Carregar apresentação
A apresentação está carregando. Por favor, espere

1
MOTIVAÇÃO A Estatística e Deming. W. E. DEMING
Nasceu em 14 de Outubro de 1900 em Sioux City, Iowa. Em 1921 licenciou-se em Física, na Universidade do Wyoming e, em 1928, doutorou-se em Matemática pela Yale University.

2
O impacto das suas idéias foi de tal forma elevado que Deming é, hoje, considerado “o pai do milagre industrial japonês”. Morreu em 1993, com 93 anos. Em sua homenagem, a JUSE (Japan Union of Scientists and Engineers) instituiu o Deming Prize, que premia anualmente as melhores empresas no campo da qualidade. Deming foi condecorado pelo imperador do Japão com o mais elevado galardão atribuído a um estrangeiro: a Medalha de 2.ª Ordem do Sagrado Tesouro. Os Estados Unidos só o descobriram na década de 80. Em 1986, Reagan atribuiu-lhe a National Medal of Technology e nesse ano foi lançado o livro Out of Crisis, a obra que consolidou de vez a sua fama como o grande mestre da qualidade.

3
W.E. DEMING W. E. DEMING

6
ENGENHARIA: CEP, DOE, CONFIABILIDADE

7
Allysson Paulinelli Ministro da Agric. 1974 linelli
Coloca Eliseu Alves, na presidência da EMBRAPA Cria 14 Centros de Pesquisas em 14 regiões do país (exceto o café que tinha o IBC e o cacau que tinha a CEPLAC) Criou 4 Centros de Recursos Genéticos para o cerrado em Brasília. Com uma verba de US 200 milhões, escolheu nas melhores universidades brasileiras 1600 recém-formados e mandou-os fazer Mestrado e Doutorado nas melhores escolas agrícolas do mundo: California, Wisconsin, California, Wisconsin, França, Espanha, Índia, Japão, etc.
 Criou 4 Centros de Recursos Genéticos para o cerrado em Brasília. Com uma verba de US 200 milhões, escolheu nas melhores universidades brasileiras 1600 recém-formados e mandou-os fazer Mestrado e Doutorado nas melhores escolas agrícolas do mundo: California, Wisconsin, California, Wisconsin, França, Espanha, Índia, Japão, etc.")
9
1. ANÁLISE COMBINATÓRIA As várias maneiras de se dispor os objetos de um conjunto em grupos denominados agrupamentos dependem basicamente de duas características: 1ª.) em cada agrupamento formado todos os elementos são distintos; 2ª.) em cada agrupamento pode haver repetição de elementos.
 em cada agrupamento formado todos os elementos são distintos; 2ª.) em cada agrupamento pode haver repetição de elementos.")
10
Arranjos, Permutações e Combinações
Quando os agrupamentos têm a primeira característica (todos os elementos são distintos) são chamados de agrupamentos simples. E, quando os agrupamentos têm a segunda característica (repetição de elementos) denominam-se agrupamentos com repetição. Considerando o modo de formação dos grupos tem-se: Arranjos, Permutações e Combinações
 são chamados de agrupamentos simples. E, quando os agrupamentos têm a segunda característica (repetição de elementos) denominam-se agrupamentos com repetição. Considerando o modo de formação dos grupos tem-se: Arranjos, Permutações e Combinações.")
11
Análise Combinatória Simples é o estudo da formação, contagem e propriedades dos agrupamentos simples. Nos agrupamento simples os grupos diferem pela ordem ou pela natureza dos elementos que o compõem. E, no caso de diferirem pela natureza, tem-se que pelo menos um dos elementos de um dos grupos formados não pertence ao outro.

12
FATORIAL de um número inteiro n representado por n! é definido por:
n! = n(n-1)(n-2)(n-3) (n-n+2)(n-n+1) n! = n(n-1)(n-2)(n-3) Especialmente, tem-se, por definição: 0! = 1 1! = 1 ARRANJOS de n elementos tomados p a p = = n(n-1).(n-2)......(n-p+2)(n-p+1)
(n-2)(n-3) (n-n+2)(n-n+1) n! = n(n-1)(n-2)(n-3) Especialmente, tem-se, por definição: 0! = 1. 1! = 1. ARRANJOS de n elementos tomados p a p. = = n(n-1).(n-2)......(n-p+2)(n-p+1)")
13
Permutação de n elementos é a denominação dada aos arranjos com n = p, ou seja, são os elementos de A com p = n. Fica fácil ver que Pn = = n(n-1)(n-2) ... (n-n+1) = n! Combinação simples de n elementos tomados p a p é representada por = Cn,p = = Números Binomiais ou Combinatórios Os números conhecidos como binomiais são aqueles da forma e são representados por:

14
Exercícios: 1) Calcule o valor numérico de cada uma das expressões: a) 5! + 2! = = = 122 b) = = 5) Calcule o valor de x na equação (x+2)! = 2(x+1)! Solução: (x+2)(x+1)x(x-1)(x-2)……1 = 2[(x+1)x(x-1)(x-2)...1] (x+2) = 2 x = 0
 = = 5) Calcule o valor de x na equação (x+2)! = 2(x+1)! Solução: (x+2)(x+1)x(x-1)(x-2)……1 = 2[(x+1)x(x-1)(x-2)...1] (x+2) = 2 x = 0.")
15
8) Calcule o número de arranjos de 4 elementos tomados de 2 em 2.
Solução: A = = = 12 11) Calcule o valor da expressão Solução: = = 122 2) Qual o número de permutações simples com objetos repetidos que se pode obter com as letras da palavra matemática? P =
 Calcule o valor da expressão. Solução: + + = = ) Qual o número de permutações simples com objetos repetidos que se pode obter com as letras da palavra matemática P =")
16
Matemática tem: 2 letras m, 3 letras a, 2 letras t, 1 letra e, 1 letra i e 1 letra c. Logo, n = 10 letras.

17
4) Em certo ano, somente quatro times de futebol têm chances de ficar em dos três primeiros lugares do campeonato brasileiro. São eles Santos, Corinthians, Coritiba e Flamengo. Quantas são as possibilidades para cada um dos três primeiros lugares? R: 24 Solução: Deve-se agrupar 4 elementos de 3 em 3. Como os agrupamentos são distintos pela ordem e pelos elementos tem-se Arranjo. A =

18
7) Quantas diagonais tem o pentágono?
Solução: É necessário agrupar os 5 vértices do pentágono de 2 em 2. Trocando a ordem o agrupamento é o mesmo, portanto tem-se combinação de 5 elementos tomados de 2 em 2, mas deve-se descontar os 5 lados. Cn,p = = = 10 – 5 = 5

19
9) Considere n objetos. Agrupando-os 4 a 4 de modo que cada grupo possua pelo menos um objeto diferente do outro obtém-se o mesmo número de grupos que o obtido quando se junta os objetos de 6 em 6. Qual o valor de n? Solução: Cn,p = Cn,4 = Cn,6 = Sabe-se que números binomiais com mesmo numerador (n) e módulos complementares (p) são iguais.
 e módulos complementares (p) são iguais.")
20
Então, são complementares portanto 4 = p e 6 = n – p 6 = n - 4 n = 10

21
2. PROBABILIDADE E MODELOS DE PROBABILIDADE
Considere o experimento de jogar um dado equilibrado e observar o número da face superior. Observa-se no experimento que: Os “resultados possíveis” de ocorrer formam o conjunto = {1, 2, 3, 4, 5, 6}. DEF. 1 ESPAÇO AMOSTRAL, , de um experimento realizado sob condições fixas, é o conjunto de todos os resultados possíveis do experimento, entendendo-se por resultado possível todo resultado elementar e indivisível do experimento.

22
2.1.1) Considere, o experimento que consiste na escolha, ao acaso, de um ponto equidistante dos extremos do segmento de reta AB com comprimento de 2 cm, contido no eixo das abscissas de um Sistema Cartesiano e com A colocado na origem do sistema. y m A B x

23
Descreva o espaço amostral do experimento;
= {(x,y) R2 | x = 1} b) Descreva o resultado 1 “distância entre o ponto escolhido e o ponto médio do segmento é 2” na forma de subconjunto do espaço amostral; 1 = { (x,y) | y 2} c) Descreva o resultado 2 “distância entre o ponto escolhido e a origem é ½”; 2 = { } = d) Descreva o resultado 3 “a 1a. coordenada do ponto escolhido tem comprimento menor que a 2ª. ”. { (x,y) | x |y|}
 R2 | x = 1} b) Descreva o resultado 1 distância entre o ponto escolhido e o ponto médio do segmento é 2 na forma de subconjunto do espaço amostral; 1 = { (x,y) | y 2} c) Descreva o resultado 2 distância entre o ponto escolhido e a origem é ½ ; 2 = { } = d) Descreva o resultado 3 a 1a. coordenada do ponto escolhido tem comprimento menor que a 2ª. . { (x,y) | x |y|}")
24
DEF. 2 RESULTADO COMPOSTO é todo resultado formado por mais de um resultado elementar e indivisível.
Ex.: O resultado “número par” NP = {2, 4, 6} não é elementar e indivisível, pois é composto por três resultados deste tipo {2}, {4} e {6}, logo “número par” é um resultado composto. O resultado “número par” é o subconjunto NP = {2, 4, 6} . Assim, todo resultado do experimento é subconjunto do espaço amostral.

25
DEF. 3 -ÁLGEBRA, A, de subconjuntos do conjunto não-vazio é a classe de subconjuntos de satisfazendo as propriedades: 1a.) A 2a.) Se A A Ac A 3a.) Se A1, A2, A3, A A A -ÁLGEBRA mais simples é o conjunto das partes de , ou seja, P() = {, {1}, ... , {6}, {1,2}, ... , {5,6},...., } no experimento do lançamento do dado, p.ex. DEF. 4 Seja o espaço amostral do experimento. Todo subconjunto A será chamado de evento, o conjunto é evento certo, o subconjunto é o evento impossível e se o evento {} é dito elementar e indivisível.
 A. 2a.) Se A A Ac A. 3a.) Se A1, A2, A3, A A. A -ÁLGEBRA mais simples é o conjunto das partes de , ou seja, P() = {, {1}, ... , {6}, {1,2}, ... , {5,6},...., } no experimento do lançamento do dado, p.ex. DEF. 4 Seja o espaço amostral do experimento. Todo subconjunto A será chamado de evento, o conjunto é evento certo, o subconjunto é o evento impossível e se o evento {} é dito elementar e indivisível.")
26
DEF. 5 DEFINIÇÃO CLÁSSICA DE PROBABILIDADE (quando é finito).
Seja A um subconjunto do espaço amostral , AP(), então se todos os resultados elementares de são equiprováveis a medida da probabilidade de ocorrência do evento A é dada por P(A) = , A A.
, então se todos os resultados elementares de são equiprováveis a medida da probabilidade de ocorrência do evento A é dada por. P(A) = , A A.")
27
2.1.2) Um dado é lançado. Pergunta-se a probabilidade dos eventos:
A = sair um número ímpar. A = {1, 3, 5} = {1, 2, 3, 4, 5, 6} P(A) = = b) B = sair um número menor que 3. B = {1, 2} P(B) = = = 1/3
 = = b) B = sair um número menor que 3. B = {1, 2} P(B) = = = 1/3.")
28
c) C = sair um número maior que 10.
P(C) = = d) = sair um número inteiro maior ou igual a 1 e menor ou igual a 6. = {1, 2, 3, 4, 5, 6} P() = =
 = = d) = sair um número inteiro maior ou igual a 1 e menor ou igual a 6. = {1, 2, 3, 4, 5, 6} P() = =")
29
2.2.5) Durante um período de 24 h, em algum momento X, uma chave é posta na posição “ligada”. Depois em algum momento futuro Y (dentro do período de 24h) a chave é virada para a posição “desligada”. Suponha que X e Y sejam medidas em horas, no eixo dos tempos, com o início do período na origem da escala. O resultado do experimento é constituído pelo par de números (X, Y).
 a chave é virada para a posição desligada . Suponha que X e Y sejam medidas em horas, no eixo dos tempos, com o início do período na origem da escala. O resultado do experimento é constituído pelo par de números (X, Y)..")
30
Descreva o espaço amostral. = {(x,y) R2 | 0 < x < y < 24}
b) Descreva e marque no plano XY os seguintes eventos: (i) O circuito está ligado por uma hora ou menos. A = {(x,y) | y – x < 1} y< x + 1 y > x+1 y = x
 Descreva e marque no plano XY os seguintes eventos: (i) O circuito está ligado por uma hora ou menos. A = {(x,y) | y – x < 1} y< x + 1. y > x+1. y = x.")
31
(ii) O circuito está ligado no tempo Z, onde Z é algum instante no período de 24 h.
B = {(x,y) | 0 < x < z < y < 24} y > x
 | 0 < x < z < y < 24} y > x.")
32
(iii) O circuito é ligado antes do tempo t1 e desligado depois do tempo t2 (onde t1< t2 são dois instantes durante o período especificado de 24 h). C = {(x,y) | x < t1 < t2 < y < 24} (iv) O circuito permanece ligado duas vezes mais tempo do que desligado. y – x = 2(x+24-y) y – x = 2x+48-2y x y 3y = 3x + 48 y = x + 16
 | x < t1 < t2 < y < 24} (iv) O circuito permanece ligado duas vezes mais tempo do que desligado. y – x = 2(x+24-y) y – x = 2x+48-2y 0 x y 24. 3y = 3x y = x")
33
D = {(x,y) | y = x + 16}
 | y = x + 16}")
34
DEF. 7 DEF. GEOMÉTRICA DE PROBABILIDADE (Gnedenko)
Suponha que um segmento seja parte de um outro maior L e que se tenha escolhido ao acaso um ponto de L. Se admitirmos que a probabilidade deste ponto pertencer a seja proporcional ao comprimento de e não depende do lugar que ocupa em L, então a probabilidade de que o ponto selecionado esteja em é: L

35
Exercício Suponha que a área de um estado seja de aproximadamente km2. e que a área de uma região metropolitana seja de km2. Então, sabendo-se que um raio caiu no estado, qual a probabilidade de ter caído nessa região metropolitana? P(R) = = = 0,0125 = 1,25%
 = = = 0,0125 = 1,25%")
36
DEF. 9 DEF. AXIOMÁTICA DE PROBABILIDADE (Kolmogorov)
Probabilidade ou medida de probabilidade na -álgebra A é a função P definida em A e que satisfaz os axiomas seguintes: A1) P(A) 0 A2) P() = 1 A3) Se A e BA e são disjuntos P(A B) = P(A) + P(B) Se A1, A2, A3, ... , An A e são disjuntos, então A3’) Se A1, A2, A3, A e são disjuntos, então
 P(A) 0. A2) P() = 1. A3) Se A e BA e são disjuntos P(A B) = P(A) + P(B) Se A1, A2, A3, ... , An A e são disjuntos, então. A3’) Se A1, A2, A3, ... A e são disjuntos, então.")
37
DEF.10 ESPAÇO DE PROBABILIDADE
É o trio (, A, P), onde , A e P são definidas anteriormente. Propriedades da Probabilidade Além das propriedades enunciadas na definição axiomática, a função P goza, ainda, das seguintes: P1) Se A é um evento aleatório, então a probabilidade de A não ocorrer é dada por: P(Ac) = 1 – P(A) P2) Se A é um evento aleatório, então 0 P(A) 1 P3) Se A1 A2 P(A1) P(A2) e P(A2 - A1) = P(A2) - P(A1) P4) P(A1A2) = P(A1) + P(A2) - P(A1A2) P5) P6)
, onde , A e P são definidas anteriormente. Propriedades da Probabilidade. Além das propriedades enunciadas na definição axiomática, a função P goza, ainda, das seguintes: P1) Se A é um evento aleatório, então a probabilidade de A não ocorrer é dada por: P(Ac) = 1 – P(A) P2) Se A é um evento aleatório, então 0 P(A) 1. P3) Se A1 A2 P(A1) P(A2) e P(A2 - A1) = P(A2) - P(A1) P4) P(A1A2) = P(A1) + P(A2) - P(A1A2) P5) P6)")
38
P10) Continuidade em Probabilidade: “Seja a seqüência {Ai}
i = 1,2,3, ... onde Ai A i, então: se Ai A P(Ai) P(A) e se Ai A P(Ai) P(A).
 P(A) e. se Ai A P(Ai) P(A).")
39
Exercício 1: Prove a propriedade P1.
Prova de: P(Ac) = 1 – P(A) Seja o espaço amostral A Ac Considere a união de subconjuntos disjuntos AAc = P(AAc) = P() P(A) + P(Ac) = 1 pelos axiomas A2 e A3 P(Ac) = 1 – P(A)
 = 1 – P(A) Seja o espaço amostral A Ac. Considere a união de subconjuntos disjuntos AAc = P(AAc) = P() P(A) + P(Ac) = 1 pelos axiomas A2 e A3. P(Ac) = 1 – P(A)")
40
Exercício 2: Prove a propriedade P2.
Prova de: 0 < P(A) < 1 Do axioma A1 P(A) > 0 E da propriedade P1 P(A) = 1 – P(Ac) para o menor valor de P(Ac) que é zero (axioma 1) tem-se o maior valor de P(A) que é 1. Portanto, 0 < P(A) < 1
 < 1. Do axioma A1 P(A) > 0. E da propriedade P1 P(A) = 1 – P(Ac) para o menor valor de P(Ac) que é zero (axioma 1) tem-se o maior valor de P(A) que é 1. Portanto, 0 < P(A) < 1.")
41
Exercício 3: Prove a propriedade P3 .
Prova de: Se A1 A2 P(A1) < P(A2) e P(A2 – A1) = P(A2) – P(A1) Seja a união de eventos disjuntos: A2 = A1(A2A1c) P(A2) = P[A1(A2A1c)] P(A2) = P(A1) + P(A2A1c) axioma A3 P(A1) = P(A2) – P(A2A1c) P(A1) < P(A2) E, P(A2 A1c) = P(A2 – A1) P(A2 A1c) = P(A2) – P(A1) Então, P(A2 – A1) = P(A2 A1c) = P(A2) – P(A1) A1 A2
 < P(A2) e P(A2 – A1) = P(A2) – P(A1) Seja a união de eventos disjuntos: A2 = A1(A2A1c) P(A2) = P[A1(A2A1c)] P(A2) = P(A1) + P(A2A1c) axioma A3. P(A1) = P(A2) – P(A2A1c) P(A1) < P(A2) E, P(A2 A1c) = P(A2 – A1) P(A2 A1c) = P(A2) – P(A1) Então, P(A2 – A1) = P(A2 A1c) = P(A2) – P(A1) A1. A2.")
42
Exercício 4: Prove a propriedade P4 .
Prova: P(A1A2) = P(A1) + P(A2) – P(A1A2) A2 A1 A1 A2 Seja a união de eventos disjuntos A1A2 = A1 (A2 – A1 A2) Então, P(A1A2) = P[A1 (A2 – A1 A2)] P(A1A2) = P(A1) + P[A2 – A1 A2)] P(A1A2) = P(A1) + P(A2) – P(A1 A2) por P3
 = P(A1) + P(A2) – P(A1A2) A2. A1. A1 A2. Seja a união de eventos disjuntos A1A2 = A1 (A2 – A1 A2) Então, P(A1A2) = P[A1 (A2 – A1 A2)] P(A1A2) = P(A1) + P[A2 – A1 A2)] P(A1A2) = P(A1) + P(A2) – P(A1 A2) por P3.")
43
2. 2. 6) Sejam A, B, C três eventos associados a um experimento
2.2.6) Sejam A, B, C três eventos associados a um experimento. Exprima em notação de conjunto as seguintes afirmações verbais: Veja que significa “ou” e associamos a adição (+). E, significa “e” e associamos a multiplicação (x). Ao menos um dos eventos ocorre; ABC b) Exatamente um dos eventos ocorre; (ABc Cc) (AcBCc) (AcBc C) c) Exatamente dois dos eventos ocorrem; (AB Cc) (ABc C) (AcBC) d) Não mais de dois eventos ocorrem simultaneamente. (AB C)c
 Sejam A, B, C três eventos associados a um experimento. Exprima em notação de conjunto as seguintes afirmações verbais: Veja que significa ou e associamos a adição (+). E, significa e e associamos a multiplicação (x). Ao menos um dos eventos ocorre; ABC. b) Exatamente um dos eventos ocorre; (ABc Cc) (AcBCc) (AcBc C) c) Exatamente dois dos eventos ocorrem; (AB Cc) (ABc C) (AcBC) d) Não mais de dois eventos ocorrem simultaneamente. (AB C)c.")
44
Probabilidade Condicional
DEF. Seja o espaço de probabilidade (, A, P) e os eventos A, B A com P(B) > 0, a probabilidade condicional do evento A dado o evento B é definida por: P(AB) = OBS: 1ª.) Se P(B) = 0, P(AB) pode ser arbitrariamente definida. A maioria dos livros faz P(AB) = 0, mas é conveniente pela independência se fazer P(AB) = P(A). 2ª.) Como P(AB) é uma probabilidade, vale para ela todas as propriedades de probabilidade.
 e os eventos A, B A com P(B) > 0, a probabilidade condicional do evento A dado o evento B é definida por: P(AB) = OBS: 1ª.) Se P(B) = 0, P(AB) pode ser arbitrariamente definida. A maioria dos livros faz P(AB) = 0, mas é conveniente pela independência se fazer P(AB) = P(A). 2ª.) Como P(AB) é uma probabilidade, vale para ela todas as propriedades de probabilidade.")
45
3ª.) Como P(AB) = Então, a probabilidade da ocorrência simultânea de A e B é dada por: P(A Teorema da Multiplicação ou da Prob. Composta “Seja o espaço de probabilidade (, A, P), então: I. P(A A,B A II. P( = P(A A1, A2, A3, ....., AnA”.
, então: I. P(A A,B A. II. P( = P(A. A1, A2, A3, ....., AnA .")
46
Prova: n = 2 P(A1A2) = P(A1)P(A2|A1) por definição
n = 3 P(A1 A2 A3) = P[(A1 A2) A3] = P(A1 A2).P(A3|A1 A2) = P(A1)P(A2|A1)P(A3|A1 A2) por indução, aceita-se a regra para n – 1 P(A1 ... An-1)=P(A1).P(A2|A1)...P(An-1|A1 A2 ... An-2) E prova-se para n assumindo o resultado de n -1 P(A1 ... An)=P[(A1 ...An-1) An) = P(A1 ... An-1)P(An|A1 ... An-1) usando o resultado para n-1 = P(A1)P(A2|A1)...P(An-1|A1 ...An-2)P(An |A1 ... An-1)
 = P[(A1 A2) A3] = P(A1 A2).P(A3|A1 A2) = P(A1)P(A2|A1)P(A3|A1 A2) por indução, aceita-se a regra para n – 1. P(A1 ... An-1)=P(A1).P(A2|A1)...P(An-1|A1 A2 ... An-2) E prova-se para n assumindo o resultado de n -1. P(A1 ... An)=P[(A1 ...An-1) An) = P(A1 ... An-1)P(An|A1 ... An-1) usando o resultado para n-1. = P(A1)P(A2|A1)...P(An-1|A1 ...An-2)P(An |A1 ... An-1)")
47
Independência de eventos
DEF.: Seja o espaço de probabilidade (, A, P). Os eventos aleatórios A e BA são estocasticamente independentes se: P(A , ou seja, P(B|A) = P(B) e P(A|B)=P(A). Eventos Mutuamente Exclusivos DEF.: Os eventos A e B, com A, B A são mutuamente exclusivos (disjuntos) se , ou seja, A .
. Os eventos aleatórios A e BA são estocasticamente independentes se: P(A , ou seja, P(B|A) = P(B) e P(A|B)=P(A). Eventos Mutuamente Exclusivos. DEF.: Os eventos A e B, com A, B A são mutuamente exclusivos (disjuntos) se , ou seja, A .")
48
Propriedades de Eventos Independentes
1a.) O evento aleatório AA é independente de si mesmo se e somente se P(A) = 0 ou P(A) = 1. 2a.) Se A e B são eventos aleatórios independentes pertencentes a A, então A e Bc, Ac e B, Ac e Bc também são independentes. 3a.) Se A e B são eventos aleatórios mutuamente exclusivos pertencentes a A, então A e B são independentes somente se P(A) = 0 ou P(B) = 0.
 O evento aleatório AA é independente de si mesmo se e somente se P(A) = 0 ou P(A) = 1. 2a.) Se A e B são eventos aleatórios independentes pertencentes a A, então A e Bc, Ac e B, Ac e Bc também são independentes. 3a.) Se A e B são eventos aleatórios mutuamente exclusivos pertencentes a A, então A e B são independentes somente se P(A) = 0 ou P(B) = 0.")
49
Teorema da Probabilidade Total e Teorema de Bayes
PARTIÇÃO DO ESPAÇO AMOSTRAL Sejam A1, A2, A3, eventos aleatórios mutuamente exclusivos e exaustivos, isto é, os Ai são disjuntos e Ai = . Então, os eventos Ai formam uma PARTIÇÃO DO ESPAÇO amostral . A1 A2 A3

50
É importante observar DUAS COISAS, admitindo-se que a seqüência A1, A2, A3, ... seja FINITA ou INFINITA ENUMERÁVEL: 1ª.) Ai e Aic formam uma PARTIÇÃO Ai A. 2ª.) evento B A tem-se pois os Ai são disjuntos e, então, os B Ai também são disjuntos e logo P(B) = P[ ]
 Ai e Aic formam uma PARTIÇÃO Ai A. 2ª.) evento B A tem-se pois os Ai são disjuntos e, então, os B Ai também são disjuntos e logo. P(B) = P[ ]")
51
Seja o evento B , então a probabilidade do evento B ocorrer é dada por: que é o Teorema da Probabilidade Total A2 A5 B A1 A4 A3

52
Com base no Teorema da Probabilidade Total é possível calcular a probabilidade do evento Aj dada a ocorrência do evento B, pela fórmula conhecida como, Teorema de Bayes

53
2. 3. 1) Dez fichas numeradas de 1 a 10 são misturadas em uma urna
2.3.1) Dez fichas numeradas de 1 a 10 são misturadas em uma urna. Duas fichas, numeradas (x, y), são extraídas da urna sucessivamente e sem reposição. Qual é a probabilidade de x + y =10? = {(1,2), (1,3), ,(9,10)} # = A = {(1,9), (2,8), (3,7), (4,6), (9,1), (8,2), (7,3), (6,4)} #A = 8 P(A) =
 Dez fichas numeradas de 1 a 10 são misturadas em uma urna. Duas fichas, numeradas (x, y), são extraídas da urna sucessivamente e sem reposição. Qual é a probabilidade de x + y =10 = {(1,2), (1,3), ,(9,10)} # = A = {(1,9), (2,8), (3,7), (4,6), (9,1), (8,2), (7,3), (6,4)} #A = 8. P(A) =")
54
2.3.2) Um lote é formado de 10 artigos bons, 4 com defeitos menores e 2 com defeitos graves. Um artigo é escolhido ao acaso. Ache a probabilidade de que: Ele não tenha defeitos; P(B) = b) Ele não tenha defeitos graves; P(DGc) =
 = b) Ele não tenha defeitos graves; P(DGc) =")
55
c) Ele, ou seja perfeito ou tenha defeitos graves;
P(B DG) = P(B) + P(DG) – P(BDG) P(B DG) = = = ¾ (mutuamente exclusivos) d) Resolva os itens b e c aplicando a definição de probabilidade. (b) P(DGc) = (c) P(B DG) =
 = P(B) + P(DG) – P(BDG) P(B DG) = = = ¾ (mutuamente exclusivos) d) Resolva os itens b e c aplicando a definição de probabilidade. (b) P(DGc) = (c) P(B DG) =")
56
2.3.3) Se do lote de artigos do problema anterior, dois artigos forem escolhidos (sem reposição), ache a probabilidade de que: Ambos sejam perfeitos; P(B B2) = P(B1)P(B2|B1) = b) Ambos tenham defeitos graves; P(DG1 DG2) = P(DG1)P(DG2|DG1) = c) Ao menos 1 seja perfeito; P[(B1 B2c ) (B1c B2) (B B2) = = P[(B1 B2c )+P(B1c B2) + P(B1 B2) = P(B1)P(B2c|B1) + P(B1c)P(B2| B1c) + P(B1)P(B2|B1)
 = P(B1)P(B2|B1) = b) Ambos tenham defeitos graves; P(DG1 DG2) = P(DG1)P(DG2|DG1) = c) Ao menos 1 seja perfeito; P[(B1 B2c ) (B1c B2) (B1 B2) = = P[(B1 B2c )+P(B1c B2) + P(B1 B2) = P(B1)P(B2c|B1) + P(B1c)P(B2| B1c) + P(B1)P(B2|B1)")
57
= = 7/8 d) No máximo 1 seja perfeito; P[(B1c B2c) (B B2c) (B1c B2)] = = P(B1c B2c) + P(B B2c) + P(B1c B2) = = P(B1c)P(B2c|B1c) + P(B1)P(B2c|B1) + P(B1c)P(B2|B1c) = =
![= = 7/8 d) No máximo 1 seja perfeito; P[(B1c B2c) (B1 B2c) (B1c B2)] =](http://slideplayer.com.br/slide/49303/1/images/57/%3D+%3D+7%2F8+d%29+No+m%C3%A1ximo+1+seja+perfeito%3B+P%5B%28B1c+B2c%29+%28B1+B2c%29+%28B1c+B2%29%5D+%3D.jpg "= P(B1c B2c) + P(B1 B2c) + P(B1c B2) = = P(B1c)P(B2c|B1c) + P(B1)P(B2c|B1) + P(B1c)P(B2|B1c) = =")
58
2.5.2) A probabilidade de que um aluno saiba a resposta para certa questão, de um exame de múltipla escolha é p. Das opções de resposta para cada questão, somente uma é correta. Se o aluno não sabe a resposta para a questão, ele seleciona ao acaso uma resposta dentre as m opções. Se a probabilidade do aluno responder corretamente dado que ele sabe a resposta é 0,88 pergunta-se: Se o aluno responder corretamente a questão, qual a probabilidade de que ele “chutou” a resposta? P(chutou|RC) = =
 = =")
59
P(chutou|RC) = (RC) = (AS RC) (ASc RC) P(RC) = P[(AS RC) (ASc RC)] P(RC) = P(AS)P(RC|AS)+P(ASc)P(RC|ASc] P(RC) = p.0,88 + (1-p)
![P(chutou|RC) = (RC) = (AS RC) (ASc RC) P(RC) = P[(AS RC) (ASc RC)] P(RC) = P(AS)P(RC|AS)+P(ASc)P(RC|ASc]](http://slideplayer.com.br/slide/49303/1/images/59/P%28chutou%7CRC%29+%3D+%28RC%29+%3D+%28AS+RC%29+%28ASc+RC%29+P%28RC%29+%3D+P%5B%28AS+RC%29+%28ASc+RC%29%5D+P%28RC%29+%3D+P%28AS%29P%28RC%7CAS%29%2BP%28ASc%29P%28RC%7CASc%5D.jpg "P(RC) = p.0,88 + (1-p)")
60
b) Se o aluno responder incorretamente a questão, qual a probabilidade de que ele não “chutou” a resposta? P(não chutou|RI) = = RI = (ASRI)(ASc RI) P(RI) = P[(AS RI) + (ASc RI)] P(RI) = P(AS)P(RI|AS)+P(ASc)P(RI|ASc] P(RI) = p.(1-0,88) + (1-p) P(não chutou|RI) = =
 = = RI = (ASRI)(ASc RI) P(RI) = P[(AS RI) + (ASc RI)] P(RI) = P(AS)P(RI|AS)+P(ASc)P(RI|ASc] P(RI) = p.(1-0,88) + (1-p) P(não chutou|RI) = =")
61
A1: chove no dia e A2: não chove B : meu time ganha o jogo P(A1|B) =
2.5.4) Durante o mês de novembro a probabilidade de chuva é 0,3. O meu time ganha um jogo em dia de chuva com probabilidade 0,4 e em dia sem chuva com probabilidade 0,6. Se ganhou o jogo em novembro, qual a probabilidade de que tenha chovido no dia? A1: chove no dia e A2: não chove B : meu time ganha o jogo P(A1|B) = P(A1|B) = = A1 A2 B
 Durante o mês de novembro a probabilidade de chuva é 0,3. O meu time ganha um jogo em dia de chuva com probabilidade 0,4 e em dia sem chuva com probabilidade 0,6. Se ganhou o jogo em novembro, qual a probabilidade de que tenha chovido no dia A1: chove no dia e A2: não chove. B : meu time ganha o jogo. P(A1|B) = P(A1|B) = = A1. A2. B.")
62
P(A1|B) =
 =")
63
3. VARIÁVEL ALEATÓRIA DEF. Uma variável X em um espaço de probabilidade (,A,P) é uma função real definida no espaço , tal que o evento [X x] é evento aleatório x R isto é, a função X: R é v. a. se o evento [ X x ] A, x R. EXEMPLO Seja uma família com duas crianças. Escreva todas as situações possíveis de ocorrer quanto ao sexo das crianças; R: = {(F1, F2), (F1, M2), (M1, F2), (M1, M2)}
 é uma função real definida no espaço , tal que o evento [X x] é evento aleatório x R isto é, a função X: R é v. a. se o evento [ X x ] A, x R. EXEMPLO. Seja uma família com duas crianças. Escreva todas as situações possíveis de ocorrer quanto ao sexo das crianças; R: = {(F1, F2), (F1, M2), (M1, F2), (M1, M2)}")
64
b) Associe a cada situação possível um número real considerando a função que conta o número de meninos do evento; O R 1=(F1,F2) X() = x 2=(F1,M2) 2=(M1,F2) 2=(M1,M2)
 X() = x. 2=(F1,M2) 2=(M1,F2) 2=(M1,M2)")
65
DEF. VARIÁVEL ALEATÓRIA DISCRETA
c) O campo de variação da variável aleatória X, ou contradomínio, é o conjunto {0, 1, 2}. DEF. VARIÁVEL ALEATÓRIA DISCRETA A v.a. X é chamada de DISCRETA quando o seu contradomínio é um conjunto finito ou infinito enumerável, ou melhor, se existe um conjunto finito ou infinito enumerável {x1, x2, x3, ... } R tal que X() {x1, x2, x3, ... } . DEF. VARIÁVEL ALEATÓRIA CONTÍNUA A v.a. X é chamada de CONTÍNUA quando o seu contradomínio é um conjunto infinito não enumerável.
 O campo de variação da variável aleatória X, ou contradomínio, é o conjunto {0, 1, 2}. DEF. VARIÁVEL ALEATÓRIA DISCRETA. A v.a. X é chamada de DISCRETA quando o seu contradomínio é um conjunto finito ou infinito enumerável, ou melhor, se existe um conjunto finito ou infinito enumerável {x1, x2, x3, ... } R tal que. X() {x1, x2, x3, ... } . DEF. VARIÁVEL ALEATÓRIA CONTÍNUA. A v.a. X é chamada de CONTÍNUA quando o seu contradomínio é um conjunto infinito não enumerável.")
66
DEF. FUNÇÃO DISTRIBUIÇÃO F(x): A função distribuição ou função distribuição acumulada da v.a. X é definida por F(x) = P(X x). DEF. A f.p. da v.a. X, discreta, representada por P(X=xi) = p(xi) é uma função tal que para X() {x1, x2, x3, ...} A P(X = xi) = p(xi) 0 e DEF. A f.d.p. da v.a. X, contínua, representada por fX(x) é uma função tal que fX(x) 0 e
 = p(xi) é uma função tal que para X() {x1, x2, x3, ...} A P(X = xi) = p(xi) 0 e. DEF. A f.d.p. da v.a. X, contínua, representada por fX(x) é. uma função tal que fX(x) 0 e .")
67
DETERMINAÇÃO da DISTRIBUIÇÃO de PROBABILIDADE da v.a. X
A distribuição de probabilidades de uma v.a. X fica determinada por qualquer das seguintes funções. Usa-se, geralmente, a mais apropriada. A função distribuição, f.d., F(X); A função de probabilidade, f.p., P(X = x) = p(x); A função densidade de probabilidade, f.d.p., fx(x); A função característica X(x) = E(eitx).
; A função de probabilidade, f.p., P(X = x) = p(x); A função densidade de probabilidade, f.d.p., fx(x); A função característica X(x) = E(eitx).")
68
DISTRIBUIÇÕES DE PROBABILIDADES
Distribuição de Bernoulli (v.a. discreta) Uma v.a. X tem uma distribuição de Bernoulli com parâmetro quando assume apenas os valores 1 e 0 com probabilidade e (1 - ), respectivamente, (1 em geral representa sucesso). EXEMPLOS 1) Face de uma moeda: cara ou coroa. 2) Sexo de uma criança: masculino ou feminino. 3) Qualidade de uma peça: perfeita ou defeituosa.
 Uma v.a. X tem uma distribuição de Bernoulli com parâmetro quando assume apenas os valores 1 e 0 com probabilidade e (1 - ), respectivamente, (1 em geral representa sucesso). EXEMPLOS. 1) Face de uma moeda: cara ou coroa. 2) Sexo de uma criança: masculino ou feminino. 3) Qualidade de uma peça: perfeita ou defeituosa.")
69
A f.p. da v.a. Bernoulli é dada por:
P(X = x) = x(1 - )1-x x = 0, < < 1 Os parâmetros de uma variável Bernoulli são: Média = E(X) = Variância 2 = V(X) = (1-) e o desvio padrão = =
 = x(1 - )1-x x = 0, 1 0 < < 1. Os parâmetros de uma variável Bernoulli são: Média = E(X) = Variância 2 = V(X) = (1-) e o desvio padrão = =")
71
2 = V(X) = (1- )[+(1- )] = (1- ) = (1/4)(3/4) = 3/16
EXERCÍCIO ) Qual a esperança e a variância da v.a. X ~ b(1, 1/4)? Solução: = E(X) = = 1.P(X=1)+0.P(X=0) = P(X=1) = = E(X) = ¼ 2 = V(X) = = = (0- )2.P(X=0)+(1- )2.P(X=1) = = 2(1- )+(1- )2 = (1- )[+(1- )] 2 = V(X) = (1- )[+(1- )] = (1- ) = (1/4)(3/4) = 3/16
![2 = V(X) = (1- )[+(1- )] = (1- ) = (1/4)(3/4) = 3/16](http://slideplayer.com.br/slide/49303/1/images/71/%EF%81%B32+%3D+V%28X%29+%3D+%EF%81%B1%281-+%EF%81%B1%29%5B%EF%81%B1%2B%281-+%EF%81%B1%29%5D+%3D+%EF%81%B1%281-+%EF%81%B1%29+%3D+%281%2F4%29%283%2F4%29+%3D+3%2F16.jpg "EXERCÍCIO ) Qual a esperança e a variância da v.a. X ~ b(1, 1/4) Solução: = E(X) = = 1.P(X=1)+0.P(X=0) = P(X=1) = = E(X) = ¼. 2 = V(X) = = = (0- )2.P(X=0)+(1- )2.P(X=1) = = 2(1- )+(1- )2 = (1- )[+(1- )] 2 = V(X) = (1- )[+(1- )] = (1- ) = (1/4)(3/4) = 3/16.")
72
Distribuição Binomial (v.a. discreta)
Uma v.a. Y tem distribuição binomial com parâmetros n e quando assume valores no conjunto {0, 1, 2, 3, ... , n} e a sua f.p. é dada pela expressão: y = 0, 1, ... , n A esperança e a variância de Y são: = E(Y) = n e 2 = V(Y) = n(1- ) A v.a. Binomial corresponde ao número de sucessos em n provas tipo Bernoulli independentes.
 = n e 2 = V(Y) = n(1- ) A v.a. Binomial corresponde ao número de sucessos em n provas tipo Bernoulli independentes.")
73
Exemplos de v.a. Binomial:
Número de peças defeituosas em um lote com n = 20 peças; y = 0, 1, 2, , n = 20 2) Número de meninas em uma família com n = 5 crianças. y = 0, 1, 2, .... , n = 5
 Número de meninas em uma família com n = 5 crianças. y = 0, 1, 2, .... , 5 n = 5.")
75
) De um lote que contém vinte e cinco peças das quais cinco são defeituosas, são escolhidas quatro ao acaso. Seja X o número de defeituosas encontradas na amostra tomada do lote. Escreva a distribuição de probabilidade de X, quando as peças forem escolhidas com reposição. P(D) = 5/25 = 1/5 = n = 4 – Binomial b(4, 1/5)
 = 5/25 = 1/5 = n = 4 – Binomial b(4, 1/5)")
76
) De um lote que contém vinte e cinco peças das quais cinco são defeituosas, são escolhidas quatro ao acaso. Seja X o número de defeituosas encontradas na amostra tomada do lote. Escreva a distribuição de probabilidade de X, quando as peças forem escolhidas sem reposição. P(Y = y) = Hipergeométrica
 = Hipergeométrica.")
78
Exercício a) Calcule a esperança matemática de Y no experimento do exercício – primeira parte. = E(Y) = n = 4x(1/5) = 4/5 b) Calcule o desvio padrão de Y no experimento do – primeira parte. =
 = n = 4x(1/5) = 4/5. b) Calcule o desvio padrão de Y no experimento do – primeira parte. =")
79
Distribuição de Poisson
Uma v.a. X tem distribuição de Poisson quando a sua f.p. é da forma: P(X = x) = x = 0,1,2,3,... e > 0 A esperança e a variância de X são dadas por: = E(X) = e 2 = V(X) = Exemplos: 1) Número de erros tipográficos em uma única página de um livro é P(); no exercício = 1. 2) Número erros de solda em uma placa de circuito impresso é P().
 = x = 0,1,2,3,... e > 0. A esperança e a variância de X são dadas por: = E(X) = e 2 = V(X) = Exemplos: 1) Número de erros tipográficos em uma única página de um livro é P(); no exercício = 1. 2) Número erros de solda em uma placa de circuito impresso é P().")
81
Distribuição Normal (Gaussiana) – v.a. contínua
Uma v.a. X tem distribuição Normal ou Gaussiana quando a sua f.d.p. tem a forma: f(x) = x , e +
 = x , e +")
82
A fig. anterior mostra o gráfico da f. d. p
A fig. anterior mostra o gráfico da f.d.p. f(x) de uma N(20, 1), ou seja, Gaussiana com média = 20 e desvio padrão = 1. A fig. adiante mostra o gráfico da f.d.p. f(x) de uma Normal Padrão, ou seja, N(0, 1).
 de uma N(20, 1), ou seja, Gaussiana com média = 20 e desvio padrão = 1. A fig. adiante mostra o gráfico da f.d.p. f(x) de uma Normal Padrão, ou seja, N(0, 1).")
83
Como é difícil trabalhar-se com todos os membros da família Normal, prefere-se trabalhar com a Normal Reduzida ou Normal Padrão. Esta v.a. é representada por Z e tem a seguinte f.d.p.: f(z) = z P(X < x) = P( < ) = P(Z < z)
 = z P(X < x) = P( < ) = P(Z < z)")
84
Na distribuição Normal a probabilidade da v. a
Na distribuição Normal a probabilidade da v.a. X assumir um valor entre a e b (a < b) é dado por: P(a X b) = A distribuição da v.a. Z tem média e variância iguais a, respectivamente, = 0 e 2 = 1 e essa v.a. é obtida da transformação de X em Z = (X - )/, onde X ~ N(, 2). P(a<X<b) = P( < < ) = P(a< Z < b) P(a< Z < b) =
 é dado por: P(a X b) = A distribuição da v.a. Z tem média e variância iguais a, respectivamente, = 0 e 2 = 1 e essa v.a. é obtida da transformação de X em Z = (X - )/, onde X ~ N(, 2). P(a<X<b) = P( < < ) = P(a< Z < b) P(a< Z < b) =")
85
VERIFICAÇÃO DA NORMALIDADE DE UMA AMOSTRA (dados)
A Gaussianidade de dados, ou seja, o teste da hipótese de que as observações seguem uma distribuição Gaussiana, N(, 2), pode ser feito por meio dos métodos: Kolmogorov-Smirnov; Shapiro-Wilks; Qui-quadrado; e outros. O método de Kolmogorov-Smirnov é geral, usado para a Normal e para as outras distribuições. Já o método de Shapiro-Wilks é especifico para a distribuição Normal. O teste Qui-quadrado é aplicável, somente, quando a mostra tem um tamanho grande. Na prática estes métodos são aplicáveis com uso de programa estatístico (MINITAB, STATGRAPHICS, R, SPSS, etc.
, pode ser feito por meio dos métodos: Kolmogorov-Smirnov; Shapiro-Wilks; Qui-quadrado; e outros. O método de Kolmogorov-Smirnov é geral, usado para a Normal e para as outras distribuições. Já o método de Shapiro-Wilks é especifico para a distribuição Normal. O teste Qui-quadrado é aplicável, somente, quando a mostra tem um tamanho grande. Na prática estes métodos são aplicáveis com uso de programa estatístico (MINITAB, STATGRAPHICS, R, SPSS, etc.")
86
Exemplo 1 Verifique usando os métodos de Kolmogorov-Smirnov e Shapiro-Wilks se a amostra aleatória segue a distribuição Gaussiana. Os dados estão em gramas e correspondem ao peso de determinado produto observado n = 20 vezes. 49, , , , , , , , , , , , , , , , , ,9681 49, ,2500 MTB> STAT, BASIC STATISTICS, NORMALITY TEST (entre com peso, o teste K-S e depois o de R-J).
.")
88
O gráfico de probabilidade normal é apresentado adiante e mostra que o valor-p do teste é p > 0,150 indicando que os dados vêm de uma população (distribuição Gaussiana) conforme o teste de Kolmogorov-Smirnov. Já o teste de Ryan-Joiner similar ao de Shapiro-Wilks (disponível no programa) indicou um valor-p de p > 0,100 confirmando o apontado pelo teste de Kolmogorov-Smirnov.
 indicou um valor-p de p > 0,100 confirmando o apontado pelo teste de Kolmogorov-Smirnov..")
89
Exemplo 2 Escreva a expressão do modelo Gaussiano que pode ser ajustado adequadamente aos dados. f(x) = = x R Exemplo 3 Verifique usando o método de K-S se a a.a. adiante segue a distribuição Exponencial de probabilidades. Os dados estão em mm e correspondem ao comprimento de determinado produto que foi observado n = 30 vezes.
 = = x R. Exemplo 3. Verifique usando o método de K-S se a a.a. adiante segue a distribuição Exponencial de probabilidades. Os dados estão em mm e correspondem ao comprimento de determinado produto que foi observado n = 30 vezes.")
90
Usando o STATGRAPHICS STATG> DESCRIBE, DISTRIBUTIONS, DITRIBUTION FITTING (entra com a coluna com os dados), BOTÃO DA DIREITA DO MOUSE, ANALYSIS OPTIONS (marcar Exponencial), BOTÃO AMARELO DAS OPÇÕES, GOODNESS OF FITTING. 0, , , , , , , , , , , , , , , , , , , , , , , ,7730 0, , , , , ,69364
, BOTÃO DA DIREITA DO MOUSE, ANALYSIS OPTIONS (marcar Exponencial), BOTÃO AMARELO DAS OPÇÕES, GOODNESS OF FITTING. 0, , , ,7629 6, , , , , , , ,0222 3, , , , , ,7070 8, , ,4677 2, , , , , , ,7474 7, ,")
91
RESULTADOS: Estimated Kolmogorov statistic DPLUS = Estimated Kolmogorov statistic DMINUS = Estimated overall statistic DN = Valor-p p = Como o teste de Kolmogorov-Smirnov forneceu valor-p de p = 0, > 0,05 aceitá-se a hipótese de que os dados tenham vindo de uma distribuição exponencial com parâmetro = 9,48758 (média amostral).
.")
92
Exemplo 4 Escreva a expressão do modelo exponencial que pode ser ajustado aos dados do exemplo 3 adequadamente. f(x) = e-x = 9,48758e x > 0 EXERCÍCIOS ) Seja a v.a. X ~ N (10,4). Calcule: a) P(8<X<10). Solução: P(8<X<10) = = P(8<X<10) = 0,341345
 = e-x = 9,48758e x > 0. EXERCÍCIOS ) Seja a v.a. X ~ N (10,4). Calcule: a) P(8<X<10). Solução: P(8<X<10) = = P(8<X<10) = 0,")
93
E, usando o MINITAB o caminho é: Cumulative probability
MTB> CALC/ PROBABILITY DISTRIBUTIONS/ NORMAL Cumulative probability Mean 10 Standard deviation 2 Input constant 10 (depois entra com 8) As saídas são: 0,5 e 0,158655 P(8<X<10) = F(10) – F(8) = 0,5 – 0, = 0,341345
 As saídas são: 0,5 e 0, P(8<X<10) = F(10) – F(8) = 0,5 – 0, = 0,")
94
ESPERANÇA E VARIÂNCIA DE UMA VARIÁVEL ALEATÓRIA - Definições
DEF. Seja uma variável aleatória X, discreta, que assume valores no conjunto {x1, x2, x3, ... , }. Chamamos valor médio ou esperança matemática de X ao valor: DEF. Chamamos VARIÂNCIA da v.a. X ao valor: 2 = V(X) =
 =")
95
DEF. A raiz quadrada da variância da v. a
DEF. A raiz quadrada da variância da v.a. X é denominada desvio-padrão da v.a. X, = Uma relação muito importante é , onde Se a v.a. é contínua tem-se a esperança de X dada por: e a variância por E(x-)2 = 2 =
2 = 2 =")
96
DEF. Se as v.a’s X e Y não são independentes existe uma diferença entre E(X.Y) e E(X).E(Y). Esta diferença é chamada de covariância e definida por: cov(X,Y) = E[(X - E(X)).(Y - E(Y))] cov(X,Y) = E[(X - X).(Y - Y )] e se cov(X,Y) = 0 as v.a’s são chamadas de não-correlacionadas. DEF. A covariância entre as v.a’s X e Y padronizadas é chamada de coeficiente de correlação = E[( )]
 = E[(X - E(X)).(Y - E(Y))] cov(X,Y) = E[(X - X).(Y - Y )] e se cov(X,Y) = 0 as v.a’s são chamadas de não-correlacionadas. DEF. A covariância entre as v.a’s X e Y padronizadas é chamada de coeficiente de correlação. = E[( )]")
97
Exemplo Os dados adiante referem-se ao peso e ao comprimento de uma aste de seção constante. Calcule a correlação entre as variáveis. Peso: Comprimento: O Diagrama de Dispersão (adiante) mostra a tendência da evolução dos dados, ou seja, a forma do relacionamento entre as duas variáveis Peso e Comprimento.
 mostra a tendência da evolução dos dados, ou seja, a forma do relacionamento entre as duas variáveis Peso e Comprimento.")
99
Esse gráfico foi obtido no MINITAB usando o caminho:
MTB> graphs/ scatterplots / with regression E, o valor do coeficiente de correlação estimado é obtido aplicando-se a expressão do estimador de dada por: onde é a média amostral da v.a. X e é a média amostral da v.a. Y

100
O caminho do cálculo no MINITAB é o seguinte:
MTB> STAT/ BASIC STATISTICS/ CORRELATION = 0,997 (correlação alta) Quando se pretende modelar o relacionamento pode-se ajustar o modelo linear: Yi = 0 + 1xi + i i = 1,2, ..., n MTB> STAT / REGRESSION / REGRESSION – RESPONSE Y /PREDICTORS X
 Quando se pretende modelar o relacionamento pode-se ajustar o modelo linear: Yi = 0 + 1xi + i i = 1,2, ..., n. MTB> STAT / REGRESSION / REGRESSION – RESPONSE Y /PREDICTORS X.")
101
A equação de regression estimada é:
y = 0, ,485x Os resultados para os coeficientes são: Predictor Coef E.P t p s = R2 = 99.5%

102
ESTATÍSTICA DESCRITIVA
População, Amostra e Descrição Numérica de Variáveis. POPULAÇÃO Em Estatística denomina-se população alvo a totalidade de elementos que estão sob discussão e dos quais se deseja informação. AMOSTRA ALEATÓRIA Uma a.a. aleatória tomada de uma determinada população é aquela em que os elementos que compõem a população têm uma chance probabilística de pertencer à amostra. Uma amostra aleatória de tamanho n é geralmente representada por [X1, X2, ... , Xn], onde Xi i = 1,2, .. ,n são os valores obtidos para compor a amostra.

103
Na Ciência Estatística a população amostrada corresponde à distribuição de probabilidade correspondente a certa característica (física ou não) e a amostra corresponde a valores medidos dessa característica. Essa distribuição de probabilidade é definida por uma função que depende de parâmetros que são, em geral, desconhecidos. Esses parâmetros devem ser estimados com base nos valores amostrais usando-se seus estimadores.

104
Exemplo 1 O diâmetro de um calibrador tampão liso cilíndrico foi medido em uma máquina de medição universal por meio de um método de medição direta e se obteve uma amostra de n = 10 leituras. A amostra está na tabela adiante. As n = 10 medidas obtidas correspondem à a.a. tomada da característica “diâmetro do calibrador”. A população amostrada corresponde à distribuição de probabilidade da característica X = diâmetro do calibrador. Uma medida física geralmente tem distribuição de probabilidade Gaussiana (Normal), então a população amostrada é a Distribuição de Probabilidade Gaussiana (Normal).
, então a população amostrada é a Distribuição de Probabilidade Gaussiana (Normal).")
105
Número da Leitura Leitura em mm 1 10,0024 2 10,0027 3 10,0028 4 5 10,0021 6 10,0026 7 10,0020 8 9 10,0023 10

106
Gaussianidade Será que os dados vêm de uma distribuição Gaussiana? Aplicação do Teste de Kolmogorov-Smirnov CAMINHO: MTB> STAT/BASIC STATISTICS/NORMALITY TEST/ KOLMOGOROV-SMIRNOV RESULTADOS DO TESTE; valor-p p > 0,150 Os dados vem de distribuição Gaussiana (Normal).
.")
108
Exemplo 2 Seja a a.a. [X1, X2, ... , Xn] de uma característica populacional com f.d.p. Gaussiana com média e variância 2 e representada por N(, 2). A média amostral , a variância amostral s2 e o desvio padrão s são estatísticas. São funções de v.a’s observáveis e não dependem de qualquer parâmetro desconhecido. Veja as expressões das estatísticas citadas: Média amostral = estima o parâmetro Variância e amostral s2 = estima o parâmetro d.p. s = estima o parâmetro
. A média amostral , a variância amostral s2 e o desvio padrão s são estatísticas. São funções de v.a’s observáveis e não dependem de qualquer parâmetro desconhecido. Veja as expressões das estatísticas citadas: Média amostral = estima o parâmetro Variância e amostral s2 = estima o parâmetro. d.p. s = estima o parâmetro ")
109
Exemplo 3 A função da média amostral é estimar a média populacional (parâmetro desconhecido) ; A função da variância amostral s2 é estimar a variância populacional (parâmetro desconhecido) 2; A função do desvio padrão amostral s é estimar o desvio padrão populacional (parâmetro desconhecido) ;
 2; A função do desvio padrão amostral s é estimar o desvio padrão populacional (parâmetro desconhecido) ;")
110
Exemplo 4 Usando os dados da tabela 1 estime o parâmetro correspondente à verdadeira média do diâmetro do calibrador. Caminho no MINITAB: MTB> STAT/BASIC STATISTICS/DISPLAY DESCRIPTIVE STATISTICS = = (10, ,0026) = 10,0025
 = 10,0025.")
111
Exemplo 5 Usando os dados da tabela 1 estime o parâmetro correspondente à verdadeira variância 2 do diâmetro do calibrador. s2 = = s2 = s2 = = 0,

112
Exemplo 6 Usando os dados da tabela 1 estime o parâmetro correspondente ao verdadeiro desvio padrão do diâmetro do calibrador. s = = = s = = 0,000270

113
Exemplo 7 A figura adiante mostra a distribuição de probabilidade da v.a. correspondente ao diâmetro do calibrador da tabela 1.

114
Exemplo 8 As figuras adiante representam as distribuições (populações) correspondentes a uma característica X de um produto fabricado por três empresas. De qual das empresas você compraria o produto considerando que a característica X é fundamental ao funcionamento do produto? Considere que a característica X do produto está especificada por: alvo = 5,0 e tolerância de = 0,5, ou seja, 5,0 ± 0,5.
 correspondentes a uma característica X de um produto fabricado por três empresas. De qual das empresas você compraria o produto considerando que a característica X é fundamental ao funcionamento do produto Considere que a característica X do produto está especificada por: alvo = 5,0 e tolerância de = 0,5, ou seja, 5,0 ± 0,5.")
119
Observe que você deve comprar do fabricante 2 porque o desvio padrão da característica X do produto desse fabricante é 0,05 e, portanto, a produção ficará mais concentrada dentro das especificações. De modo nenhum a compra deve ser feita do fabricante 3, pois a quantidade de defeituosos (fora das especificações) será inaceitavelmente grande. Observe as amplitudes de variação mostradas nos três gráficos.
 será inaceitavelmente grande. Observe as amplitudes de variação mostradas nos três gráficos..")
120
DESCRIÇÃO NUMÉRICA DE VARIÁVEL
A descrição numérica dos dados (amostra) de uma variável aleatória é feita usando as estatísticas seguintes: Estatísticas de Centralidade (Medidas de Tendência Central) e Separatrizes. média amostral (a média amostral estima a verdadeira média populacional ).
 de uma variável aleatória é feita usando as estatísticas seguintes: Estatísticas de Centralidade (Medidas de Tendência Central) e Separatrizes. média amostral (a média amostral estima a verdadeira média populacional ).")
121
Exemplo 1: Duas máquinas produzem peças que estão especificadas com valor nominal = 2 mm e tolerância = 0.2 mm. Foi tomada da 1a. máquina uma amostra com tamanho n = 5 peças que forneceram as seguintes observações: 1,98 2,01 2,02 1,99 e 2,00. Já a 2a. máquina forneceu uma amostra do mesmo tamanho com as observações: 2,00 2,01 2,01 1,98 2,0. Você diria, com base nas amostras, que as duas máquinas estão centradas no alvo das especificações? Tome a sua decisão calculando as médias amostrais.

122
= ,98+2,01+2,02+1,99+ 2,00) = 2,00 = ,00+2,01+2,01+1,98+ 2,00) = 2,00 Sim, as máquinas estão centradas no alvo (valor nominal) das especificações.
 das especificações.")
123
mediana (separa os dados ordenados em duas partes com igual número de termos)
Exemplo 3: Calcule a mediana amostral de cada uma das amostras aleatórias seguintes. Lembre de primeiro ordenar as observações. a) b) 1,5 2,0 1,0 2,5 3,0
 b) 1,5 2,0 1,0 2,5 3,0.")
124
b) Ordenando os termos: 1,0 1,5 2,0 2,5 3,0
Solução: Ordenando os termos: 20, 20, 25, 30, 40 b) Ordenando os termos: 1,0 1,5 2,0 2,5 3,0 c) xi fi 20 3 25 4 30 2
 Ordenando os termos: 1,0 1,5 2,0 2,5 3,0. c) xi. fi")
125
EXERCÍCIOS 1) A mediana é uma separatriz, além de uma medida de centralidade. Então, o que faz a separatriz? R: Separa as observações ordenadas em duas partes com igual número de termos. 2) Os quartis são medidas de posição (ordem), ou ainda, separatrizes. Quantos são os quartis e o qual a sua função? R: Os quartis são três: Q1 é o quartil inferior, Q2 é a mediana e Q3 é o quartil superior. A função dos três quartis é separar os dados ordenados em quatro partes com igual número de termos; deste modo 25% das observações são inferiores a Q1, 50% são nferiores a Q2 = e 75% são inferiores a Q3.
 Os quartis são medidas de posição (ordem), ou ainda, separatrizes. Quantos são os quartis e o qual a sua função R: Os quartis são três: Q1 é o quartil inferior, Q2 é a mediana e Q3 é o quartil superior. A função dos três quartis é separar os dados ordenados em quatro partes com igual número de termos; deste modo 25% das observações são inferiores a Q1, 50% são nferiores a Q2 = e 75% são inferiores a Q3.")
126
3) A descrição dos dados de uma amostra forneceu os seguintes valores para os quartis: Q1 = 7, Q2 = 10 e Q3 = 13. Interprete o significado de cada um dos quartis quanto à população de onde vieram os dados. 4) Os percentís são medidas de posição (ordem), ou ainda, separatrizes. Qual a sua função? R: Os percentís são em número de 99 e têm por função separar os dados ordenados em 100 partes com igual número de termos.
 Os percentís são medidas de posição (ordem), ou ainda, separatrizes. Qual a sua função R: Os percentís são em número de 99 e têm por função separar os dados ordenados em 100 partes com igual número de termos.")
127
Exercício Descreva os dados do diâmetro do calibrador que estão na tabela 1 do exemplo 1. Solução: usa-se um pacote estatístico (MINITAB p.ex.) Descriptive Statistics: diam_calib Variável Média E.P D.P Variância Min Q1 diam_calib E Variable Mediana Q Max. Amplitude diam_calib

128
Q1= Média = 10,0025 Mediana = 10,0026 Q3 = 10,0027 Máximo = 10,0028 Amplitude = 0,0220 Desvio padrão = 0,000270 Caminho no Minitab: STAT BASIC STATISCS DISPLAY DESCRIPTIVES ...

129
Exercício 3: Os dados abaixo correspondem a uma amostra aleatória do diâmetro do furo (em mm) para fixação de certo equipamento aeronáutico. Descreva os dados numericamente e graficamente. 120,5 120,9 120,3 121,3 120,4 120,2 120,1 120,5 120,7 121,1 120,9 120,8 120,3 120,2 120,3 120,4 120,5 120,2 120,8 120,9 120,5 120,6 120,4 120,7 120,5 120,6 120,5 120,7 120,6 120,5
 para fixação de certo equipamento aeronáutico. Descreva os dados numericamente e graficamente. 120,5 120,9 120,3 121,3 120,4 120,2 120,1 120,5 120,7 121,1. 120,9 120,8 120,3 120,2 120,3 120,4 120,5 120,2 120,8 120,9. 120,5 120,6 120,4 120,7 120,5 120,6 120,5 120,7 120,6 120,5.")
130
STAT > BASIC STATISCS >DISPLAY > DESCRIPTIVES ...
Solução: Caminho no Minitab: STAT > BASIC STATISCS >DISPLAY > DESCRIPTIVES ... Descrição numérica consiste em calcular as estatísticas descritivas: média, desvio padrão, variância, etc. Variable Mean SE Mean StDev Variance CoefVar Minimum Q1 Median diam_furo 120,56 0, , , , , , ,50 Variable Q3 Maximum Range diam_furo 120, , ,20

131
Média = 120,56 Desvio padrão s = = 0,280 Erro padrão da média EP = Variância = s2 = = 0,0783

132
Coef. de variação = = 0,23% Então, o desvio padrão é 0,23% da média. O valor mínimo x(1) = 120,10 O primeiro quartil Q1 = 120,38 Significa que 25% dos termos são inferiores a 120,38 Posição de Q1 é = , então Q1 está entre o 70. e o 80. termos ordenados.
 = 120,10. O primeiro quartil Q1 = 120,38. Significa que 25% dos termos são inferiores a 120,38. Posição de Q1 é = , então Q1 está entre o 70. e o 80. termos ordenados.")
133
A mediana = 120,5 Posição da mediana n/2 Se n é impar a mediana é o termo central (termos ordenados). Se n é par a mediana é a média aritmética dos dois termos centrais (termos ordenados). O segundo quartil Q2 = = 120,5 O terceiro quartil Q3 = 120,73 A posição de Q3 é Então Q3 situa-se entre o 220. e o 230. termos.
. O segundo quartil Q2 = = 120,5. O terceiro quartil Q3 = 120,73. A posição de Q3 é. Então Q3 situa-se entre o 220. e o 230. termos.")
134
O valor máximo é x(n) = 121,30 A amplitude dos dados é R = x(n) - x(1) = 121,30 – 120,10 R = 1,20
 = 121,30 A amplitude dos dados é R = x(n) - x(1) = 121,30 – 120,10 R = 1,20")
135
Descrição gráfica consiste em construir o histograma dos dados.
Caminho no MINITAB: GRAPH HISTOGRAM

136
2) O tempo de vida até falhar, em horas, de um componente eletrônico sujeito a um teste de durabilidade acelerado é mostrado abaixo para uma amostra com tamanho n = 40. Para acelerar a falha no teste, as unidades experimentais são testadas sob uma temperatura elevada.

137
a) Calcule a média amostral.
b) Calcule a variância amostral. c) Calcule o desvio padrão amostral. d) O erro padrão da média. e) Calcule a variância. f) Calcule o coeficiente de variação. g) Calcule a mediana e os quartis. h) Calcule a amplitude dos dados. i) Qual a finalidade das estatísticas que você calculou nos itens anteriores. j) Construa o histograma. E ajuste a curva normal aos dados, use qualquer programa estatístico.
 Calcule a variância amostral. c) Calcule o desvio padrão amostral. d) O erro padrão da média. e) Calcule a variância. f) Calcule o coeficiente de variação. g) Calcule a mediana e os quartis. h) Calcule a amplitude dos dados. i) Qual a finalidade das estatísticas que você calculou nos itens anteriores. j) Construa o histograma. E ajuste a curva normal aos dados, use qualquer programa estatístico.")
138
Usando o MINITAB com o caminho:
Solução: Usando o MINITAB com o caminho: MTB> STAT>BASIC STATISTICS>DISPLAY DESCRIP Resultados: Variable Mean SE Mean StDev Var. CoefVar Minimum Q1 Median tempoVIDA 130,00 1, , ,54 6,86% , , ,00 Variable Q3 Maximum Range tempoVIDA 135, , ,00

139
Média = ( … +126) = 130,00 Desvio padrão s = = 8,92 Erro padrão da média EP = = Variância s2 = = 79,54 Coef. de Variação cv = = = 6,86%

140
Mediana = 128 (N = 40, então a mediana é a media aritmética dos dois termos centrais: 190 e 200);
10. Quartil Q1 = (25% dos termos são inferiores a 124) 30. Quartil Q3 = 135,25 (25% dos termos são superiores a 135,25) Amplitude R = x(n) – x(1) = 160 – 118 = 42 i) A finalidade das estatísticas calculadas é estimar (avaliar) os verdadeiros parâmetros.
 30. Quartil Q3 = 135,25 (25% dos termos são superiores a 135,25) Amplitude R = x(n) – x(1) = 160 – 118 = 42. i) A finalidade das estatísticas calculadas é estimar (avaliar) os verdadeiros parâmetros.")
141
f) Histograma e ajuste a curva normal
Solução: usando o MINITAB com o caminho: STAT BASIC STATISTICS NORMALITY TEST

142
O ajuste da Curva Normal foi aceito pois no teste de Kolmogorov-Smirnov o valor-p foi p = 0,115 > 0,05.

143
3) Os dados adiante são leituras do rendimento de um processo químico em dias sucessivos (leia da esquerda para a direita). Faça o histograma dos dados, comente o aspecto do histograma e verifique se o histograma lembra alguma distribuição de probabilidade conhecida. E, ainda, descreva numericamente os dados, calculando as estatísticas listadas adiante. a) Calcule a media amostral. b) Calcule a variância amostral. c) Calcule o desvio padrão amostral. d) Calcule a mediana e os quartis. e) Qual a finalidade das estatísticas que você calculou nos itens anteriores. Escreva para que serve cada uma delas.
 Calcule a media amostral. b) Calcule a variância amostral. c) Calcule o desvio padrão amostral. d) Calcule a mediana e os quartis. e) Qual a finalidade das estatísticas que você calculou nos itens anteriores. Escreva para que serve cada uma delas.")
144
94,1 87,3 94,1 92,4 84,6 85,4 93,2 84,1 92,1 90,683,6 86,6 90,6 90,1 96,4 89,1 85,4 91,7 91,4 95,288,2 88,8 89,7 87,5 88,2 86,1 86,4 86,4 87,6 84,286,1 94,3 85,0 85,1 85,1 85,1 95,1 93,2 84,9 84,089,6 90,5 90,0 86,7 87,3 93,7 90,0 95,6 92,4 83,089,6 87,7 90,1 88,3 87,3 95,3 90,3 90,6 94,3 84,1 86,6 94,1 93,1 89,4 97,3 83,7 91,2 97,8 94,6 88,696,8 82,9 86,1 93,1 96,3 84,1 94,4 87,3 90,4 86,494,7 82,6 96,1 86,4 89,1 87,6 91,1 83,1 98,0 84,5

145
Solução: Usando o MINITAB no caminho
MTB> STAT> BASIC STATISTICS> DISPLAY DESCR.. Variable Mean SE Mean StDev Variance CoefVar Minimum Q1 Median RENDpq 89, , , , , , ,1 89,250 Variable Q3 Maximum Range RENDpq ,1 98, ,400 A finalidade dessas estatísticas é estimar os verdadeiros parâmetros.

146
Média amostral = 89,476 A verdadeira média do rendimento médio é um parâmetro desconhecido e estimado pela média amostral em 89,476. Variância amostral s2 = = 17,287. A verdadeira variância do rendimento médio é um parâmetro desconhecido e estimado pela variância amostral em 17,287. Desvio padrão amostral s = = 4,158

147
O verdadeiro desvio padrão do rendimento é um parâmetro desconhecido, mas estimado pelo desvio padrão amostral s = 4,158. A mediana amostral é ,250 A verdadeira mediana do rendimento é um parâmetro desconhecido, mas estimado pela mediana amostral 89,250. Então, entende-se que 50% dos valores do rendimento são inferiores ao rendimento de 89,250.

148
O primeiro quartil é Q1 = 86,1 O valor de Q1 é determinado a partir da posição dessa separatriz Então, o primeiro quartil está entre o 220. termo (86,1) e o 230. termo (86,1) ordenados. Logo, ele é 86,1. Isto significa que 25% dos termos são inferiores a 86,1 e, consequentemente, 75% são superiores.
 e o 230. termo (86,1) ordenados. Logo, ele é 86,1. Isto significa que 25% dos termos são inferiores a 86,1 e, consequentemente, 75% são superiores.")
149
O terceiro quartil é Q3 = 93,1 O valor de Q3 é determinado a partir da posição dessa separatriz Então, o terceiro quartil está entre o 670. termo (93,1) e o 680. termo (93,1) ordenados. Logo, ele é 93,1. Isto significa que 25% dos termos são superiores a 93,1 e, consequentemente, 75% dos termos são inferiores. A finalidade de cada estatística calculada é avaliar (estimar) o parâmetro verdadeiro (populacional) desconhecido.
 e o 680. termo (93,1) ordenados. Logo, ele é 93,1. Isto significa que 25% dos termos são superiores a 93,1 e, consequentemente, 75% dos termos são inferiores. A finalidade de cada estatística calculada é avaliar (estimar) o parâmetro verdadeiro (populacional) desconhecido.")
150
Ajustamento de Um modelo Probabilístico aos Dados
Seja agora o problema de se ajustar um modelo de probabilidade aos dados adiante. Isto deve ser feito por programa estatístico computacional. Usando o MINITAB o caminho é: GRAPH PROBABILITY PLOT Dados: (Amostra de uma distribuição log-normal) 3, , , ,17336 2, , , ,19817 3, , , ,06446 3, , , ,62691 3, , , ,94858
 3, , , , , , , , , , , , , , , , , , , ,")
151
Vamos examinar o histograma dos dados:

152
Ajuste do Modelo Normal p = 0,597 > 0,05 (aceito)
")
153
Modelo Lognormal p = 0,962 > 0,05 (melhor modelo)
")
154
5. Estimação de Parâmetros
Introdução Seja a a.a. [X1, X2, ... , Xn] obtida de uma distribuição de probabilidade que corresponde a população amostrada. Então, essa amostra trás informações sobre os parâmetros da distribuição (população) e é possível estimar esses parâmetros usando as informações da amostra. ESTIMADOR Um estimador é uma estatística (função conhecida de v.a’s observáveis que também é uma v.a.) cujos valores são usados para estimar alguma função do parâmetro .
 e é possível estimar esses parâmetros usando as informações da amostra. ESTIMADOR. Um estimador é uma estatística (função conhecida de v.a’s observáveis que também é uma v.a.) cujos valores são usados para estimar alguma função do parâmetro .")
155
Exemplo 1 A estimação da média populacional (parâmetro) é feita usando-se o estimador mais adequado, que é a média amostral Este estimador (estatística) tem propriedades excelentes, tais como: é suficiente, é consistente, é eficiente e é não-viciado, ou seja, ele é UMVU.
 tem propriedades excelentes, tais como: é suficiente, é consistente, é eficiente e é não-viciado, ou seja, ele é UMVU.")
156
Pergunta importante: Precisão e acurácia significa a mesma coisa? Seja a a.a. [x1, x2, ... , xn] obtida de uma distribuição de probabilidade que corresponde a população amostrada. Então, essa amostra trás informações sobre os parâmetros da distribuição (população) e é possível estimar esses parâmetros usando as informações da amostra. Precisão mede a diferença entre a estimativa que avalia o parâmetro e a média da amostra, ou seja, Precisão tem a ver com dispersão dos dados. Acurácia mede a diferença entre a estimativa que avalia o parâmetro e o próprio parâmetro estimado, ou seja, -
 e é possível estimar esses parâmetros usando as informações da amostra. Precisão mede a diferença entre a estimativa que avalia o parâmetro e a média da amostra, ou seja, . Precisão tem a ver com dispersão dos dados. Acurácia mede a diferença entre a estimativa que avalia o parâmetro e o próprio parâmetro estimado, ou seja, - ")
157
Um estimador suficiente resume todas as informações que a a. a
Um estimador suficiente resume todas as informações que a a.a. trás, este resumo pode ser observado na estatística que agrega todas as informações; Já um estimador consistente é aquele que à medida que o tamanho da amostra (n) aumenta, a estimativa obtida se aproxima do verdadeiro parâmetro populacional ; Um estimador eficiente significa que as estimativas fornecidas por ele possuem a menor variância entre as de todos os possíveis estimadores do parâmetro; E, finalmente, um estimador não-viciado é tal que a esperança matemática (média) dele é o próprio parâmetro que ele está estimando, ou seja, E(T) = .
 aumenta, a estimativa obtida se aproxima do verdadeiro parâmetro populacional ; Um estimador eficiente significa que as estimativas fornecidas por ele possuem a menor variância entre as de todos os possíveis estimadores do parâmetro; E, finalmente, um estimador não-viciado é tal que a esperança matemática (média) dele é o próprio parâmetro que ele está estimando, ou seja, E(T) = .")
158
ESTIMATIVA É o valor numérico obtido para o estimador com os dados da amostra. TIPOS ESTIMAÇÃO Existem dois tipos de estimação. O que fornece uma estimativa PONTUAL, e que nesse caso corresponde a um único valor para a estimativa. E o que fornece uma estimativa por INTERVALO, nesse caso tem-se um limite inferior e um limite superior para a variação do parâmetro com certo nível de confiança. ESTIMAÇÃO PONTUAL Seja a abordagem desse tema por meio de um exemplo:

159
Exemplo 2 Seja a a.a. das cinco leituras do diâmetro do calibrador listada na tabela adiante. A estimativa pontual do verdadeiro diâmetro médio do calibrador é obtida usando-se o estimador: = 10,0028 que forneceu a estimativa pontual de 10,0028. b) A estimativa pontual da variância 2 é dada pelo estimador: s2 = = 5.9E-7
 A estimativa pontual da variância 2 é dada pelo estimador: s2 = = 5.9E-7.")
160
que forneceu com os valores da amostra a estimativa pontual de s2 = 5
que forneceu com os valores da amostra a estimativa pontual de s2 = 5.9E-7. c) A estimativa pontual do desvio padrão é dada pelo estimador: s = = 0, que forneceu com os valores da amostra a estimativa pontual s = 0,
 A estimativa pontual do desvio padrão é dada pelo estimador: s = = 0, que forneceu com os valores da amostra a estimativa pontual s = 0,")
161
Os dados analisados são: Medidas do Diâmetro do Calibrador
Número da leitura Medidas do Diâmetro do Calibrador 1 10,0024 2 10,0027 3 10,0041 4 5 10,0021

162
ESTIMAÇÃO POR INTERVALO:
A estimação por intervalo consiste na construção de um intervalo de confiança em torno da estimativa pontual, de modo que esse tenha uma probabilidade fixada do intervalo cobrir o verdadeiro valor do parâmetro. Geralmente, o que se faz na construção do intervalo é somar e subtrair à estimativa pontual um múltiplo do erro padrão da estatística usada na estimação, de modo que se tenha certa probabilidade de cobrir o intervalo.

163
INTERVALO DE CONFIANÇA PARA A
MÉDIA POPULACIONAL Quando os dados vêm de uma distribuição Normal, ou ainda, quando n > 30 e se for conhecido tem-se a seguinte expressão para o intervalo de confiança de nível (1 - ) para a média : onde
 para a média : onde.")
164
Este intervalo é construído com base na estatística:
A v.a. z tem uma distribuição de probabilidade Normal Padrão, ou seja, N(0, 1). Sua f.d.p. é: f(z) =
. Sua f.d.p. é: f(z) =")
166
Quando os dados vêm de uma distribuição Normal (Gaussiana) e for desconhecido, tem-se a seguinte expressão para o intervalo de confiança de nível (1 - ) para a média : onde Este intervalo é construído com base na estatística:

167
A f.d.p. da distribuição “t” de Student tem o seguinte gráfico no caso do número de G.L. ser n – 1 = 5 – 1 = 4

168
Exercícios Seja a amostra aleatória dos diâmetros de esferas de rolamento com tamanho n = 5, [2,0; 2,1; 2,0; 2,2; 2,1]. Os diâmetros estão em milímetros. Estime por ponto a média do processo de produção desse item. = = = 2,08

169
2) Estime por ponto o desvio padrão da amostra do ex. 1.
 Estime por ponto o desvio padrão da amostra do ex. 1.")
170
3) Estime o erro padrão da estimativa do exercício 1.
EP = = = = 0,0374 4) Estime por intervalo a média do processo de produção do diâmetro considerando o nível de confiança de 95%. =
 Estime por intervalo a média do processo de produção do diâmetro considerando o nível de confiança de 95%. =")
171
Mas, será que os dados vêm de uma distribuição Gaussiana?
MT> STAT>BASIC STATISTICS> NORMALITY TEST Valor-p p > 0,150 Aceito a hipotese nula dos Dados serem Gaussianos

172
Então, faz-se as contas:
O cálculo do escore da distribuição “t” de Student com = n – 1 = 4 graus de liberdade é: MTB> CALC> PROBABILITY DISTRIBUTIONS> t > Inverse Cumulative Probability P( T <= t ) t 0, ,77645 Então, faz-se as contas: P(2,08-2, ,0374< < 2,08 + 2, ,0374) = 0,95 P(1,97607 < < 2,18389) = 0,95 Então, IC de nível 95% é: [1, ; 2,18389]
 t. 0,025 -2, Então, faz-se as contas: P(2,08-2, ,0374< < 2,08 + 2, ,0374) = 0,95. P(1,97607 < < 2,18389) = 0,95. Então, IC de nível 95% é: [1, ; 2,18389]")
173
Intervalo de Confiança Usando o MINITAB:
MTB> STAT> BASIC STATISTICS> 1-Sample t One-Sample T: diamESFF Test of mu = 2 vs not = 2 Variable N Mean StDev SE Mean % CI T p diamESFF ,080 0, , (1,97611; 2,18389) 2,14 0,099 Este comando faz também o teste de H0 : = 0 = 2 Decisão: Aceita-se H0 pois o valor-p é p = 0,099 > 0,05.
 2,14 0,099. Este comando faz também o teste de H0 : = 0 = 2. Decisão: Aceita-se H0 pois o valor-p é p = 0,099 > 0,05.")
174
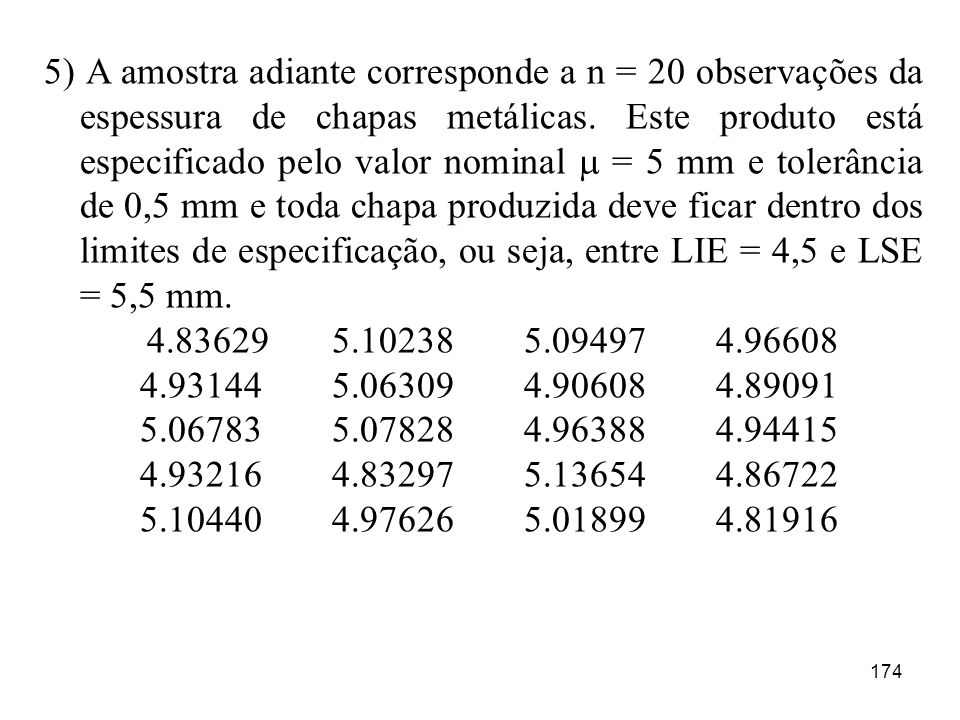
5) A amostra adiante corresponde a n = 20 observações da espessura de chapas metálicas. Este produto está especificado pelo valor nominal = 5 mm e tolerância de 0,5 mm e toda chapa produzida deve ficar dentro dos limites de especificação, ou seja, entre LIE = 4,5 e LSE = 5,5 mm.
175
a) Verifique se os dados vêm de uma distribuição Normal.
Usando o MINITAB no caminho: MTB> STAT> BASIC STATISTICS> NORMALITY TEST

176
Como o valor-p é p > 0,150 aceita-se a Gaussianidade.
b) Determine o intervalo de confiança de nível 1 - = 0,95 para a média e verifique se ele está contido no intervalo da especificação. One-Sample T: ESP_CHAPA Test of mu = 5 vs not = 5 Variable N Mean StDev SE Mean % CI t p ESP_CHAPA , , , (4,92931; 5,02400) -1,03 0,315 LIE = 4,5 e LSE = 5,5 logo o IC não está dentro da amplitude de especificação, existe uma parcela de não-conformes abaixo de 4,5.
 Determine o intervalo de confiança de nível 1 - = 0,95 para a média e verifique se ele está contido no intervalo da especificação. One-Sample T: ESP_CHAPA. Test of mu = 5 vs not = 5. Variable N Mean StDev SE Mean 95% CI t p. ESP_CHAPA 20 4, , ,02262 (4,92931; 5,02400) -1,03 0,315. LIE = 4,5 e LSE = 5,5 logo o IC não está dentro da amplitude de especificação, existe uma parcela de não-conformes abaixo de 4,5.")
177
c) Teste a hipótese de que a espessura média das chapas seja igual ao alvo das especificações.
Solução: H0 = = 0 = 5 (hipótese nula) H1 = 5 Estatística do teste: t = ~ tn-1 Então, t = = -1,03 ~ t19 Então, determina-se o valor-p dessa estatística.
 H1 = 5. Estatística do teste: t = ~ tn-1. Então, t = = -1,03 ~ t19. Então, determina-se o valor-p dessa estatística.")
178
No MINITAB com o caminho:
MTB> CALC>PROBABILITY DISTRIBUTIONS> t Valor-p p = 2x0, = 0,315 > 0,05 Aceitá-se H0 e o processo de produção da chapa tem média estatisticamente igual ao alvo do processo. Verifique o desempenho do processo de produção analisando a capacidade do processo no MINITAB CAMINHO: MTB> STAT>QUALITY TOOLS>CAPABILITY ANALYSIS> NORMAL

180
Analisando os números da capacidade do processo:
= 1, Razão entre as amplitudes de especificação e do processo. ( é 4,976) Com esta capacidade (capability) de 1,50 o número de defeituosos esperado é de: 9,95 10 ppm
 Com esta capacidade (capability) de 1,50 o número de defeituosos esperado é de: 9,95 10 ppm.")
181
6) Suponha que outra empresa produz a mesma chapa e uma descrição de uma a.a. de n = 20 dessas chapas produziu: = 4,8 e s = 0,1021. Verifique se os dois processos são equivalentes na média. Hipótese nula a ser testada H0 : X = y Û X - y = 0 Estatística do teste: t = ~ tn1+n2-2 onde sp =

182
Cálculo da estatística do teste:
t = = = 5,476 ~ t38 Sp = = 0,101626 Valor-p p = 0,0000 < 0,05 Rejeita-se a hipótese H0.

183
E, se queremos fazer direto no MINITAB? Usa-se o comando:
MTB> STAT> BASIC STATISTICS> 2-sample t E, entra-se com os valores das médias e desvios padrões ou com os dados, conforme o caso. Resultados: Two-Sample T-Test and CI Sample N Mean StDev SE Mean Difference = mu (1) - mu (2) Estimate for difference: 95% CI for difference: ( ; ) T-Test of difference = 0 (vs not =): T-Value = P-Value = DF = 38 Both use Pooled StDev = – REJEITA-SE H0
 - mu (2) Estimate for difference: % CI for difference: ( ; ) T-Test of difference = 0 (vs not =): T-Value = 5.48 P-Value = DF = 38. Both use Pooled StDev = – REJEITA-SE H0.")
184
ANÁLISE DA VARIÂNCIA Quando se faz um experimento que envolve amostras de mais de dois grupos (populações) e se necessita testar a hipótese nula: H0: 1 = 2 = .... = k = contra H1: pelo menos uma das médias é diferente das demais, aplica-se o método conhecido como Análise da Variância, detalhado a seguir.

185
EXEMPLO Os dados adiante correspondem aos resultados de um experimento onde 4 tratamentos de plasma são comparados quanto ao tempo de coagulação. Amostras de plasma de 32 indivíduos foram alocadas aos 4 tratamentos numa ordem aleatória (experimento completamente casualizado). Faça uma análise estatística com a finalidade de verificar se existe diferença estatisticamente significativa entre os tratamentos.
. Faça uma análise estatística com a finalidade de verificar se existe diferença estatisticamente significativa entre os tratamentos.")
186
T1 T2 T3 T4 8.4 12.8 9.6 9.8 8.6 8.9 7.9 9.4 15.2 9.1 8.8 8.2 9.9 9.0 8.1 12.9 11.2 8.5 9.2 12.2 14.4 12.0 10.9 10.4 10.0
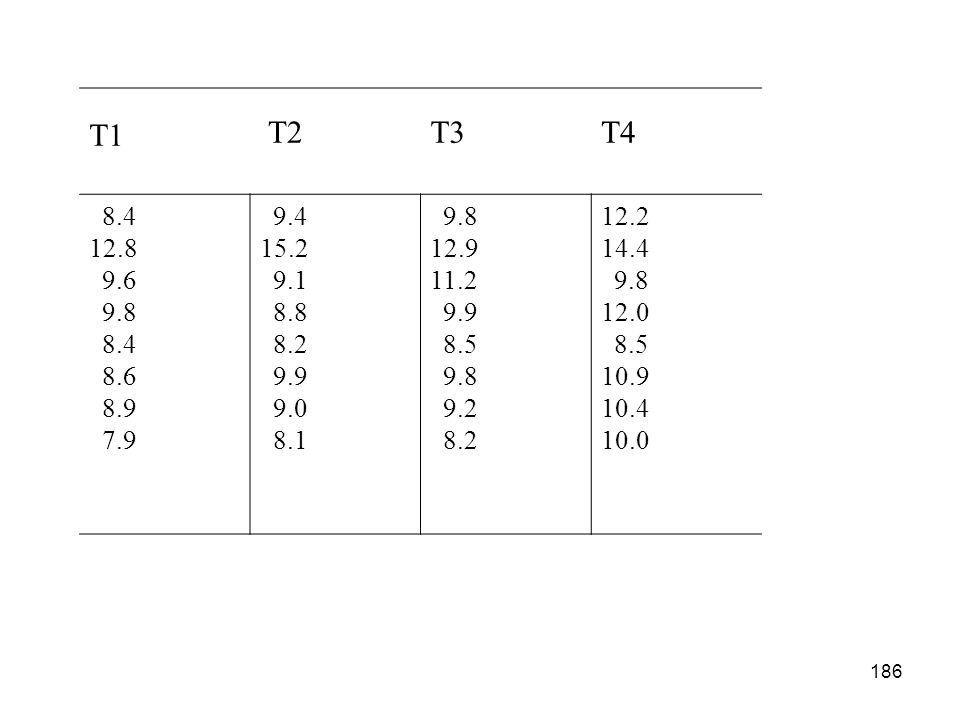
187
MTB> STAT>ANOVA>ONEWAY ANOVA Resultados:
SOLUÇÃO: MTB> STAT>ANOVA>ONEWAY ANOVA Resultados: One-way ANOVA: REPOSTA versus TRAT Source DF SS MS F p TRAT Error Total S = R-Sq = 12.31% R-Sq(adj) = 2.91% H0: 1 = 2 = 3 = 4 Conclusão: Não existe diferença entre as médias, aceitá-se H0, ou seja os tratamentos produzem a mesma média.
 = 2.91% H0: 1 = 2 = 3 = 4. Conclusão: Não existe diferença entre as médias, aceitá-se H0, ou seja os tratamentos produzem a mesma média.")
188
EXEMPLO Uma fábrica de papel usado para fazer sacolas de papel está interessada em melhorar a resistência do papel à tensão. A engenharia de produto da empresa imagina que a resistência à tensão depende da concentração da madeira de lei na polpa e que a faixa prática de interesse dessa concentração está entre 5% e 20%. Foi feito então um experimento nos seguintes níveis de concentração: 5%, 10%, 15% e 20% e mediu-se a resistência à tensão em seis sacolas de prova em cada nível. Os resultados estão adiante. Faça uma Análise da Variância.

189
Resistência à Tensão (psi)
5% 10% 15% 20% 7 12 14 19 8 17 18 25 15 13 22 11 23 9 16 10 20

190
A aplicação da ANOVA exige Gaussianidade dos dados.
Isto é verificado com base nos resíduos do ajuste do moedelo para a resposta (resistência): yij = + i + ij onde: yij é a resposta medida; é a média geral; i é o efeito do nível i fator (conc. da madeira de lei); ij é o erro aleatório -componente estocástica do mod. ij ~ N(0, 2) (suposições do modelo – verificar)
: yij = + i + ij. onde: yij é a resposta medida; é a média geral; i é o efeito do nível i fator (conc. da madeira de lei); ij é o erro aleatório -componente estocástica do mod. ij ~ N(0, 2) (suposições do modelo – verificar)")
191
Testando a hipótese nula H0: 1 = 2 = 2 = 4
One-way ANOVA: concentração versus nível Source DF SS MS F P nível Error Total S = R-Sq = 74.62% R-Sq(adj) = 70.82% Rejeitá-se a hipótese nula, pois p = 0,000 < 0,05.
 = 70.82% Rejeitá-se a hipótese nula, pois p = 0,000 < 0,05.")
192
Individual 95% CIs For Mean Based on
Pooled StDev Level N Mean StDev 5% (----*----) 10% (----*-----) 15% (----*-----) 20% (-----*----) Pooled StDev = 2.551 Tukey 95% Simultaneous Confidence Intervals All Pairwise Comparisons Observa-se que 10%, 15% e 20% praticamente estão empatados. O nível de 5% é diferente dos demais.
 10% (----*-----) 15% (----*-----) 20% (-----*----) Pooled StDev = Tukey 95% Simultaneous Confidence Intervals. All Pairwise Comparisons. Observa-se que 10%, 15% e 20% praticamente estão empatados. O nível de 5% é diferente dos demais.")
194
Verificando as suposições: Gaussianidade, homogeneidade da variância e independência dos resíduos.
MTB> STAT> BASIC STATISTICS> NORMALITY TEST

195
Homogeneidade de variância:
Como o valor-p foi de p > 0,150 > 0,05 aceitá-se a hipótese de Gaussianidade para os resíduos. Homogeneidade de variância: Test for Equal Variances: RESI1 versus nível Bartlett's Test (normal distribution) Test statistic = 1.14; p-value = 0.769 Levene's Test (any continuous distribution) Test statistic = 0.60; p-value = 0.623 Aceitá-se a hipótese de homogeneidade na variância H0: 12 = 22 = 32 = pois p > 0,05
 Test statistic = 1.14; p-value = Levene s Test (any continuous distribution) Test statistic = 0.60; p-value = Aceitá-se a hipótese de homogeneidade na variância. H0: 12 = 22 = 32 = 42 pois p > 0,05.")
196
6. AMOSTRAGEM Suponha que você deseja estimar a verdadeira média da espessura de uma chapa metálica. Qual será o tamanho adequado, n, da amostra? Tamanho da Amostra com Erro Especificado e Conhecido Deve ser fixado o nível de confiança: 1 - Deve ser fixado o erro de | | = e n = onde é o escore da N(0, 1) correspondente a
 correspondente a.")
197
Exemplo Suponha que no caso da espessura da chapa foi fixado um erro de e = 0,05 e um nível de confiança de 95%. Então: Com 1 - = 0,95 tem-se /2 = 0,025 e z0,025 = 1,96 MTB> CALC>PROBABILITY DISTRIBUTIONS> NORMAL>INVERSE CUMULATIVE PROBABILITY Normal with mean = 0 and standard deviation = 1 P( X <= x ) x n = = = 15,675 = 16
 x n = = = 15,675 = 16.")
198
Tamanho da Amostra com Erro Especificado e Desconhecido
Neste caso há necessidade de se estimar o desvio padrão . Assim, toma-se uma amostra piloto de tamanho n0 e estima-se o desvio padrão s0. Usa-se a expressão para o tamanho n = Então, se n > n0 tudo bem e recalcula-se o erro e; se n < n0 toma-se mais n0 – n observações adicionais.

199
A descrição da amostra piloto forneceu:
Exemplo Suponha que se deseja testar a hipótese de que o diâmetro médio de um pino tem média de 10 mm. Qual o tamanho da amostra, supondo que o desvio padrão é desconhecido, o nível de confiança é 95% e a precisão de 0,01. Solução: Como o desvio padrão é desconhecido toma-se uma amostra piloto de tamanho n0 = 5. Os valores são: 10,1; 10,05; 9,98; 9, A descrição da amostra piloto forneceu: MTB> STAT> BASIC STATISTICS> DISPLAY .. Variable N Mean SE Mean StDev pino

200
MTB> CALC> PROBABILITY DISTRIBUTIONS> t
Dimensionando o tamanho da amostra com base nas informações da amostra piloto: n = s0 = 0,0678 Escore tn0;/2 MTB> CALC> PROBABILITY DISTRIBUTIONS> t Inverse Cumulative Distribution Function Student's t distribution with 4 DF P( X <= x ) x
 x")
201
n = = = 166 Então, como tomamos n0 = 5, devemos tomar outras 161 observações adicionais. Por que deu um tamanho de amostra tão grande? Devido o nível de confiança de 95% (poderia ser menor – 90%) e devido a precisão de 0,01.
 e devido a precisão de 0,01.")
202
PLANOS DE AMOSTRAGEM Uma das maiores aplicações da estatística no controle de qualidade de produtos está na amostragem para aceitação de lotes. Muitas vezes as empresas recebem carregamentos ou lotes de bens (produtos) e fazem amostragem desses carregamentos com a finalidade de aceitar ou rejeitar o carregamento ou lote todo. Essa decisão é conhecida como sentenciamento do lote. No início da aplicação do controle estatístico, de qualidade, nas décadas de 30 e 40, a amostragem de aceitação era usada, principalmente, para inspeção de entrada (recebimento) de produtos.
 e fazem amostragem desses carregamentos com a finalidade de aceitar ou rejeitar o carregamento ou lote todo. Essa decisão é conhecida como sentenciamento do lote. No início da aplicação do controle estatístico, de qualidade, nas décadas de 30 e 40, a amostragem de aceitação era usada, principalmente, para inspeção de entrada (recebimento) de produtos.")
203
Nos últimos anos passou-se a trabalhar com os fornecedores a fim de fazer com que melhorassem os seus processos de produção. Este aperfeiçoamento dos processos poderia ser alcançado por meio de CEP, DOE e outras técnicas estatísticas. Assim, conseguir uma qualidade assegurada pareceu ser melhor do que a amostragem de aceitação. Contudo, estas técnicas continuam sendo necessárias e usadas.

204
6.3- Plano de Amostragem de Aceitação por Variável
Existem dois tipos de planos por variável: 1.) Planos que controlam a fração de defeituosos (ou não conformes) do lote ou do processo; 2.) Planos que controlam um parâmetro do lote ou do processo, em geral a média. Suponha um plano de amostragem de variáveis para controlar a fração de não-conformes do lote ou do processo. A característica de qualidade é uma variável, então existem limites de especificação: LIE e LSE, os dois ou apenas um deles. Esses limites definem os valores aceitáveis do parâmetro.
 Planos que controlam a fração de defeituosos (ou não conformes) do lote ou do processo; 2.) Planos que controlam um parâmetro do lote ou do processo, em geral a média. Suponha um plano de amostragem de variáveis para controlar a fração de não-conformes do lote ou do processo. A característica de qualidade é uma variável, então existem limites de especificação: LIE e LSE, os dois ou apenas um deles. Esses limites definem os valores aceitáveis do parâmetro.")
205
A fração p de não-conformes do lote corresponde a
P(X < LIE) = p, no caso de especificação unilateral, e evidentemente P(X < LIE) + P(X > LSE) = p no caso de especificação bilateral. É claro que p depende da média e do desvio padrão do processo. Suponha, agora, que o desvio padrão seja conhecido. Então, pode-se tomar uma amostra do lote para determinar se o valor da média é, ou não, tal que a fração de defeituosos p seja aceitável. O que se faz é o seguinte:
 = p, no caso de especificação unilateral, e evidentemente. P(X < LIE) + P(X > LSE) = p. no caso de especificação bilateral. É claro que p depende da média e do desvio padrão do processo. Suponha, agora, que o desvio padrão seja conhecido. Então, pode-se tomar uma amostra do lote para determinar se o valor da média é, ou não, tal que a fração de defeituosos p seja aceitável. O que se faz é o seguinte:")
206
1. Plano com a distância crítica k. Toma-se a a. a
1. Plano com a distância crítica k. Toma-se a a.a. de tamanho n do lote, [x1, x2, .... ,xn] e calcula-se a estatística: ZLIE = Observe que quanto maior o valor de ZLIE mais afastada está a média amostral do limite de especificação inferior LIE e, conseqüentemente, menor será a fração p de defeituosos do lote. Pode ser fixado um valor crítico, ou melhor, uma distância crítica k, tal que ZLIE > k (no caso unilateral). Dessa forma, se ZLIE > k o lote é aceito. E, em caso contrário o lote será rejeitado.
. Dessa forma, se ZLIE > k o lote é aceito. E, em caso contrário o lote será rejeitado.")
207
2. Plano com a área crítica M
2. Plano com a área crítica M. Este procedimento propõe selecionar uma a.a. de n itens do lote e, então, calcula-se a estatística: ZLIE = A seguir usa-se ZLIE para se estimar a fração de defeituosos, p, do lote ou do processo como a área sob a curva da normal padrão abaixo de ZLIE. Uma melhor estimativa ocorre quando se usa a estatística QLIE = ZLIE ao invés de ZLIE, como o escore padronizado.

208
Então, seja o valor estimado de p que se obtém
Então, seja o valor estimado de p que se obtém. Se exceder um valor máximo especificado M (área crítica) rejeita-se o lote, em caso contrário o aceite.
 rejeita-se o lote, em caso contrário o aceite.")
209
Elaboração de um Plano de Amostragem para Variáveis com uma Curva Característica de Operação Especificada A elaboração do plano de amostragem que tenha uma curva CO específica e o escore de interesse k (distância crítica) é feita tomando-se dois pontos da curva (p1, 1 - ) e (p2, ). É claro que p1 e p2 podem ser níveis da fração de não-conformes do lote ou do processo correspondentes a níveis ACEITÁVEL e REJEITÁVEL de qualidade, respectivamente. O nomograma, em anexo, permite que o engenheiro (ou outro profissional da qualidade) encontre o tamanho da amostra n exigido e o valor crítico k que satisfaçam as condições dadas p1, 1 - , p2 e para os casos onde é conhecido e desconhecido.
 é feita tomando-se dois pontos da curva (p1, 1 - ) e (p2, ). É claro que p1 e p2 podem ser níveis da fração de não-conformes do lote ou do processo correspondentes a níveis ACEITÁVEL e REJEITÁVEL de qualidade, respectivamente. O nomograma, em anexo, permite que o engenheiro (ou outro profissional da qualidade) encontre o tamanho da amostra n exigido e o valor crítico k que satisfaçam as condições dadas p1, 1 - , p2 e para os casos onde é conhecido e desconhecido.")
210
EXEMPLO 1 Seja o problema em que se pretende obter um plano com a distância crítica k. Uma fábrica de refrigerantes compra garrafas descartáveis de um fornecedor. A fábrica estabeleceu um limite de especificação inferior (LIE) de LIE = 225 psi. Se até 1% das garrafas do lote de fato se rompem abaixo desse limite a fábrica quer aceitar o lote com uma probabilidade de 1 - = 0,95. Assim, tem-se p1 = 0,01 e 1 - = 0,95. Mas, se 6% ou mais das garrafas do lote se rompem abaixo de LIE = 225, a fábrica deseja rejeitar o lote com probabilidade 0,90. Dessa vez tem-se p2 = 0,06 e = 0,10.
 de LIE = 225 psi. Se até 1% das garrafas do lote de fato se rompem abaixo desse limite a fábrica quer aceitar o lote com uma probabilidade de 1 - = 0,95. Assim, tem-se p1 = 0,01 e 1 - = 0,95. Mas, se 6% ou mais das garrafas do lote se rompem abaixo de LIE = 225, a fábrica deseja rejeitar o lote com probabilidade 0,90. Dessa vez tem-se p2 = 0,06 e = 0,10.")
211
Solução: Trace no nomograma, as linhas: uma de p1 a 1 - e outra de p2 a , ou melhor, da fração de defeituosos p1 = 0,01 a probabilidade de aceitação 1 - = 0,95 (em cada escala respectiva), depois a outra linha da fração de defeituosos p2 = 0,06 a = 0,10. A intersecção das linhas fornece k = 1,9. Se é desconhecido o tamanho da amostra é obtido seguindo-se a curva até a escala superior que fornecerá n = 40. Então, o procedimento é tomar uma amostra de tamanho n = 40 garrafas do lote, medir a força de ruptura de cada uma, calcular a média e o desvio padrão s e, em seguida, calcular: ZLIE = e aceitar o lote se ZLIE > k = 1,9.
, depois a outra linha da fração de defeituosos p2 = 0,06 a = 0,10. A intersecção das linhas fornece k = 1,9. Se é desconhecido o tamanho da amostra é obtido seguindo-se a curva até a escala superior que fornecerá n = 40. Então, o procedimento é tomar uma amostra de tamanho n = 40 garrafas do lote, medir a força de ruptura de cada uma, calcular a média e o desvio padrão s e, em seguida, calcular: ZLIE = e aceitar o lote se ZLIE > k = 1,9.")
212
Mas, se é conhecido deve-se descer verticalmente até a escala inferior conhecido resultando em n = 15. Portanto, se o desvio padrão é conhecido obtém-se uma amostra com tamanho sensivelmente reduzido.

214
EXEMPLO 2 Seja o problema do exemplo 1 e o plano com o procedimento da área crítica M. Pretende-se determinar a fração de defeituosos crítica (permissível) M. Solução: Neste caso segue-se o procedimento anterior e acrescenta-se um passo adicional, ou seja, converte-se os valores de ZLIE ou ZLSE em uma fração de defeituosos estimada. É sabido que n = 40 ( desconhecido) e k = 1,9. Então, determina-se a abscissa : = = 0,35
 M. Solução: Neste caso segue-se o procedimento anterior e acrescenta-se um passo adicional, ou seja, converte-se os valores de ZLIE ou ZLSE em uma fração de defeituosos estimada. É sabido que n = 40 ( desconhecido) e k = 1,9. Então, determina-se a abscissa : = = 0,35.")
215
Então, com o valor 0,35 encontra-se diretamente no nomograma adiante o valor de M = 0,030. Portanto, tomando-se a amostra definida de n = 40 e calculando-se a média amostral = 255 e o desvio padrão s = 15, tem-se: ZLIE = = = 2

217
Então, entrando no 30. nomograma com ZLIE = 2 encontra-se = 0,02
Então, entrando no 30. nomograma com ZLIE = 2 encontra-se = 0,02. E, como = 0,02 < M = 0,03 aceitá-se o lote.

218
Então, com o valor 0,35 encontra-se diretamente no nomograma (em anexo) o valor de M = 0,030. Portanto, tomando-se a amostra definida de n = 40 e calculando-se a média amostral = 255 e o desvio padrão s = 15, tem-se: ZLIE = = = 2

219
7. REGRESSÃO Suponha que se deseja estabelecer a relação entre duas variáveis por meio de um modelo. EXEMPLO: Foram tomadas n = 9 amostras de um solo (canteiros) que foram tratadas com diferentes quantidades X de fósforo. Seja Y a quantidade de fósforo presente em sementes de plantas, de 38 dias, crescidas nos diferentes canteiros. Os dados estão adiante. De início se faz um Diagrama de Dispersão para se visualizar o tipo de função. X Y
 que foram tratadas com diferentes quantidades X de fósforo. Seja Y a quantidade de fósforo presente em sementes de plantas, de 38 dias, crescidas nos diferentes canteiros. Os dados estão adiante. De início se faz um Diagrama de Dispersão para se visualizar o tipo de função. X Y")
220
Observa-se na forma do gráfico que a função é uma reta.

221
Ajusta-se então o modelo linear:
Yi = 0 + 1Xi + i Onde 0 e 1 são os parâmetros do modelo; Y é a variável resposta; Xi é a variável explicativa; i é o erro, supõe-se que i ~ N(o, 2) O modelo é ajustado por Mínimos Quadrados Ordinários
 O modelo é ajustado por Mínimos Quadrados Ordinários.")
222
O ajuste pelo MINITAB MTB> STAT> REGRESSION> REGRESSION Regression Analysis: Y versus X The regression equation is Y = X Predictor Coef SE Coef T P Constant X S = R-Sq = 64.8%

223
Analysis of Variance Source DF SS MS F P Regression Residual Error Total Conclui-se que: O modelo é estatísticamente significativo p = 0,009 <0,05 A qualidade do modelo é razoável R2 = 0,648.

Apresentações semelhantes



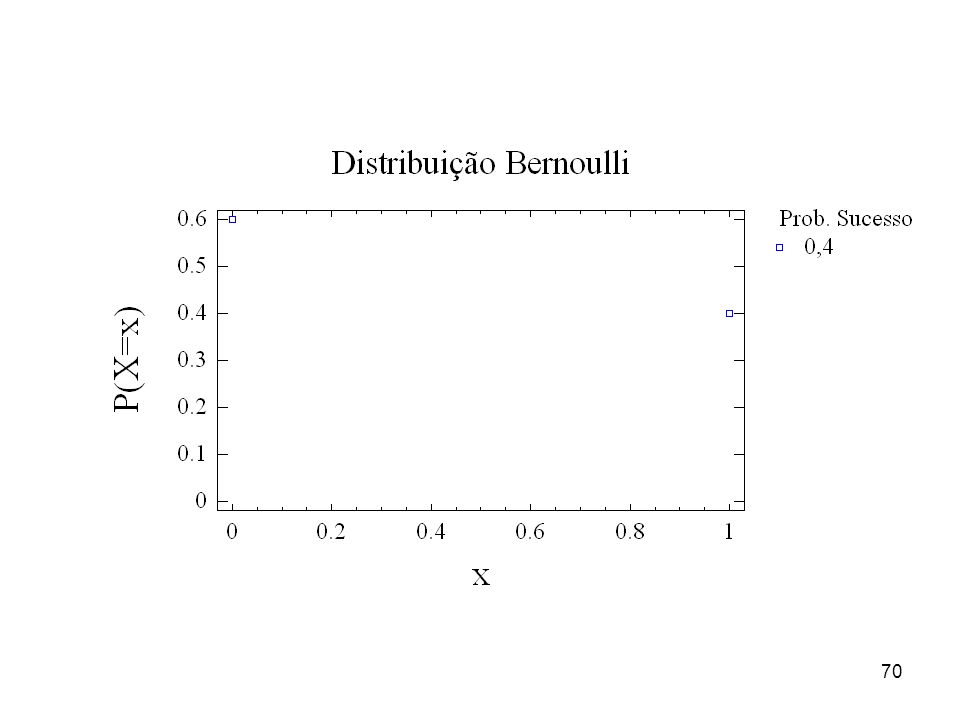
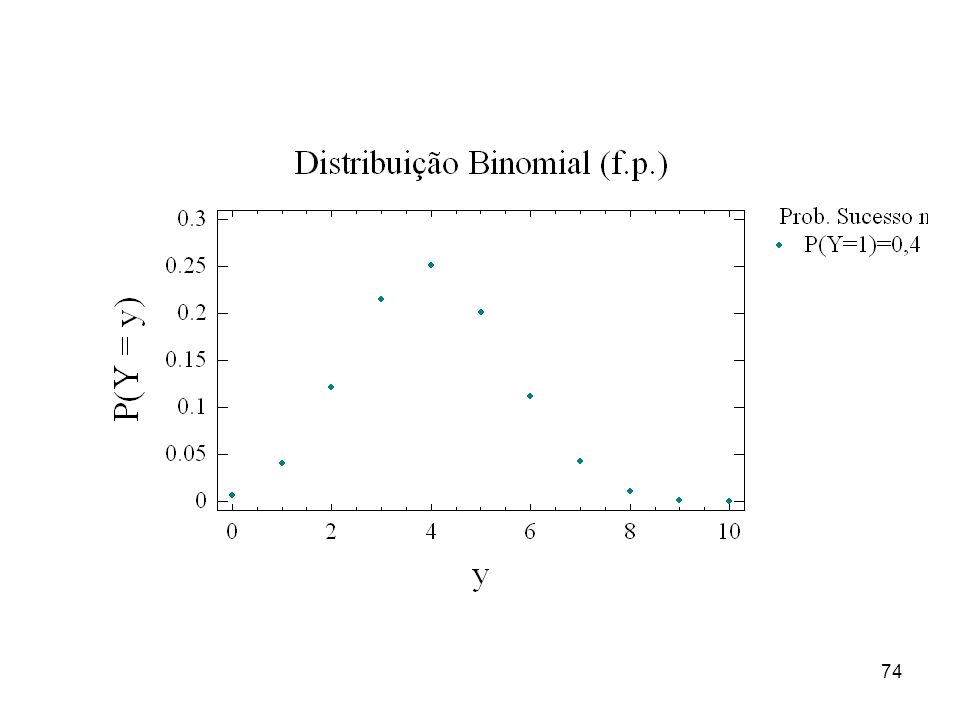
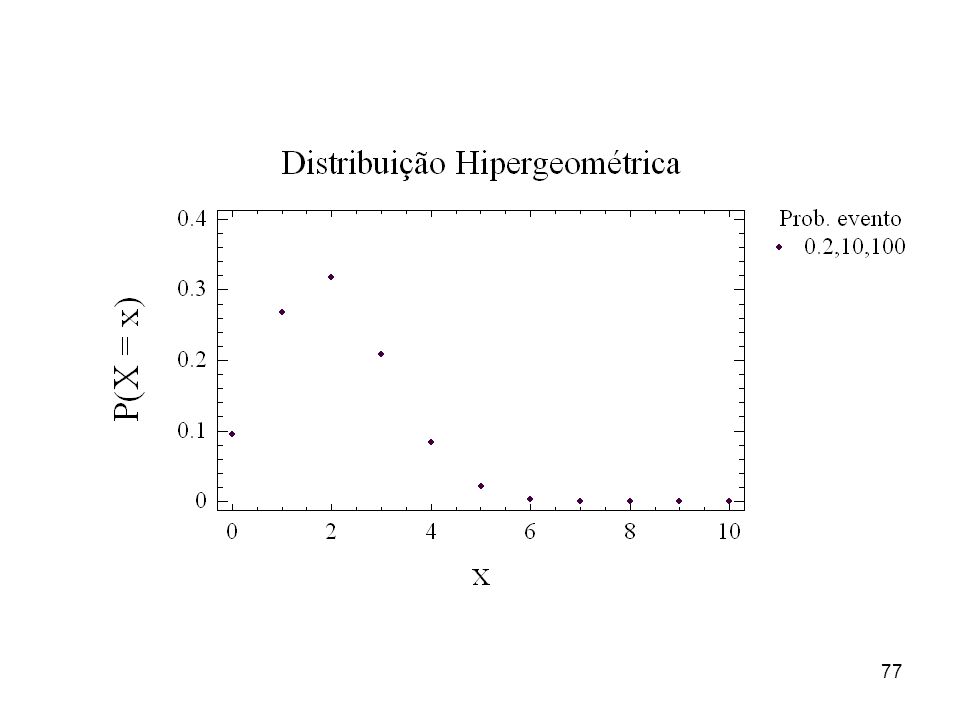
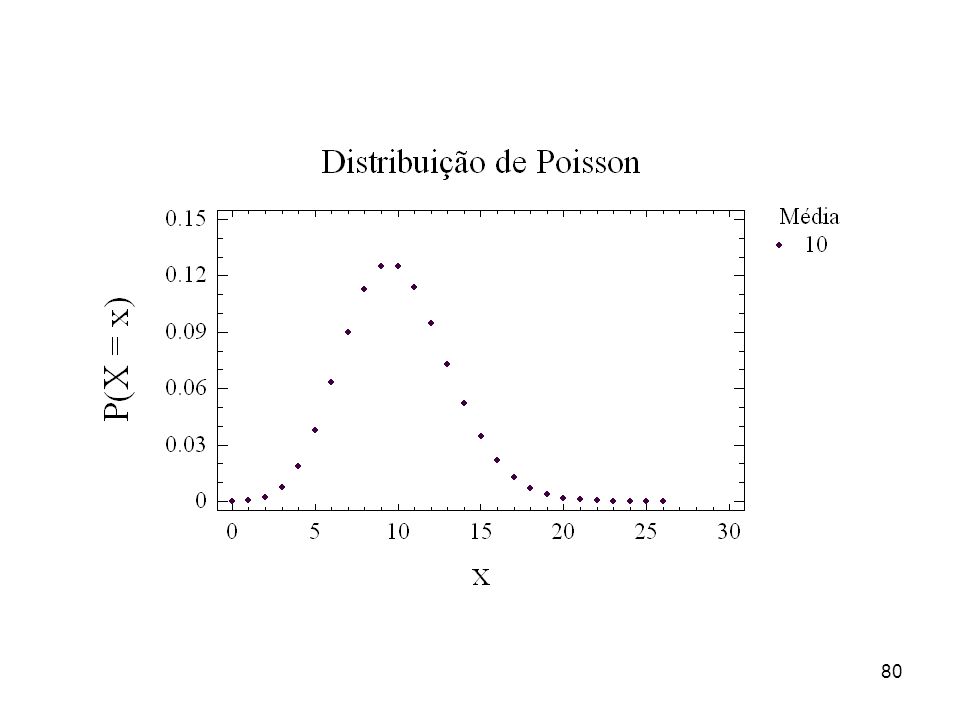
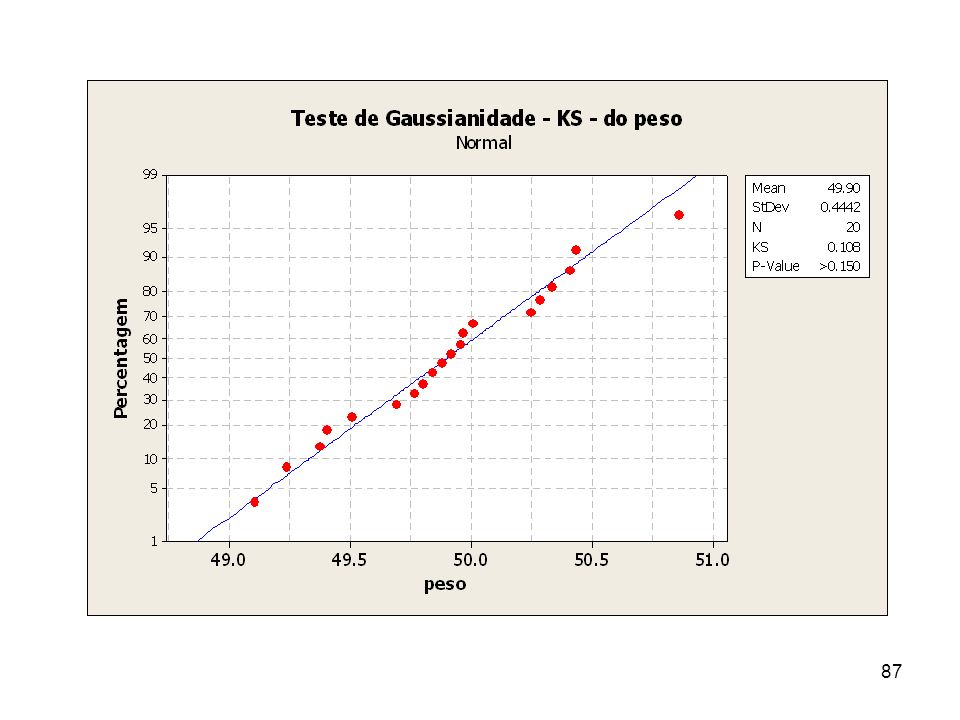
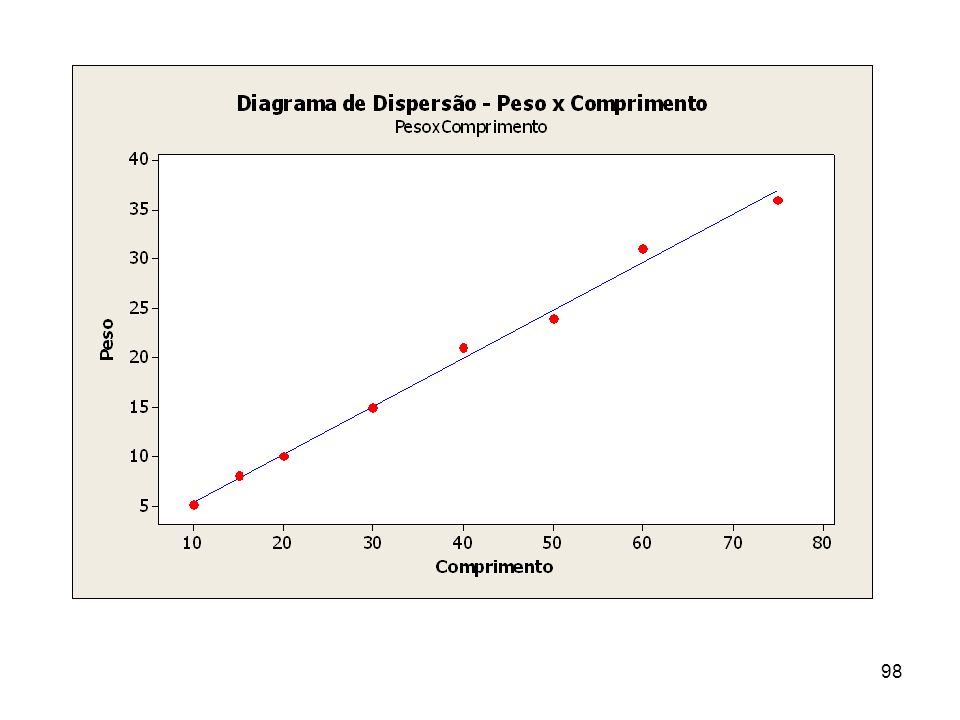
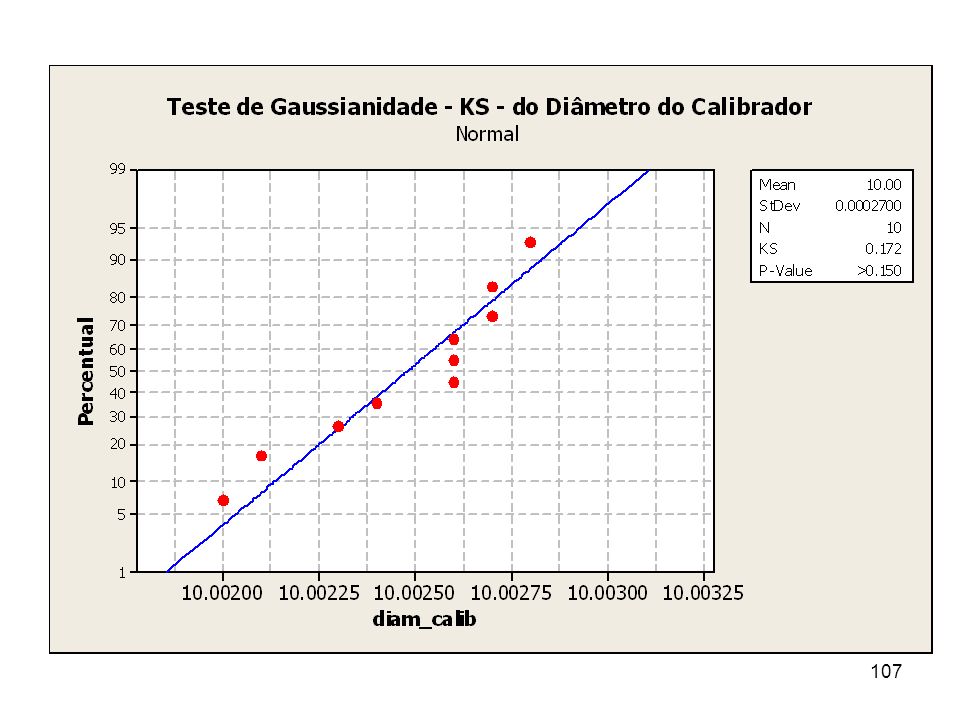
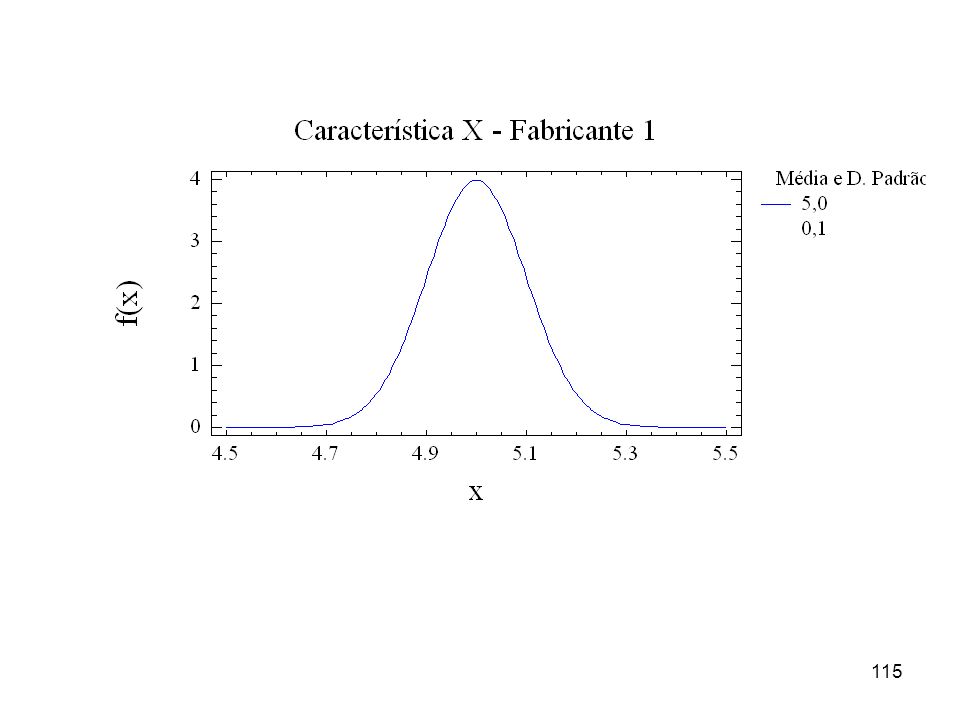
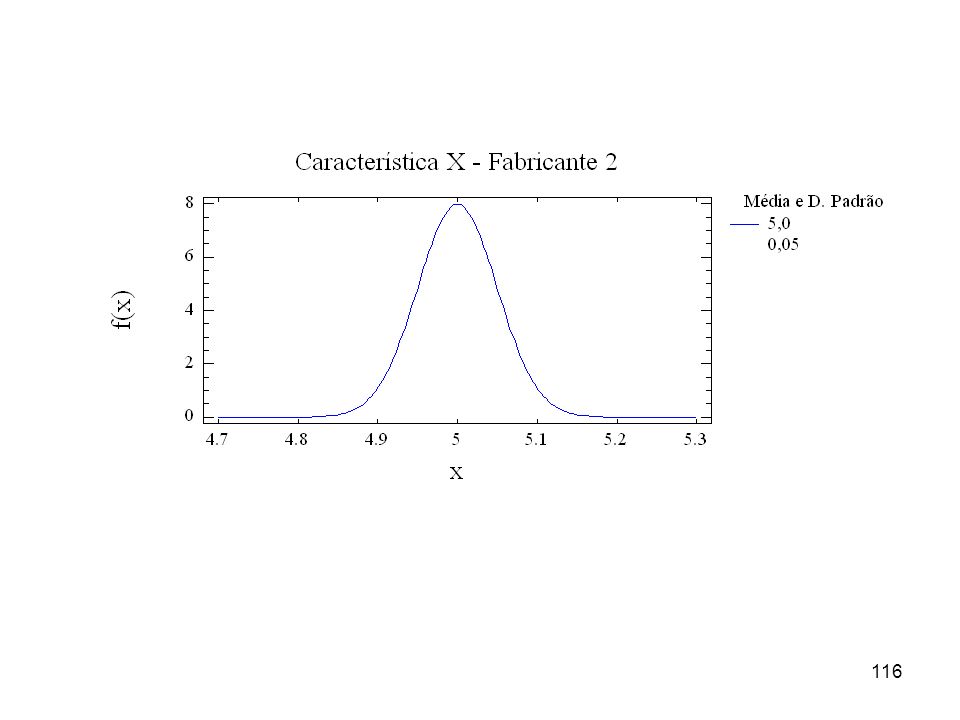
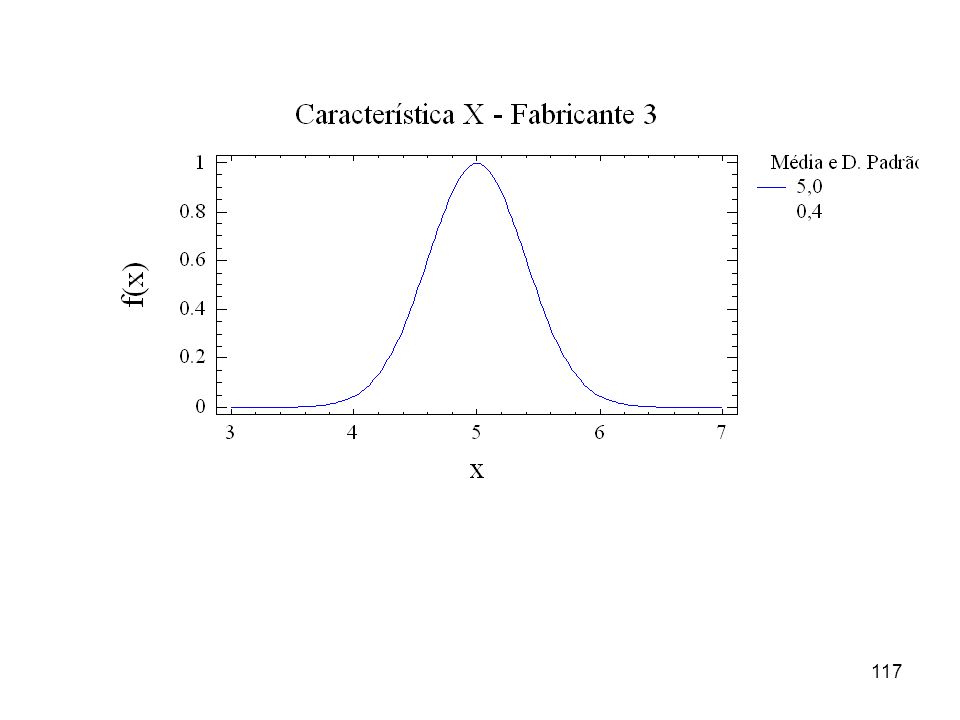
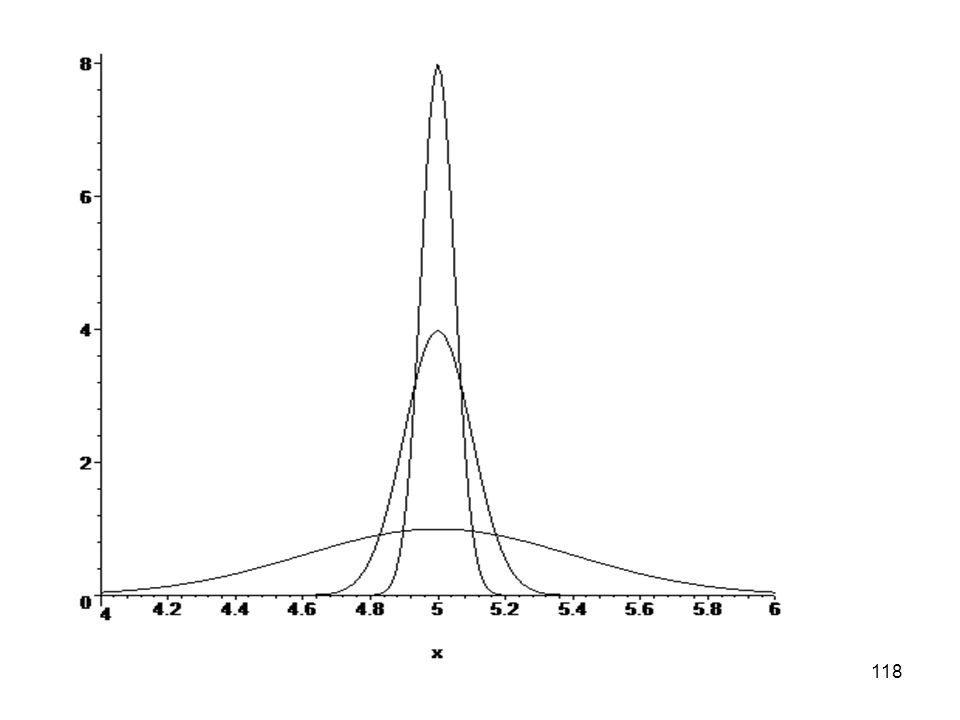
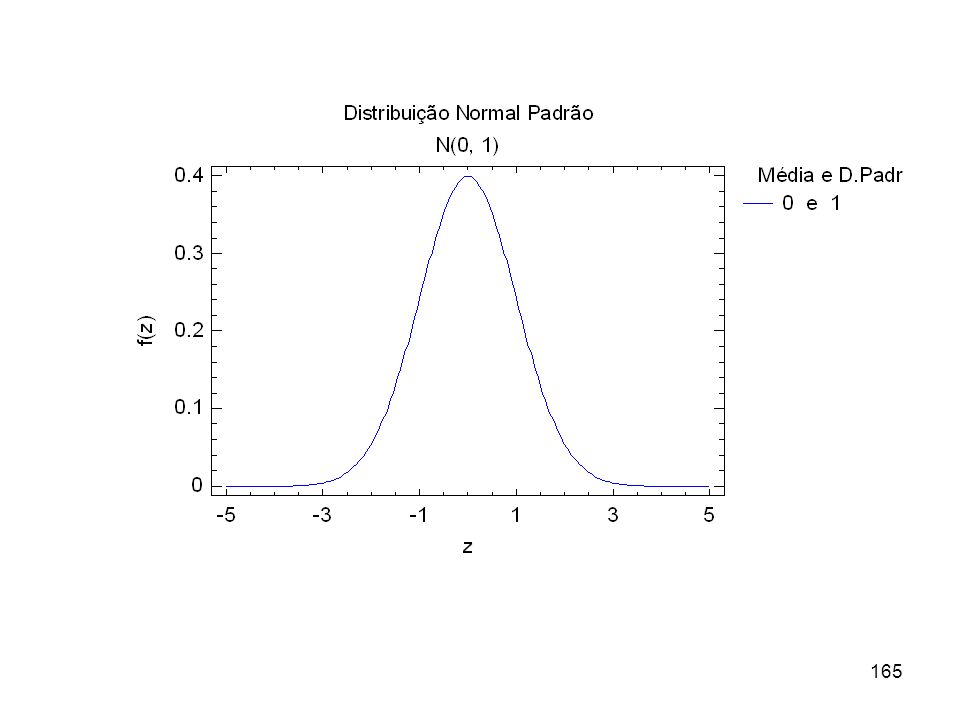
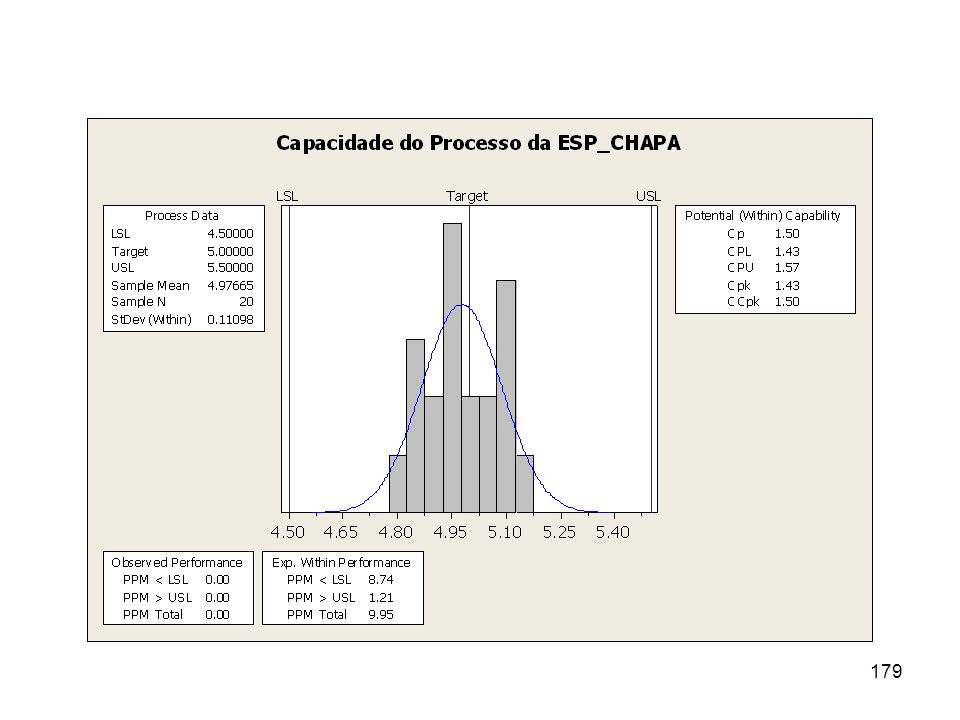
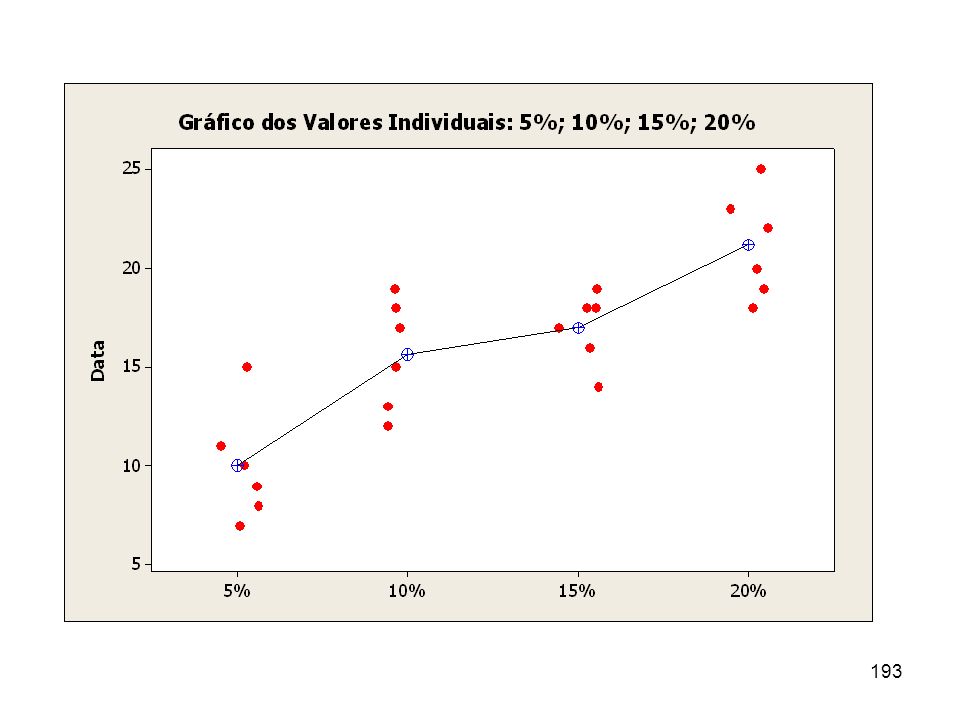
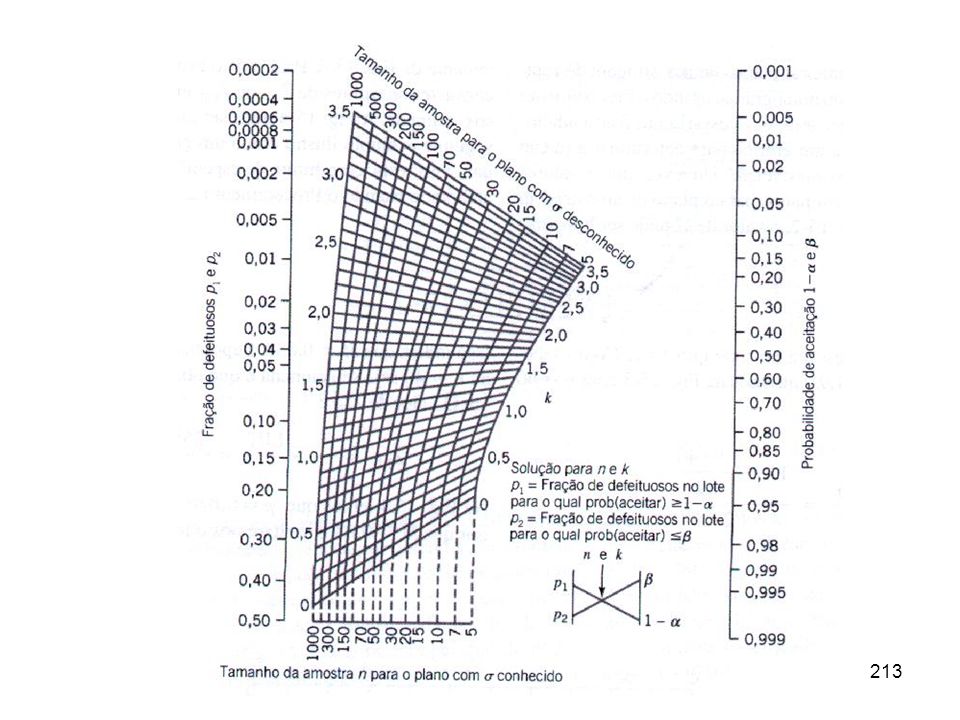
 – Lápides 1, 2, 3» «nomes gravados, 21 de Agosto de 2008» «Ultramar.TerraWeb»>")


















