Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Capítulo 8 Métodos de Aprendizagem Não Supervisionados Introdução
A análise de dados multivariados tem um papel fundamental em Data Mining e KDD (Knowledge Discovery in Databases). Dados multivariados consistem de diversos atributos ou variáveis tomados sobre cada registro, caso ou observação.
. Dados multivariados consistem de diversos atributos ou variáveis tomados sobre cada registro, caso ou observação.")
2
variáveis X1 X2 ... Xp 1 x11 x x1p 2 x21 x x2p n xn1 xn2 ... xnp X(n x p) matriz de dados As linhas de X(n x p) são supostamente independentes, mas as colunas são, em geral, correlacionadas.
 matriz de dados. As linhas de X(n x p) são supostamente independentes, mas as colunas são, em geral, correlacionadas.")
3
Principais objetivos:
Reduzir a dimensionalidade: espaço p-dimensional bidimensional ; Obter escores (índice composto) para todas as observações; Formar agrupamentos (clusters) de observações similares com base em diversas variáveis. Métodos de aprendizagem supervisionados e não supervisionados: Método de aprendizagem supervisionado: a relação entre as variáveis de entrada e saída (target, objetivo, variável resposta) são estabelecidas pelo pesquisador. Método de aprendizagem não supervisionado: não é definida a variável de saída (variável resposta)
 para todas as observações; Formar agrupamentos (clusters) de observações similares com base em diversas variáveis. Métodos de aprendizagem supervisionados e não supervisionados: Método de aprendizagem supervisionado: a relação entre as variáveis de entrada e saída (target, objetivo, variável resposta) são estabelecidas pelo pesquisador. Método de aprendizagem não supervisionado: não é definida a variável de saída (variável resposta)")
4
Métodos de aprendizagem não supervisionados:
Modelos de variáveis latentes (Técnicas estatísticas de Componentes Principais (Principal Components) e Análise de fatores (Factor Analysis)) e Modelos de equações estruturais (Structural equations modeling) Análise de agrupamentos (Análise de Conglomerados, em inglês, Cluster Analysis). Componentes Principais: reduz a dimensionalidade dos dados multivariados, transformando variáveis correlacionadas em variáveis não correlacionadas transformadas linearmente. Análise de Fatores: uns poucos fatores não correlacionados são extraídos, que explicam a máxima quantidade de variância comum e são responsáveis pela correlação observada entre os dados multivariados. As relações entre as variáveis e os fatores são, então, estudadas (investigadas). Análise de conglomerados: é usado para combinar observações (casos) em grupos ou clusters de tal forma que cada grupo seja homogêneo para um conjunto de variáveis. São grupos com características similares.
 e Análise de fatores (Factor Analysis)) e Modelos de equações estruturais (Structural equations modeling) Análise de agrupamentos (Análise de Conglomerados, em inglês, Cluster Analysis). Componentes Principais: reduz a dimensionalidade dos dados multivariados, transformando variáveis correlacionadas em variáveis não correlacionadas transformadas linearmente. Análise de Fatores: uns poucos fatores não correlacionados são extraídos, que explicam a máxima quantidade de variância comum e são responsáveis pela correlação observada entre os dados multivariados. As relações entre as variáveis e os fatores são, então, estudadas (investigadas). Análise de conglomerados: é usado para combinar observações (casos) em grupos ou clusters de tal forma que cada grupo seja homogêneo para um conjunto de variáveis. São grupos com características similares.")
5
Aplicações dos métodos não supervisionados
Lembrando que mais de um método pode ser usado para resolver o mesmo objetivo. Análise de componentes principais: um analista de negócios está interessado em rankear (posto que ele ocupa, primeiro, segundo,...) 2000 fundos baseado na performance mensal dos últimos dois anos de 20 indicadores financeiros e índices. Seria muito difícil criar os escores para cada fundo baseado nos 20 indicadores e interpretá-los. Assim, o analista realizou uma análise de Componentes Principais sobre uma matriz de dados padronizados de dimensão 2000 x 20 e extraiu os dois primeiros componentes. Os dois primeiros componentes contabilizaram 74% da variabilidade contida nas 20 variáveis. Assim, o analista usou os dois componentes para calcular os escores e criar um rank para os fundos.
 2000 fundos baseado na performance mensal dos últimos dois anos de 20 indicadores financeiros e índices. Seria muito difícil criar os escores para cada fundo baseado nos 20 indicadores e interpretá-los. Assim, o analista realizou uma análise de Componentes Principais sobre uma matriz de dados padronizados de dimensão 2000 x 20 e extraiu os dois primeiros componentes. Os dois primeiros componentes contabilizaram 74% da variabilidade contida nas 20 variáveis. Assim, o analista usou os dois componentes para calcular os escores e criar um rank para os fundos.")
6
Análise exploratória de fatores: pode ser usado para estratégias de marketing. Pode-se criar postos (ranks) para os consumidores através dos escores fatoriais, e diferentes promoções podem ser adotadas para cada consumidor baseado nos valores dos escores fatoriais. Análise de conglomerados: um banco coleta e mantém uma grande base de dados sobre os padrões dos correntistas para vários serviços bancários, como, conta corrente, poupança, certificados de depósitos, empréstimos, e cartão de crédito. Baseado em atributos bancários, o banco desejaria segmentar os correntistas em muito ativo, moderados e passivos, baseado nos dados dos últimos três anos dos correntistas. O analista realiza uma análise de cluster e obtém os conglomerados (grupos). A divisão de marketing usou a segmentação para montar estratégias diferenciadas de marketing para os vários grupos.
. A divisão de marketing usou a segmentação para montar estratégias diferenciadas de marketing para os vários grupos.")
7
Análise de Componentes Principais
Definição de componentes principais O objetivo da análise é tomar p variáveis X1,X2,....,Xp e encontrar combinações dessas para produzir variáveis latentes Z1,Z2,...,ZP, que são não correlacionadas. A falta de correlação é uma propriedade muito útil porque isto significa que estas variáveis latentes estão medindo diferentes “dimensões” dos dados. Os componentes principais são ordenados de acordo com a quantidade de variância explicada: onde var(Zi) representa a variância de Zi no conjunto de dados. Sempre que realizamos uma análise de componentes principais, esperamos conseguir explicar quase toda a variabilidade dos dados com uns poucos componentes principais.
 representa a variância de Zi no conjunto de dados. Sempre que realizamos uma análise de componentes principais, esperamos conseguir explicar quase toda a variabilidade dos dados com uns poucos componentes principais.")
8
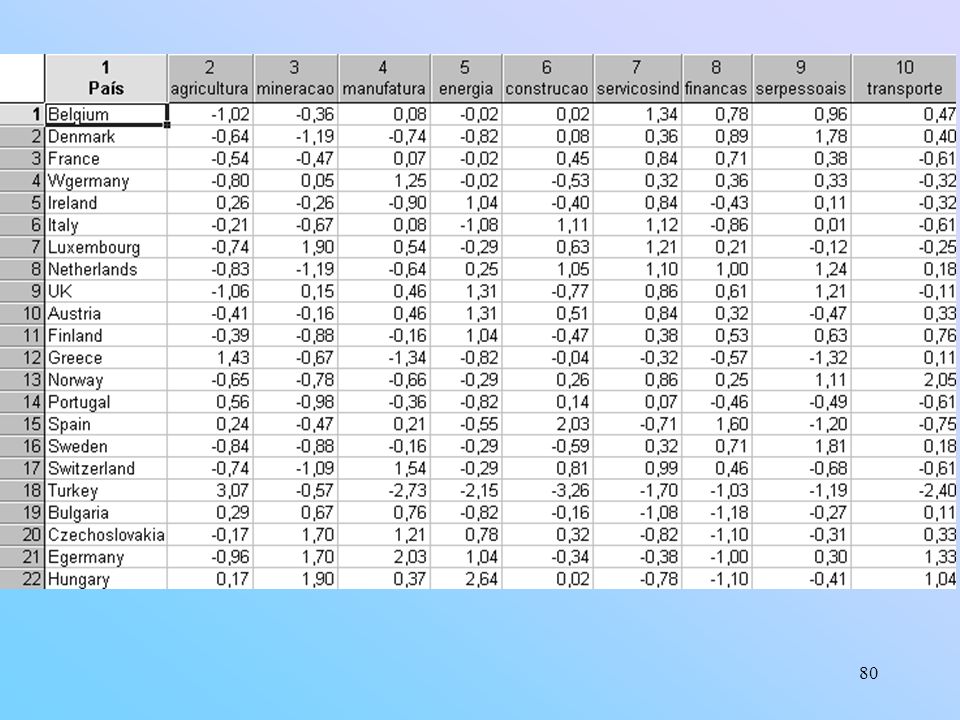
Se as variáveis originais não são correlacionadas, então a análise de componentes principais não tem efeito algum. Os melhores resultados são obtidos quando as variáveis originais são altamente correlacionadas, positiva ou negativamente. Breve descrição da realização da análise de componentes principais Vamos considerar os dados de porcentagens de pessoas empregadas em 9 grupos de atividades diferentes em 26 paises europeus, ano de Na tabela a seguir Apresenta-se parte dos dados:

9
De acordo com a tabela abaixo, temos variáveis muito correlacionadas, por exemplo, agricultura e serviços pessoais, outras estão medianamente correlacionadas, por exemplo, mineração e finanças, e outras, ainda, pouco correlacionadas, por exemplo, agricultura e mineração. Portanto, este conjunto de dados é razoavelmente bom para análise de componentes principais. Isto indica que vários componentes serão necessários para contabilizar a variabilidade dos dados .

10
Os primeiros 4 componentes principais tem variâncias iguais a: 3,49, 2,130, 1,10 e 0,99, respectivamente. Estes 4 componentes são os mais importantes para representar a variabilidade das variáveis dos 26 países. Este 4 componentes principais explicam 85,6752% da variabilidade dos dados. Porém, vamos considerar que um menor número de componentes é suficiente para apresentar os aspectos principais das diferenças entre os países. Assim, vamos considerar apenas os dois primeiros componentes (inclusive, são os únicos que apresentam autovalores bem superior a 1).
..")
11
Os dois primeiros componentes representam aproximadamente 62% da variância, e são dados por:
Olhando-se para o primeiro componente, podemos verificar que ele é um contraste entre o número de empregados na agricultura e o número de empregados em manufatura, energia, construção, serviços na indústria, serviços pessoais e transporte. As variáveis com coeficientes próximos de zero são desprezíveis.

12
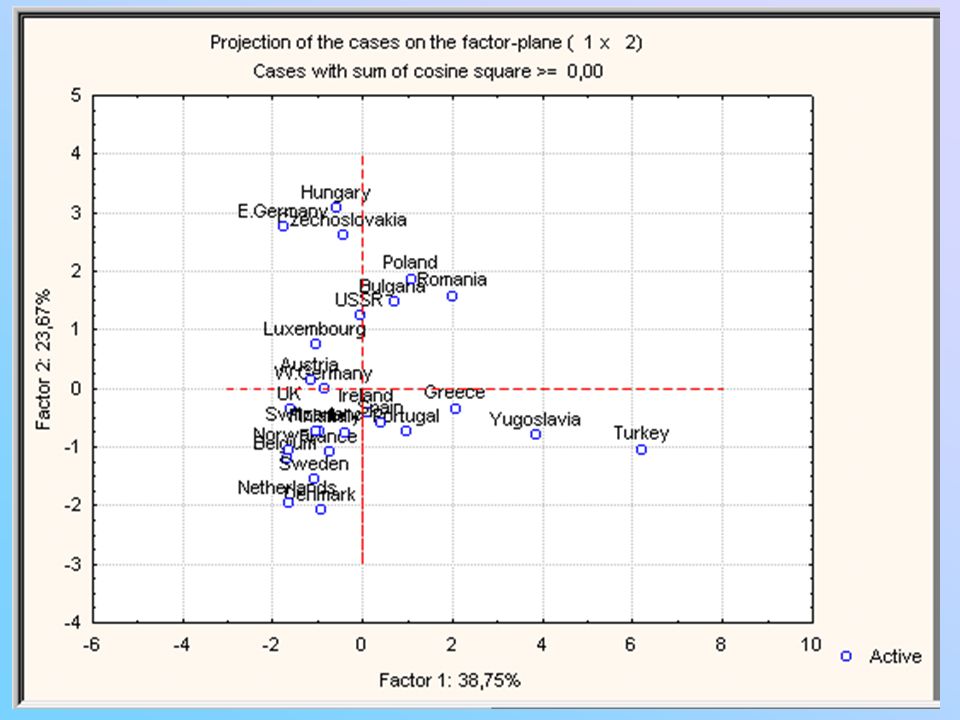
O segundo componente é um contraste entre o número de empregados em mineração e manufatura com o número em serviços da indústria e finanças. A figura a seguir representa os 26 países versus os valores Z1 e Z2. A maioria dos países democráticos do oeste estão associados com baixos valores de Z1 e Z2. Irlanda, Portugal, Espanha e Grécia, apresentam altos valores de Z1. Turquia e Iugoslávia apresentam valores bem altos de Z1. Países comunistas, com exceção da Iugoslávia, estão agrupados com valores altos de Z2.

14
Escores fatoriais (Factor scores)
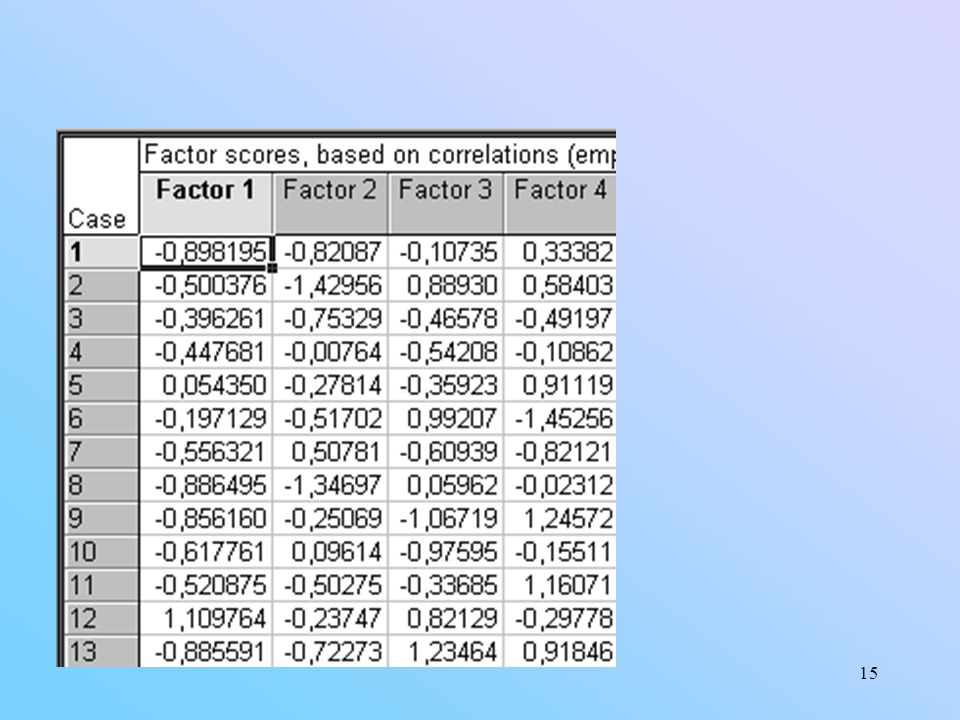
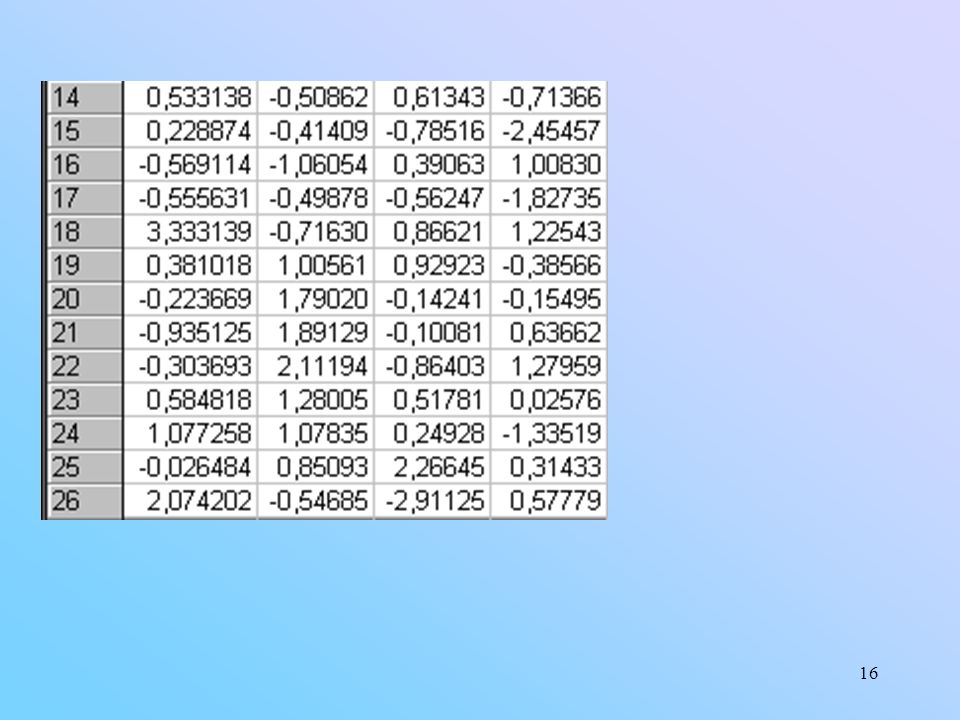
O escore fatorial do i-ésimo caso para o -ésimo fator é dado por: J=1,2,...,p é o número de variáveis. Exemplo: 26 países europeus. O escore do primeiro país, Bélgica, para o primeiro componente principal, é dado por: u={ }; X={ , , , , , , , , }; (Valores padronizados). = ;
. = ;")
17
Procedimento de cálculo dos componentes principais
A análise de componentes principais inicia com dados de p variáveis quantitativas, isto é, seus valores são dados numa escala numérica, para n observações. O primeiro componente principal é então a combinação linear das variáveis X1, X2,...,Xp, Sujeito a restrição: A var(Z1) é a maior possível sujeita a restrição sobre as constantes a1j. A restrição é incluída para a variância não aumentar pelo simples fato de adicionar um valor a1j.
 é a maior possível sujeita a restrição sobre as constantes a1j. A restrição é incluída para a variância não aumentar pelo simples fato de adicionar um valor a1j.")
18
Exemplo: vamos obter os componentes principais relativos às variáveis X1 e X2 cuja matriz de variâncias-covariâncias é dada por: Resolução: A equação característica é dada por: Isto é:

19
As raízes próprias ou auto valores, obtidos desta equação são:
A soma dessas duas raízes dá 14,44. Sobre esse total elas correspondem, em porcentagem, a: 88,9% para 1 e 11,1% 2. Então o componente principal, relativo a 1 vai explicar 88,9% da variação, em comparação com apenas 11,1% para o componente 2. Vamos calcular o componente principal, correspondente à raiz maior 1=12,844. Ele será dado pela equação:

20
Obtemos: Este sistema de equações é indeterminado, uma vez que temos:

21
Podemos, pois, abandonar uma das equações (por exemplo, a segunda) e dar um valor arbitrário, não nulo, a uma das incógnitas (por exemplo x12=1). Fica: A solução inicial é:

22
A soma dos quadrados dos coeficientes obtidos é:
Para obter uma solução com soma de quadrados igual a 1,00 (vetor normalizado), multiplicamos a solução obtida por: Obtemos: Logo, o primeiro componente principal é: Responsável por 88,9% da variação.
, multiplicamos a solução obtida por: Obtemos: Logo, o primeiro componente principal é: Responsável por 88,9% da variação.")
23
O segundo componente principal é dado pelo sistema de equações relativo à outra raíz, 2=1,596.
A solução inicial obtida é:

24
Outra solução para os componentes principais
A solução final é: O segundo componente principal, responsável por 11,1% da variação e ortogonal ao primeiro é dado por: Outra solução para os componentes principais As vezes, as unidades das variáveis envolvidas na análise são completamente diferentes. Nestes casos é indicado usar as variáveis reduzidas ou padronizadas, isto é, cada uma dividida pelo desvio padrão:

25
Mas isto é equivalente a trabalhar com a matriz de correlações(estimativa):
Onde: Exemplo: a matriz de correlação do exemplo é dada por:

26
Onde o valor 0,7645 é obtido através de:
Com, Portanto,

27
No exemplo, as variáveis padronizadas são dadas por:
A equação característica será: As raízes próprias (os autovalores) são:
 são:")
28
A porcentagem de explicação para cada um deles é:
Primeiro componente principal (1=1,7382) Desprezando a última equação e fazendo x12=1 x11=1
 Desprezando a última equação e fazendo x12=1 x11=1.")
29
O componente principal fica:
A soma dos quadrados dos coeficientes é: 12+12=2. Para obter uma solução normalizada (com soma da quadrados igual a 1), multiplicamos a solução obtida por 1/2=0,7071. Obtemos: Logo, o componente principal é dado por: Substituindo-se os valores de x1 e x2, temos:
, multiplicamos a solução obtida por 1/2=0,7071. Obtemos: Logo, o componente principal é dado por: Substituindo-se os valores de x1 e x2, temos:")
30
Passos na análise de componentes principais:
Inicia-se codificando as variáveis X1,X2,...,Xp para ter média zero e variância 1. Isto é o usual, mas é omitido em alguns casos. Calcular a matriz de covariâncias C. Se a padronização do passo 1 for realizada, então, esta matriz será a matriz de correlação. Encontrar os auto-valores 1, 2,..., p e os correspondentes auto-vetores u1, u2,...,up. Os coeficientes do i-ésimo componente são então dados por ui enquanto i é a sua variância. Descartar os componentes que apresentam baixa explicação da variação dos dados. Por exemplo, considere que tenhamos 20 variáveis para a análise e encontramos que 3 componentes explicam 90% da variabilidade total. Assim os outros 17 componentes devem ser ignorados.

31
Análise de Conglomerados (‘Cluster Analysis’)
Introdução A análise de conglomerados é uma técnica multivariada para reunir casos, registros, em grupos não definidos pelos dados (não são definidos à priori), de tal forma que o grau de associação entre os casos dentro de um mesmo grupo é forte e é fraca entre casos de diferentes grupos. Na exploração e descrição de grandes bases de dados, é útil resumir a informação designando cada observação a um grupo com características similares. Conglomeração pode ser usada para reduzir o tamanho dos dados e induzir a grupos. Como resultado, a análise de conglomerados pode revelar similaridades em dados multivariados, difíceis de serem encontrados de outra forma. Por exemplo, no estudo de aprovação de um novo produto, temos um número enorme de cidades e, portanto, impossível estudar-se todas elas. Se as cidades puderem ser reunidas em uns poucos grupos de cidades similares, então uma cidade de cada grupo pode participar do estudo.
, de tal forma que o grau de associação entre os casos dentro de um mesmo grupo é forte e é fraca entre casos de diferentes grupos. Na exploração e descrição de grandes bases de dados, é útil resumir a informação designando cada observação a um grupo com características similares. Conglomeração pode ser usada para reduzir o tamanho dos dados e induzir a grupos. Como resultado, a análise de conglomerados pode revelar similaridades em dados multivariados, difíceis de serem encontrados de outra forma. Por exemplo, no estudo de aprovação de um novo produto, temos um número enorme de cidades e, portanto, impossível estudar-se todas elas. Se as cidades puderem ser reunidas em uns poucos grupos de cidades similares, então uma cidade de cada grupo pode participar do estudo.")
32
Tipos de análise de conglomerados
A Análise de conglomerados procura determinar um conjunto de grupos os quais minimizam a variância dentro deles e maximizam a variância entre eles. Portanto, os conglomerados são homogêneos. Se a análise de conglomerados gerar grupos não esperados, então, significa que ela própria está sugerindo novos relacionamentos que devem ser investigados. Tipos de análise de conglomerados Muitos algoritmos têm sidos propostos para análise de conglomerados. Será dada atenção a duas abordagens: Técnicas hierárquicas: estas técnicas produzem os dendogramas, como mostrado na figura a seguir. Esses métodos iniciam com o cálculo de distâncias de cada observação com todas as outras observações. Grupos são formados por dois processos: Aglomerativos: todas as observações iniciam como sendo um grupo(unitário); grupos próximos são, então gradualmente juntados até, finalmente, todas as observações constituírem um único grupo. Divisivos: todas as observações iniciam num único grupo. Após são separados em dois grupos e assim por diante, até que cada observação seja o próprio grupo.
; grupos próximos são, então gradualmente juntados até, finalmente, todas as observações constituírem um único grupo. Divisivos: todas as observações iniciam num único grupo. Após são separados em dois grupos e assim por diante, até que cada observação seja o próprio grupo.")
33
Tipos de análise de conglomerados
10 9 Método do vizinho mais próximo(aglomerativo) 8 7 6 Distância 5 4 3 2 1 A B C D E 10 9 Método do vizinho mais distante (aglomerativo) 8 7 6 Distância 5 4 3 2 1 A B C D E
 Distância A. B. C. D. E Método do vizinho mais distante (aglomerativo) Distância A. B. C. D. E.")
34
Método das médias das distâncias (aglomerativo)
10 9 Método das médias das distâncias (aglomerativo) 8 7 6 Distância 5 4 3 2 1 A B C D E Figura. Exemplos de dendogramas de análise de conglomerados de 5 registros. A B C D E F A B E C D F A B E C D F A B D F Figura. Exemplo de algoritmo divisivo de 6 registros.
 Distância A. B. C. D. E. Figura. Exemplos de dendogramas de análise de conglomerados de 5 registros. A B C D E F. A B E. C D F. A B. E. C. D F. A. B. D. F. Figura. Exemplo de algoritmo divisivo de 6 registros.")
35
Técnicas de partição: estas técnicas permitem às observações moverem-se de um grupo para outro em diferentes estágios da análise. A análise inicia com a atribuição arbitrária de medidas de tendência central do grupo e as observações são alocadas na vizinhança do centro do grupo. Novos centros são então calculados. Uma observação é então transferida para um novo grupo se ele está mais próximo do centro deste grupo do que do centro do seu grupo atual. Grupos próximos são juntados; grupos cujas observações estão bastante afastadas são divididos. O processo continua até encontrar a estabilidade com um número de grupos pré-determinado. Usualmente utiliza-se uma faixa de valores para o número final de grupos. Outra sugestão é, inicialmente realizar o método hierárquico e usar o número de conglomerados encontrados nesta análise como sugestão para o método de partição.

36
Métodos hierárquicos aglomerativos
Em geral, os métodos de partição são mais eficientes em grandes bases de dados. Observação: 100 ou mais registros. Métodos hierárquicos aglomerativos Para ilustrar os procedimentos de diversos algoritmos vamos usar o seguinte exemplo. Exemplo: pretende-se investigar, de forma exploratória, o histórico de crescimento corpóreo das pessoas. O pesquisador gostaria de escolher representantes “típicos” da população para tentar traçar diferentes históricos. O objetivo operacional passou a ser o de agrupar os indivíduos da população alvo segundo as variáveis peso e altura. Os dados de seis pessoas foram:

37
Como temos duas variáveis com unidades diferentes, usar-se-á a padronização dos dados, isto é, cada valor será subtraído da média de todas as observações e dividida pelo desvio padrão de todas as observações. A nova tabela fica:

38
Os métodos hierárquicos aglomerativos iniciam com uma matriz de distâncias entre os casos (observações, registros). Todos os registros estão separados (cada registro é um grupo). Os grupos que estão mais ”próximos” são juntados (agregados). Vamos estudar três casos: Método do vizinho mais próximo Método do vizinho mais longe Método das médias das distâncias Método do vizinho mais próximo (Método da ligação simples- Single Linkage) Para o nosso exemplo suponha a seguinte matriz de distâncias: A B C D E B Sempre é uma matriz quadrada e simétrica C D * E F
 Para o nosso exemplo suponha a seguinte matriz de distâncias: A. B. C. D. E. B. Sempre é uma matriz quadrada e simétrica. C. D. * E. F.")
39
Passo 1: inicialmente, consideramos uma distância igual a zero e, portanto, cada caso forma um grupo, isto é, temos 6 grupos iniciais. Passo 2: olhando-se a matriz de distâncias, observa-se que as duas observações mais próximas são D e F, corresponde a uma distância de 0,37, assim, esta duas observações são agrupadas, formando o primeiro grupo. Necessita-se, agora, das distâncias deste grupo aos demais. A partir da matriz de distâncias iniciais têm-se: Com isso, temos a seguinte matriz de distâncias:

40
A B C E B C E DF Passo 3: Agrupar A e B ao nível de 0,67, e recalcular: A matriz resultante será:

41
C E DF E DF AB Passo 4: Agrupar AB com E ao nível de 0,67, e recalcular: Matriz resultante: C DF DF ABE

42
Passo 5: Agrupar C com ABE ao nível de 0,74, e recalcular:
Matriz resultante: DF ABCE Passo 6: O último passo cria um único agrupamento contendo os 6 objetos, que serão similares a um nível de 0,77.

43
Resumindo-se, temos: Dendograma: Distância D F A B E C 1,0 0,9 0,8 0,7
0,6 Distância 0,5 0,4 0,3 0,2 0,1 0,0 D F A B E C

44
Método do vizinho mais longe (Método da ligação completa – Complete Linkage)
Define-se a distância entre os grupos X e Y como: Convém ressaltar que a fusão de dois grupos ainda é feita com os grupos mais parecidos, menor distância. Passo 1: inicialmente, consideramos uma distância igual a zero e, portanto, cada caso forma um grupo, isto é, temos 6 grupos iniciais. Passo 2: olhando-se a matriz de distâncias, dada no slide número 37, observa-se que as duas observações mais próximas são D e F, corresponde a uma distância de 0,37, assim, estas duas observações são agrupadas, formando o primeiro grupo. Necessita-se, agora, das distâncias deste grupo aos demais. A partir da matriz de distâncias iniciais tem-se:

45
A B C E B C E DF Passo 3: Agrupar A e B ao nível de 0,67, e recalcular:

46
Temos: C E DF E DF AB

47
Passo 4: Agrupar AB com E ao nível de 0,79, e recalcular:
Matriz resultante: C DF DF ABE

48
Passo 5: Agrupar C com DF ao nível de 1,13, e recalcular:
Matriz resultante: CDF ABE Passo 6: O último passo cria um único agrupamento contendo os 6 objetos, que serão similares a um nível de 2,49.

49
Resumindo-se, temos: Dendograma: Distância D F C A B E 2,5 1,3 1,2 1,1
1,0 0,9 0,8 0,7 0,6 Distância 0,5 0,4 0,3 0,2 0,1 0,0 D F C A B E

50
Método das médias das distâncias
Dada a matriz de distâncias: A B C D E B C D E F Passo 1: inicialmente, consideramos uma distância igual a zero e, portanto, cada caso forma um grupo, isto é, temos 6 grupos iniciais. Passo 2: olhando-se a matriz de distâncias, observa-se que as duas observações mais próximas são D e F, corresponde a uma distância de 0,37, assim, esta duas observações são agrupadas, formando o primeiro grupo. Necessita-se, agora, das distâncias deste grupo aos demais. A partir da matriz de distâncias iniciais tem-se:

51
A B C E B C E DF Com a obtenção da matriz de distâncias conclui-se o passo 2, que reuniu os pontos D e F, num nível igual à 0,37.

52
Passo 3: Analisando a nova matriz de similaridade, nota-se que existem dois pares com a mesma proximidade: A com B e B com E. Recomenda-se selecionar aleatoriamente um dos pares e criar o novo grupo. Porém, os programas computacionais, escolhem o primeiro par que aparece para agrupar. Então, neste caso, agrupa-se A com B. Temos: C E DF E DF AB

53
Passo 4: Agrupar AB com E ao nível de 0,73, e recalcular:
Matriz resultante: C DF DF ABE

54
Passo 5: Agrupar C com DF ao nível de 0,95, obtendo-se a partição (ABE, CDF) e recalcular:
Matriz resultante: CDF ABE Passo 6: O processo encerra reunindo num único grupo os conjuntos ABE e CDF, que são iguais a um nível 1,64 de parecença. Vimos três métodos diferentes para agrupar elementos. O importante é conhecer suas propriedades, qualidades e deficiências, pois irá ajudar “a escolha daquele que melhor responde aos objetivos do trabalho”.

55
Resumindo-se, temos: Observando o gráfico em forma de árvore (dendograma), notamos que o maior salto é observado na última etapa, sugerindo a existência de dois grupos homogêneos (A,B,E) e (C,D,F). Dendograma: 1,6 1,5 1,4 1,3 1,2 1,1 1,0 0,9 0,8 0,7 0,6 Distância 0,5 0,4 0,3 0,2 0,1 0,0 D F C A B E
, notamos que o maior salto é observado na última etapa, sugerindo a existência de dois grupos homogêneos (A,B,E) e (C,D,F). Dendograma: 1,6. 1,5. 1,4. 1,3. 1,2. 1,1. 1,0. 0,9. 0,8. 0,7. 0,6. Distância. 0,5. 0,4. 0,3. 0,2. 0,1. 0,0. D. F. C. A. B. E.")
56
Métodos hierárquicos divisivos – Diana (Divisive Analysis)
Diana é uma técnica de análise de agrupamentos hierárquica, porém constrói sua hierarquia na ordem inversa dos algoritmos aglomerativos. Inicialmente, há um grande agrupamento contendo todos os n objetos. Em cada passo subseqüente, o agrupamento atual é dividido em dois até que se chegue a um número de agrupamentos iguais ao número n de objetos. Em cada agrupamento, são possíveis possibilidades de dividir os objetos em dois agrupamentos. Para evitar o uso de todas as possibilidades,utiliza-se o algoritmo a seguir: 1. Encontrar o registro que possui a maior dissimilaridade média para todos os outros registros. Esse registro inicia um novo agrupamento- o Agrupamento Temporário (AT). 2. Para registro i fora do AT calcule:
. 2. Para registro i fora do AT calcule:")
57
Coeficiente de Divisão (CD)
3. Encontre um registro h em que a diferença Dh seja a maior. Se Dh for positiva, então h está em média próximo do AT. Mova o registro h para o AT; 4. Repetir os passos 2 e 3 até todas as diferenças Dh serem negativas. O conjunto de dados é então dividido em dois agrupamentos; 5. Escolha o agrupamento com o maior diâmetro. O diâmetro de um agrupamento é a maior dissimilaridade entre quaisquer dois registros. Então siga os passos de 1 a 4. 6. Repita os passos de 1 a 5 até que todos os agrupamentos contenham apenas um registro. Coeficiente de Divisão (CD) Para cada registro i, têm-se di significando o diâmetro do ultimo agrupamento a que ele pertenceu, dividido pelo diâmetro de toda base de dados. O CD é dado por: O CD indica a força da divisão que o algoritmo criou. Se o valor de CD for baixo, o algoritmo não conseguiu dividir bem os dados.
 Para cada registro i, têm-se di significando o diâmetro do ultimo agrupamento a que ele pertenceu, dividido pelo diâmetro de toda base de dados. O CD é dado por: O CD indica a força da divisão que o algoritmo criou. Se o valor de CD for baixo, o algoritmo não conseguiu dividir bem os dados.")
58
Representação gráfica
Dendograma

59
Base de dados da agricultura
Exemplo Base de dados da agricultura Inicialmente todos os registros estão presentes em um único agrupamento chamado C1 x y B 16.8 2.7 DK 21.3 5.7 IRL 10.9 14 L 21 3.5 UK 2.3 Media 5.64 Desvio Médio 3.48 3.368

60
1º passo: padronizar os dados
2º passo: calcular a matriz de dissimilaridades (neste caso usando a distância euclidiana) xpad ypad B 0.000 -0.873 DK 1.293 0.018 IRL -1.695 2.482 L 1.207 -0.635 UK -0.805 -0.992 B DK IRL L UK 0.00 1.57 3.76 1.23 0.81 3.87 0.66 2.33 4.26 3.59 2.04
 xpad. ypad. B DK IRL L UK B. DK. IRL. L. UK")
61
3º passo: calcular a distância média de cada registro em relação aos outros
A maior distância é do registro IRL. Então esse registro vai fazer parte do agrupamento temporário. 4º Passo: calcular Dh usando a media da distância entre h para todos os objetos que estão fora do agrupamento temporário e subtraindo pela distancia do objeto h para o agrupamento temporário. DB = {[d(B,DK), d(B,L), d(B,UK)]/3} – {d(B,IRL)} DB = = -1.82 DDK = = -2.35 DL = = -2.95 DUK = = -1.86 B DK IRL L UK Media 1.84 2.11 3.87 2.05 2.19
, d(B,L), d(B,UK)]/3} – {d(B,IRL)} DB = = DDK = = DL = = DUK = = B. DK. IRL. L. UK. Media")
62
6º passo: As distâncias médias no agrupamento C1 são recalculadas.
5º passo: como todos os valores foram negativos, então nenhum dos registros está próximo do agrupamento temporário. Então apenas IRL forma um novo agrupamento, chamado C2. 6º passo: As distâncias médias no agrupamento C1 são recalculadas. Agora é o registro UK que vai para o agrupamento temporário. C1 C2 B IRL DK L UK B DK L UK Media 1.20 1.52 1.31 1.73

63
7º passo: Dh é novamente calculado:
DB = {[d(B,DK), d(B,L)]/2} – {d(B,UK)} DB = 1.40 – 0.81 = 0.59 DK = 1.11 – 2.33 = -1.21 DL = – 2.04 = -1.10 8º passo: o registro B se une ao registro UK e formam um novo agrupamento. 9º passo: o agrupamento C1 tem diâmetro 0.81, maior que o agrupamento C2, com diâmetro de 0.66, então primeiramente seus registros são divididos em dois agrupamentos e depois o mesmo acontece com o agrupamento C2. C1 C2 C3 B DK IRL UK L
, d(B,L)]/2} – {d(B,UK)} DB = 1.40 – 0.81 = DK = 1.11 – 2.33 = DL = 0.94 – 2.04 = º passo: o registro B se une ao registro UK e formam um novo agrupamento. 9º passo: o agrupamento C1 tem diâmetro 0.81, maior que o agrupamento C2, com diâmetro de 0.66, então primeiramente seus registros são divididos em dois agrupamentos e depois o mesmo acontece com o agrupamento C2. C1. C2. C3. B. DK. IRL. UK. L.")
64
A formação final dos agrupamentos fica assim:
B UK DK L IRL

65
Dendograma

66
Método de partição Método das k-médias (k-means)
Exemplo: os dados são os mesmos que foram utilizados para os métodos hierárquicos aglomerativos e suponha que deseja-se encontrar uma partição com 2 grupos, ou seja, k=2. Sementes dos agrupamentos. Como a partição será formada por dois conjuntos necessita-se de dois centros provisórios (duas sementes, k=2) para começar o processo. Serão escolhidos os dois primeiros objetos (registros, casos, observações), isto é, A será o centro do primeiro grupo, enquanto B será o centro do segundo grupo. Veja estes resultados nas duas primeiras etapas da tabela a seguir.
 para começar o processo. Serão escolhidos os dois primeiros objetos (registros, casos, observações), isto é, A será o centro do primeiro grupo, enquanto B será o centro do segundo grupo. Veja estes resultados nas duas primeiras etapas da tabela a seguir.")
67
Designação dos objetos (registros).
Os dois primeiros objetos já foram designados aos grupos, agora é a vez dos demais e será feita segundo a ordem de leitura. O próximo indivíduo (registro) é o C. Ele será colocado no grupo mais próximo, definido pela sua proximidade ao centro. Mas para evitar o cálculo da distância, será usado um procedimento mais simples: usar-se-á apenas a primeira variável (ZALT) para medir a proximidade. Assim C de coordenada –0,44, está mais próxima do grupo 2 (0,33) do que de 1 (1,10). Assim C é alocado ao grupo 2 que têm as coordenadas do seu centro recalculadas.
 é o C. Ele será colocado no grupo mais próximo, definido pela sua proximidade ao centro. Mas para evitar o cálculo da distância, será usado um procedimento mais simples: usar-se-á apenas a primeira variável (ZALT) para medir a proximidade. Assim C de coordenada –0,44, está mais próxima do grupo 2 (0,33) do que de 1 (1,10). Assim C é alocado ao grupo 2 que têm as coordenadas do seu centro recalculadas.")
68
O novo centro do grupo 2, fica:
Veja este resultado na etapa 3 da tabela acima. Procede-se, seqüencialmente, para os casos D, E e F. Cujos resultados estão nas etapas 4, 5 e 6 da tabela da página anterior. Conforme aparece no final da tabela da página anterior, a segunda fase termina com os agrupamentos: p(1)={A,E} p(2)={B,C,D,F} Calcula-se, agora, o grau de homogeneidade interna dos grupos, através da Soma de Quadrados do Resíduo (SQRes), que é a medida usada para avaliar o quão boa foi a partição. As informações intermediárias necessárias para o cálculo da SQRes encontra-se na tabela a seguir, a qual passamos a discutir em detalhes.
={A,E} p(2)={B,C,D,F} Calcula-se, agora, o grau de homogeneidade interna dos grupos, através da Soma de Quadrados do Resíduo (SQRes), que é a medida usada para avaliar o quão boa foi a partição. As informações intermediárias necessárias para o cálculo da SQRes encontra-se na tabela a seguir, a qual passamos a discutir em detalhes.")
69
De modo geral, a soma de quadrados do resíduo para o grupo j, é dado por:
Oi(j) é o i-ésimo registro do grupo j; o(barra)(j) é o centro do grupo j; nj é o número de registros do grupo j. Sendo que: Xlij é o valor da l-ésima variável X, do i-ésimo registro e j-ésimo grupo
 é o i-ésimo registro do grupo j; o(barra)(j) é o centro do grupo j; nj é o número de registros do grupo j. Sendo que: Xlij é o valor da l-ésima variável X, do i-ésimo registro e j-ésimo grupo.")
70
SQRes(1) = 0,6272
 = 0,6272")
71
SQRes = SQRes(1) + SQRes(2) = 0,6272 + 4,0431 = 4,6703
A soma de quadrados desta partição vale: SQRes = SQRes(1) + SQRes(2) = 0, ,0431 = 4,6703
 + SQRes(2) = 0, ,0431 = 4,6703.")
72
Realocação dos registros.
Como essa é uma partição arbitrária procura-se, agora, passar para uma outra melhor, isto é, uma que diminua a Soma de Quadrados Residual. Move-se o primeiro objeto para os demais grupos e verifica-se se há ganho na Soma de Quadrados Residual, ou seja, se ocorre aumento na homogeneidade. Havendo, muda-se o objeto para aquele grupo que produz o maior ganho, recalculam-se as estatísticas e passa-se ao ponto seguinte. Quando não houver mais mudanças, ou após um certo número de iterações, pára-se o processo. A diminuição na soma de quadrados residual ao mover o registro o que está no grupo 1, para um grupo qualquer j é dado por: Onde n(.) indica o número de elementos do referido grupo. As informações desta fórmula referem-se à partição original antes da mudança do objeto.
 indica o número de elementos do referido grupo. As informações desta fórmula referem-se à partição original antes da mudança do objeto.")
73
Exemplo: para o objeto A, temos:
Já é uma indicação de que o objeto A deve permanecer no grupo 1. A diferença na soma de quadrados residual é: Aumentou a soma de quadrados residual. Portanto A continua no grupo 1. Da forma como L foi construída, quanto mais negativo for o valor, melhor.

74
Portanto, o objeto B é transferido do grupo 2
Passamos agora a investigar o objeto B ( o segundo registro), que está no grupo 2. Já é uma indicação de que o objeto B deve passar para o grupo 1. A diferença na soma de quadrados residual é: Portanto, o objeto B é transferido do grupo 2 para o grupo 1. Os centros dos novos grupos são recalculados. Calculam-se as distâncias e a soma de quadrados residual. Estes dados estão na tabela a seguir.
, que está no grupo 2. Já é uma indicação de que o objeto B deve passar para o grupo 1. A diferença na soma de quadrados residual é: Portanto, o objeto B é transferido do grupo 2. para o grupo 1. Os centros dos novos grupos são recalculados. Calculam-se as distâncias e a soma de quadrados residual. Estes dados estão na tabela a seguir.")
75
Esta SQRes também pode ser obtida pela soma de quadrado residual anterior menos L(B,1:2), ou seja, 4,6703-2,3334=2,3369. A diferença é erro de aproximação.

76
Portanto, o objeto C fica no grupo 2.
O processo continua agora com o objeto C, e da tabela do slide da página anterior temos que: Portanto, o objeto C fica no grupo 2. Repetindo-se o processo com os pontos D,E e F termina-se a primeira iteração com: Recomeçando a segunda iteração com A, depois com B, etc, não será feita mais nenhuma realocação. Assim, o processo termina produzindo a partição acima.

77
Problemas Existem diversos algoritmos para análise de conglomerados. Não existe um método, em geral, considerado como sendo o melhor. Infelizmente, algoritmos diferentes não necessariamente produzem os mesmos resultados quando aplicados numa base de dados e existe um componente de subjetividade na determinação dos resultados da análise de conglomerados. Uma maneira de verificar a estabilidade do agrupamento consiste em dividir a base de dados, aleatoriamente, em dois subconjuntos e aplicar o mesmo método (com o mesmo critério) em cada um deles. Se o agrupamento for estável, a alocação dos objetos nos subconjuntos será semelhante àquela da base de dados. Um teste para qualquer algoritmo é tomar um conjunto de dados com grupos conhecidos à priori (pode ser por simulação) e verificar se o algoritmo é capaz de reproduzir os mesmos grupos. A escolha das variáveis deve ser feita de acordo com o agrupamento desejado.
 em cada um deles. Se o agrupamento for estável, a alocação dos objetos nos subconjuntos será semelhante àquela da base de dados. Um teste para qualquer algoritmo é tomar um conjunto de dados com grupos conhecidos à priori (pode ser por simulação) e verificar se o algoritmo é capaz de reproduzir os mesmos grupos. A escolha das variáveis deve ser feita de acordo com o agrupamento desejado.")
78
Medidas de distância Os dados para a análise de agrupamentos usualmente consiste dos valores de p variáveis X1, X2,...,Xp, para n registros. Existem diversas medidas de distâncias para cada tipo de variável. Por exemplo, para variáveis quantitativas temos a distância Euclidiana, distância de Mahalanobis; para variáveis qualitativas dicotômicas temos, por exemplo, a distância Euclidiana média, coeficiente de concordância simples, etc; Por exemplo a distância Euclidiana é calculada por: Onde xik é o valor da variável Xk para o indivíduo (registro) i e xjk é o valor da mesma variável para o indivíduo j. Usualmente as variáveis são padronizadas antes de se calcular as distâncias, assim, as p variáveis serão igualmente importantes. Geralmente, a padronização feita é para que todas as variáveis tenham média zero e variância 1.
 i e xjk é o valor da mesma variável para o indivíduo j. Usualmente as variáveis são padronizadas antes de se calcular as distâncias, assim, as p variáveis serão igualmente importantes. Geralmente, a padronização feita é para que todas as variáveis tenham média zero e variância 1.")
79
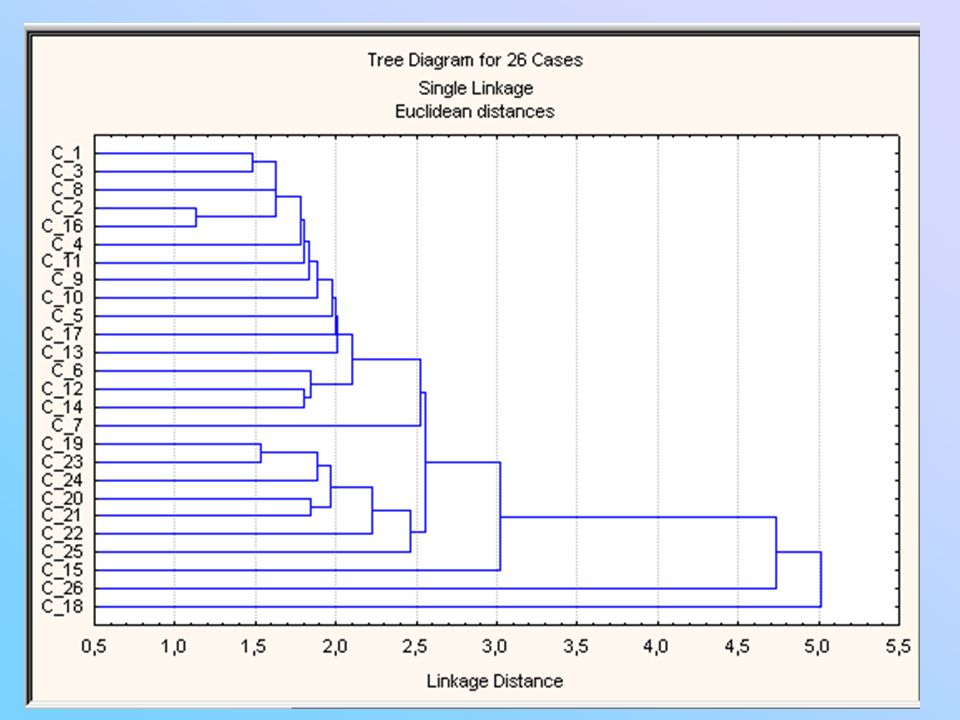
Exemplo Agrupamentos dos países europeus. Vamos usar os dados de porcentagens de pessoas empregadas em 9 grupos industriais em diferentes países. Parte dos dados foram apresentados na seção de análise de componentes principais. A análise deveria mostrar quais países tem padrões similares de emprego e quais países são diferentes com relação ao emprego. O primeiro passo na análise envolve a padronização dos dados, ou seja, cada variável terá média zero e variância 1. Os valores padronizados são mostrados na tabela do próximo slide. Por exemplo, para Bélgica e Agricultura, temos:

81
O próximo passo da análise é calcular a distância Euclidiana entre todos os pares de países. Isto foi feito em cima dos dados padronizados. O dendograma foi feito através do método hierárquico aglomerativo do vizinho mais próximo, como descrito anteriormente. O dendograma é mostrado no próximo slide. Conclusões: Pode ser visto que os dois países mais próximos são Suécia (Sweden) e Dinamarca (Denmark). A distância que separa um do outro é de 1,135. O próximo par de países mais semelhantes é Bélgica (Belgium) e França (France), cuja distância que separa um do outro é 1,479. O próximo é Polônia (Poland) e Bulgária, com distância de 1,537. A união (ligação) termina com a Turquia (Turkey) juntando-se com os outros países a uma distância de 5,019. Dado o dendograma (diagrama em árvore), podemos decidir sobre o número de grupos a considerar. Por exemplo, se decidirmos considerar seis grupos, a distância de ligação será 2,459.
 e Dinamarca (Denmark). A distância que separa um do outro é de 1,135. O próximo par de países mais semelhantes é Bélgica (Belgium) e França (France), cuja distância que separa um do outro é 1,479. O próximo é Polônia (Poland) e Bulgária, com distância de 1,537. A união (ligação) termina com a Turquia (Turkey) juntando-se com os outros países a uma distância de 5,019. Dado o dendograma (diagrama em árvore), podemos decidir sobre o número de grupos a considerar. Por exemplo, se decidirmos considerar seis grupos, a distância de ligação será 2,459.")
83
Parte da matriz de distâncias:

84
Primeiro grupo: nações do oeste
Bélgica, França, Holanda, Suécia, Dinamarca, Alemanha Ocidental, Finlândia, Reino Unido, Áustria, Irlanda, Suíça, Noruega, Grécia, Portugal e Itália Segundo grupo: Luxemburgo Terceiro grupo: antigos países comunistas Rússia, Hungria, Tchecoslováquia, Alemanha Oriental, Romênia, Polônia e Bulgária

85
Quarto grupo: Espanha Quinto grupo: Yugoslavia Sexto grupo: Turquia

86
Com os dados padronizados, pode ser visto que Luxemburgo é diferente devido a grande percentagem de empregados em mineração. Espanha é diferente devido a grande porcentagem de empregados na área da construção. Yugoslavia é diferente devido ao grande número na agricultura e finanças e baixos números na construção, serviços sociais e pessoais, e transporte e comunicação. Turquia tem valor extremamente alto na agricultura e números baixos na maioria das outras áreas. Comparação com a análise de componentes principais: Os seis grupos formados pela análise de agrupamentos pode ser comparada com o gráfico dos países contra os dois componentes principais dos dados (figura no próximo slide). Os resultados são bastante próximos, porém não há uma total concordância: Países no mesmo cluster tendem a ter valores similares para os primeiros dois componentes principais.
. Os resultados são bastante próximos, porém não há uma total concordância: Países no mesmo cluster tendem a ter valores similares para os primeiros dois componentes principais.")
87
Espanha

Apresentações semelhantes
 – Lápides 1, 2, 3» «nomes gravados, 21 de Agosto de 2008» «Ultramar.TerraWeb»>")




. Nenhuns direitos reservados, excepto para fins comerciais. Por favor, não coloque.>")













