd Qu. Max. 4.000 6.008 7.125 7.837 9.163 13.850 desvio-padrão: 2.956464 [1] "Comportamento de salários para Ensino Médio" Min. 1st Qu. Median Mean 3rd Qu. Max. 5.730 8.838 10.910 11.530 14.420 19.400 desvio-padrão: 3.715144 [1] "Comportamento de salários para Ensino Superior" Min. 1st Qu. Median Mean 3rd Qu. Max. 10.53 13.65 16.74 16.47 18.38 23.30 desvio-padrão: 4.502438
![[1] Comportamento de salários para Ensino Fundamental Min.](http://images.slideplayer.com.br/17/5322049/slides/slide_11.jpg "1st Qu. Median Mean 3rd Qu. Max desvio-padrão: [1] Comportamento de salários para Ensino Médio Min. 1st Qu. Median Mean 3rd Qu. Max desvio-padrão: [1] Comportamento de salários para Ensino Superior Min. 1st Qu. Median Mean 3rd Qu. Max desvio-padrão:")
12
ResumindoResumindo nível fundamentalmédiosuperior mínimo 4,005,7310,53 Q1 6,018,8413,65 Q2 7,1210,9116,74 Q3 9,1614,4218,38 máximo 13,8519,4023,30 média 7,8411,5316,47 desvio padrão 2,963,724,50 Percebe-se claramente que as medidas de posição crescem conforme aumenta o nível de instrução.

13
Gráfico de salário versus nível de instrução Quando se dispõe de um par de variáveis, para o qual uma é qualitativa e outra é quantitativa, é comum representar o comportamento conjunto delas usando-se boxplots das distribuições das variáveis quantitativas, segundo as respostas da variável qualitativa. No R podemos usar a função já conhecida plot indicando primeiro o vetor que contém a variável qualitativa.

14
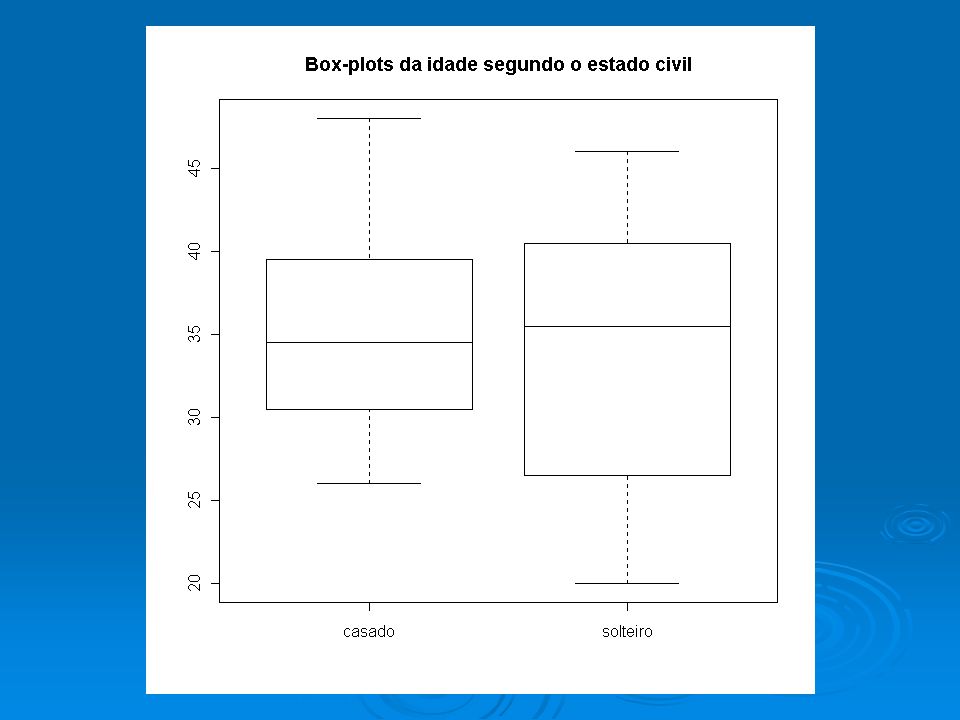
Gráfico de salário versus nível de instrução (1) plot(dados$instrucao,dados$sal,main="Box-plots de salário segundo o nível de instrução")
 plot(dados$instrucao,dados$sal,main= Box-plots de salário segundo o nível de instrução )")
15
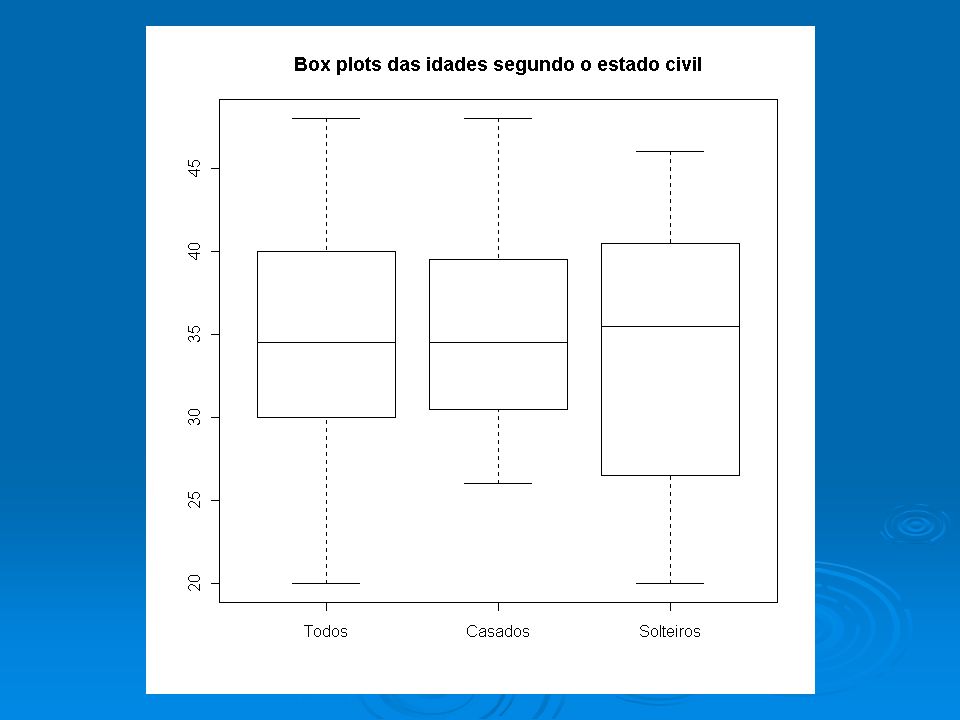
Comportamento dos salários sem discriminar por nível de instrução (todos) summary(dadosord$sal) Min. 1st Qu. Median Mean 3rd Qu. Max. 4.000 7.553 10.160 11.120 14.060 23.300 sd(dados$sal) [1] 4.587458 nível todos fundamentalmédiosuperior mínimo 4,00 4,005,7310,53 Q1 7,55 6,018,8413,65 Q2 10,16 7,1210,9116,74 Q3 14,06 9,1614,4218,38 máximo 23,30 13,8519,4023,30 média 11,12 7,8411,5316,47 desvio padrão 4,59 2,963,724,50 Ver tabela 2
 [1] nível todos fundamentalmédiosuperior mínimo 4,00 4,005,7310,53 Q1 7,55 6,018,8413,65 Q2 10,16 7,1210,9116,74 Q3 14,06 9,1614,4218,38 máximo 23,30 13,8519,4023,30 média 11,12 7,8411,5316,47 desvio padrão 4,59 2,963,724,50 Ver tabela 2.")
16
boxplot(dados$sal,dadosord$sal[1:12],dadosord$sal[13:30], dadosord$sal[31:36],names=c("Todos","F","M","S"))
![boxplot(dados$sal,dadosord$sal[1:12],dadosord$sal[13:30], dadosord$sal[31:36],names=c( Todos , F , M , S ))](http://images.slideplayer.com.br/17/5322049/slides/slide_16.jpg "boxplot(dados$sal,dadosord$sal[1:12],dadosord$sal[13:30], dadosord$sal[31:36],names=c( Todos , F , M , S ))")
17
Comentário É possível perceber, a partir destes dados e gráficos, uma dependência entre salário e nível de instrução: o salário tende a ser maior conforme é maior a escolaridade do empregado.

18
Exemplo 2: salário versus região de procedência Vamos agora analisar o comportamento dos salários dentro de cada região de procedência, ou seja, investigar o comportamento conjunto das variáveis cujos nomes na base de dados são sal e rp. Para facilitar, vamos primeiro ordenar os dados numa nova base (dadosrp) pela variável rp.
 pela variável rp..")
19
Ordenando por Região de Procedência indice=order(dados$rp) dadosrp=dados[indice,] table(dados$rp) capital interior outra 11 12 13 Logo, em dadosrp as observações de 1 a 11 são de empregados cuja procedência é a capital, de 12 a 23 é o interior e de 24 a 36 são outras regiões.
![Ordenando por Região de Procedência indice=order(dados$rp) dadosrp=dados[indice,] table(dados$rp) capital interior outra Logo, em dadosrp as observações de 1 a 11 são de empregados cuja procedência é a capital, de 12 a 23 é o interior e de 24 a 36 são outras regiões.](http://images.slideplayer.com.br/17/5322049/slides/slide_19.jpg "Ordenando por Região de Procedência indice=order(dados$rp) dadosrp=dados[indice,] table(dados$rp) capital interior outra Logo, em dadosrp as observações de 1 a 11 são de empregados cuja procedência é a capital, de 12 a 23 é o interior e de 24 a 36 são outras regiões.")
20
Medidas resumo por região de procedência sink(“a:\\relatoriorp.txt”) #abre arquivo que conterá os resultados “Comportamento de salários para Capital” summary(dadosrp$sal[1:11]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[1:11]) “Comportamento de salários para Interior” summary(dadosrp$sal[12:23]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[12:23]) “Comportamento de salários para Outras” summary(dadosrp$sal[24:36]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[24:36]) sink() # fecha arquivo
![Medidas resumo por região de procedência sink( a:\\relatoriorp.txt ) #abre arquivo que conterá os resultados Comportamento de salários para Capital summary(dadosrp$sal[1:11]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[1:11]) Comportamento de salários para Interior summary(dadosrp$sal[12:23]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[12:23]) Comportamento de salários para Outras summary(dadosrp$sal[24:36]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[24:36]) sink() # fecha arquivo](http://images.slideplayer.com.br/17/5322049/slides/slide_20.jpg "Medidas resumo por região de procedência sink( a:\\relatoriorp.txt ) #abre arquivo que conterá os resultados Comportamento de salários para Capital summary(dadosrp$sal[1:11]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[1:11]) Comportamento de salários para Interior summary(dadosrp$sal[12:23]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[12:23]) Comportamento de salários para Outras summary(dadosrp$sal[24:36]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[24:36]) sink() # fecha arquivo")
21
Lista de comandos source(“http://www.im.ufrj.br/~flavia/aed06/rpsal.txt”) O conteúdo será gravado no arquivo relatoriorp.txt no disquete no drive A Se você preferir, edite o arquivo rpsal.txt e na primeira linha altere o endereço e/ou o nome do arquivo que conterá os resultados.
 O conteúdo será gravado no arquivo relatoriorp.txt no disquete no drive A Se você preferir, edite o arquivo rpsal.txt e na primeira linha altere o endereço e/ou o nome do arquivo que conterá os resultados.")
22
[1] "Comportamento de salários para Capital" Min. 1st Qu. Median Mean 3rd Qu. Max. 4.56 7.49 9.77 11.46 16.63 19.40 desvio-padrão: 5.476653 [1] "Comportamento de salários para Interior" Min. 1st Qu. Median Mean 3rd Qu. Max. 4.000 7.805 10.650 11.550 14.700 23.300 desvio-padrão: 5.296055 [1] "Comportamento de salários para Outras" Min. 1st Qu. Median Mean 3rd Qu. Max. 5.73 8.74 9.80 10.45 12.79 16.22 desvio-padrão: 3.145453
![[1] Comportamento de salários para Capital Min. 1st Qu.](http://images.slideplayer.com.br/17/5322049/slides/slide_22.jpg "Median Mean 3rd Qu. Max desvio-padrão: [1] Comportamento de salários para Interior Min. 1st Qu. Median Mean 3rd Qu. Max desvio-padrão: [1] Comportamento de salários para Outras Min. 1st Qu. Median Mean 3rd Qu. Max desvio-padrão:")
23
Resumindo: salário versus região de procedência regiãotodosCapitalInteriorOutros mínimo 4,004,564,005,73 Q17,55 7,497,818,74 Q210,16 9,7710,659,80 Q314,06 16,6314,7012,79 máximo23,30 19,4023,3016,22 média11,12 11,4611,5510,45 desvio-padrão4,59 5,485,303,14 Volta

24
Gráfico de salário versus região de procedência plot(dados$rp,dados$sal,main="Box-plots de salário segundo a região de procedência")
")
25
Comportamento dos salários sem discriminar por nível de instrução (todos) boxplot(dados$sal,dadosrp$sal[1:11],dadosrp$sal[12:23], dadosrp$sal[24:36],names=c("Todos",”Capital",”Interior”, ”Outras"))
![Comportamento dos salários sem discriminar por nível de instrução (todos) boxplot(dados$sal,dadosrp$sal[1:11],dadosrp$sal[12:23], dadosrp$sal[24:36],names=c( Todos , Capital , Interior , Outras ))](http://images.slideplayer.com.br/17/5322049/slides/slide_25.jpg "Comportamento dos salários sem discriminar por nível de instrução (todos) boxplot(dados$sal,dadosrp$sal[1:11],dadosrp$sal[12:23], dadosrp$sal[24:36],names=c( Todos , Capital , Interior , Outras ))")
26
Comentário É possível perceber, a partir destes dados e gráficos que não há uma relação bem definida entre salário e região de procedência. Os salários parecem estar mais relacionados com o nível de instrução do que com a região de procedência.

27
Problema Como quantificar a dependência entre estas variáveis? No caso de duas variáveis quantitativas usa-se a correlação. No caso de duas variáveis qualitativas usa-se o qui-quadrado. O que usar no caso de uma variável qualitativa e uma quantitiativa?

28
Medida de dependência: uma variável qualitativa e uma quantitativa Vamos usar as variâncias dentro de cada categoria de resposta da variável qualitativa e a variância global, para definir uma medida de associação entre uma variável qualitativa e uma quantitativa.

29
Medida de dependência: uma variável qualitativa e uma quantitativa (1) Se a variância dentro de cada categoria de resposta for pequena e menor do que a global, significa que a variável qualitativa melhora a capacidade de previsão da variável quantitativa e, portanto, existe uma relação entre as duas variáveis. Ver tabela 1

30
Instrução versus salário Região de procedência versus salário Parece haver uma melhora na capacidade de previsão de salário, segundo o nível de instrução. Não parece haver melhora na capacidade de previsão de salário, segundo a região de procedência.

31
Medida de dependência: uma variável qualitativa e uma quantitativa (2) Observe que para as variáveis salário e instrução, as variâncias dentro de cada nível são menores do que a variância global: var(dados$sal) # variância global de salários 21.04477 var(dadosord$sal[1:12]) #var. de salários para Ens. Fund. 8.740679 var(dadosord$sal[13:30]) #var. de salários para Ens. Médio 13.80230 var(dadosord$sal[31:36]) #var. de salários para Ens. Sup. 20.27195
![Medida de dependência: uma variável qualitativa e uma quantitativa (2) Observe que para as variáveis salário e instrução, as variâncias dentro de cada nível são menores do que a variância global: var(dados$sal) # variância global de salários var(dadosord$sal[1:12]) #var.](http://images.slideplayer.com.br/17/5322049/slides/slide_31.jpg "de salários para Ens. Fund var(dadosord$sal[13:30]) #var. de salários para Ens. Médio var(dadosord$sal[31:36]) #var. de salários para Ens. Sup")
32
Medida de dependência: uma variável qualitativa e uma quantitativa (3) Para as variáveis sal e rp, vemos que as variâncias dentro de cada região de procedência não são menores do que a global: var(dados$sal) # variância global de salários 21.04477 var(dadosrp$sal[1:11]) #var. de salários para capital 29.99373 var(dadosrp$sal[12:23]) #var. de salários para interior 28.0482 var(dadosrp$sal[24:36]) #var. de salários para outra 9.893877
![Medida de dependência: uma variável qualitativa e uma quantitativa (3) Para as variáveis sal e rp, vemos que as variâncias dentro de cada região de procedência não são menores do que a global: var(dados$sal) # variância global de salários var(dadosrp$sal[1:11]) #var.](http://images.slideplayer.com.br/17/5322049/slides/slide_32.jpg "de salários para capital var(dadosrp$sal[12:23]) #var. de salários para interior var(dadosrp$sal[24:36]) #var. de salários para outra")
33
Medida de dependência: uma variável qualitativa e uma quantitativa (4) Utiliza-se a média das variâncias, porém ponderada pelo número de observações em cada categoria, ou seja, Essa variância média será comparada à variância global.
 Utiliza-se a média das variâncias, porém ponderada pelo número de observações em cada categoria, ou seja, Essa variância média será comparada à variância global.")
34
Medida de dependência: uma variável qualitativa e uma quantitativa (5) variância dentro da i-ésima categoria de resposta, i=1,...,k. Nos dois exemplos trabalhados k foi igual a 3: instrução (F,M,S) e região de procedência (capital,interior,outra). número de categorias de resposta da variável qualitativa número de observações na i-ésima categoria de resposta =n (total de observações.
 e região de procedência (capital,interior,outra). número de categorias de resposta da variável qualitativa número de observações na i-ésima categoria de resposta =n (total de observações..")
35
Variância dentro de cada grupo Se x ij representa o salário do j -ésimo indivíduo da i - ésima categoria de instrução, i =1,2,3 e j=1,..., n i com n i representando o total de indivíduos com escolaridade de nível i, a variância dentro do i -ésimo nível de scolaridade Var i (S) é dada por com representando a média de salário para o nível de escolaridade i.
 é dada por com representando a média de salário para o nível de escolaridade i.")
36
Continuação Fórmula para o cálculo de

37
Variância Global representa a média global. é o número total de observações

38
Medida de dependência: uma variável qualitativa e uma quantitativa (5) com Var(S) representando a variância global e representando a média ponderada das variâncias dentro de cada categoria da variável qualitativa.
 com Var(S) representando a variância global e representando a média ponderada das variâncias dentro de cada categoria da variável qualitativa.")
39
é igual a zero

40
soma dos desvios da média em cada grupo.

41
Portanto, tal que

42
Medida de dependência: uma variável qualitativa e uma quantitativa (6) O grau de associação entre as duas variáveis é definido como o ganho relativo na variância, obtido pela introdução da variável qualitativa. A medida é baseada na decomposição de somas de quadrados vista anteriormente.

43
Medida de dependência: uma variável qualitativa e uma quantitativa (7) Se a média das variâncias for muito parecida com a variância global, o ganho relativo na variância será pequeno. Já se a média das variâncias for bem menor do que a variância global, o ganho relativo na variância será grande.

44
Medida de dependência: uma variável qualitativa e uma quantitativa (7) Observe que 0R 2 1. O símbolo R 2 é usual em análise de variância e regressão, tópicos que vão ser abordados nas disciplinas Análise de Regressão e Planejamento de Experimentos. Quanto mais próximo de 1 for o valor de R 2, maior será a associação.

45
Cálculo de R 2 Calcule o R 2 para o par salário e instrução. s=35*var(dados$sal)/36 #variância global de salários com denominador n s1=11*var(dadosord$sal[1:12])/12 #var. sal. Ens. Fund. s2=17*var(dadosord$sal[13:30])/18 #var. sal. Ens. Médio s3=5*var(dadosord$sal[31:36])/6 #var.sal. Ens. Superior sbarra=(12*s1+18*s2+6*s3)/36 #média pond. variâncias R2=(s-sbarra)/s #cálculo de R2 R 2 0.4133 Dizemos que 41,33% da variação total do salário é explicada pela variável instrução.
/36 #variância global de salários com denominador n s1=11*var(dadosord$sal[1:12])/12 #var. sal. Ens. Fund. s2=17*var(dadosord$sal[13:30])/18 #var. sal. Ens. Médio s3=5*var(dadosord$sal[31:36])/6 #var.sal. Ens. Superior sbarra=(12*s1+18*s2+6*s3)/36 #média pond. variâncias R2=(s-sbarra)/s #cálculo de R2 R 2 Dizemos que 41,33% da variação total do salário é explicada pela variável instrução..")
46
Tabela para o cálculo de R 2 NívelFMStotal soma simples94.04207.5198.85400.40 soma de quadrados simples833.112626.881729.915189.90 ni1218636 média7.8411.5316.4811.12 soma de quadrados corrigida pela média96.15234.64101.36736.57 432.15 Variação total Variação residual

47
Cálculo de R 2 (continuação)
")
48
Cálculo de R 2 Calcule o R 2 para o par salário e região de procedência. s=35*var(dados$sal)/36 #variância global de salários com denominador n s1=10*var(dadosrp$sal[1:11])/11#capital s2=11*var(dadosrp$sal[12:23])/12#interior s3=12*var(dadosrp$sal[24:36])/13#outra sbarra=(11*s1+12*s2+13*s3)/36 R2=(s-sbarra)/s R 2 0.0127 Dizemos que apenas 1,27% da variabilidade dos salários é explicada pela região de procedência.
/36 #variância global de salários com denominador n s1=10*var(dadosrp$sal[1:11])/11#capital s2=11*var(dadosrp$sal[12:23])/12#interior s3=12*var(dadosrp$sal[24:36])/13#outra sbarra=(11*s1+12*s2+13*s3)/36 R2=(s-sbarra)/s R 2 Dizemos que apenas 1,27% da variabilidade dos salários é explicada pela região de procedência..")
49
Tabela para o cálculo de R 2 Regiãocapitalinterioroutratotal soma simples126.01138.60135.79400.40 soma de quadrados simples1743.441909.361537.115189.90 ni11121336 média11.4611.5510.4511.12 soma de quadrados corrigida299.94308.53118.73736.57 727.19

50
Cálculo de R2 (continuação)
")
51
Observação A comparação dos valores de R 2 em cada exemplo confirma comentário anterior de que há uma relação entre salário e instrução e, que entre salário e região de procedência, não há relação.

52
Usando funções do R para calcular o R 2 No R, o comando aov(dados$sal~dados$instrucao), gerará a seguinte tabela: Terms: dados$instrucao Residuals Sum of Squares 304.4206 432.1463 Deg. of Freedom 2 33 é a variação devido aos grupos – numerador de R 2 é a variação residual Logo,

53
Salário versus região de procedência aov(dados$sal~dados$rp) Logo, Terms: dados$rp Residuals Sum of Squares 9.3728 727.1940 Deg. of Freedom 2 33

54
Revendo as fórmulas Decomposição da variação total – soma de quadrados total - SQ variação total - SQTot variação residual - SQRes variação devida aos grupos – SQExp

56
Exercício 1 Calcule o grau de associação entre as variáveis estado civil e idade (em anos completos) nos dados da companhia MB. > indice=order(dados$ecivil) > dadosec=dados[indice,] > table(dados$ecivil) casado solteiro 20 16 > s=35*var(dados$idadea)/36 > s1=19*var(dadosec$idadea[1:20])/20 > s2=15*var(dadosec$idadea[21:36])/16 > sbarra=(20*s1+16*s2)/36 > R2=(s-sbarra)/s > R2 [1] 0.0090952 Sugestão: R.: O estado civil explica apenas 0,9% da variabilidade total da idade.
 > dadosec=dados[indice,] > table(dados$ecivil) casado solteiro > s=35*var(dados$idadea)/36 > s1=19*var(dadosec$idadea[1:20])/20 > s2=15*var(dadosec$idadea[21:36])/16 > sbarra=(20*s1+16*s2)/36 > R2=(s-sbarra)/s > R2 [1] Sugestão: R.: O estado civil explica apenas 0,9% da variabilidade total da idade..")
57
Exercício 1 (cont.) Alternativamente, aov(dados$idadea~dados$sal) Terms: dados$ecivil Residuals Sum of Squares 14.45 1574.30 Deg. of Freedom 1 34 R2=14.45/(1574.3+14.45) > R2 [1] 0.0090952
 > R2 [1]")
60
Exercício 2 Voltando aos dados da pesquisa de telemarketing (telemark.TXT), investigue possíveis dependências entre os seguintes pares de variáveis: cia e uso renda e uso instrucao e uso idade e uso.
, investigue possíveis dependências entre os seguintes pares de variáveis: cia e uso renda e uso instrucao e uso idade e uso.")
62
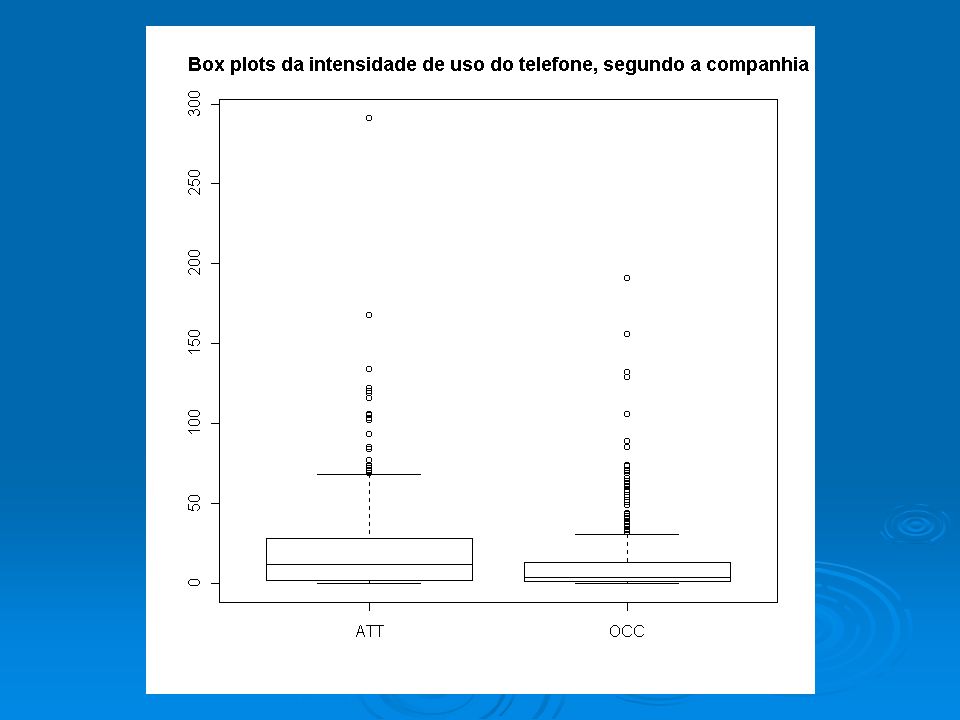
aov(tel$uso~tel$cia) Call: aov(formula = tel$uso ~ tel$cia) Terms: tel$cia Residuals Sum of Squares 17905.1 584990.0 Deg. of Freedom 1 998 R2=17905.1/(17905.1+584990) > R2 [1] 0.02969853 R.: A Companhia explica apenas cerca de 3% da variabilidade total da variável uso.
 > R2 [1] R.: A Companhia explica apenas cerca de 3% da variabilidade total da variável uso..")
63
Renda versus uso

64
Call: aov(formula = tel$uso ~ tel$renda) Terms: tel$renda Residuals Sum of Squares 19314.2 387447.2 Deg. of Freedom 6 778 > R2=19314.2/(19314.2+387447.2) > R2 [1] 0.04748287 R.: A faixa de renda explica apenas cerca de 4,7% da variabilidade total da variável uso.
 > R2 [1] R.: A faixa de renda explica apenas cerca de 4,7% da variabilidade total da variável uso..")
65
Instrução e uso

66
> aov(tel$uso~tel$instrucao) Call: aov(formula = tel$uso ~ tel$instrucao) Terms: tel$instrucao Residuals Sum of Squares 25333.6 547578.7 Deg. of Freedom 5 959 > R2=25333.6/(25333.6+547578.7) > R2 [1] 0.04421898 R.: A escolaridade explica apenas cerca de 4,4% da variabilidade total da variável uso.
 > R2 [1] R.: A escolaridade explica apenas cerca de 4,4% da variabilidade total da variável uso..")
67
Idade e uso

68
Call: aov(formula = tel$uso ~ tel$idade) Terms: tel$idade Residuals Sum of Squares 18638.8 559852.2 Deg. of Freedom 5 961 R2=18638.8/(18638.8+559852.2) > R2 [1] 0.03221969 R.: A idade explica apenas cerca de 3,2% da variabilidade total da variável uso.
 > R2 [1] R.: A idade explica apenas cerca de 3,2% da variabilidade total da variável uso..")
69
Conclusão Pelas análises feitas, não percebe-se nenhuma dependência entre a variável intensidade de uso do telefone e as variáveis cia, renda, idade e escolaridade.

70
Funções do R usadas na aula de hoje: read.table order sink summary sd var plot boxplot aov (analysis of variance)
")
Apresentações semelhantes