Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Aula 6 - Método não-experimental ou de seleção não-aleatória
Material Elaborado por Betânia Peixoto

2
Método não-experimental ou de seleção não-aleatória
Uma das metodologia para realizar a avaliação de impacto quando a seleção entre tratados e controle é não-aleatória.

3
Plano de Aula Um pouco de econometria.
Regressão Linear: intuição e procedimentos. Relação entre outras variáveis que afetam o indicador de interesse e que são diferentes entre os grupos. Viés de variável omitida. Discussão do problema existente para a avaliação quando a seleção entre tratados e não-tratados não foi aleatória.

4
Método não-experimental ou de seleção não-aleatória
Nos projetos sociais, em geral, a seleção dos participantes do programa não é feita de forma aleatória: ou porque dentro dos elegíveis, selecionamos, por exemplo, os mais vulneráveis. Quando a seleção não é aleatória não temos mais um grupo de controle automático. ou porque todas as pessoas elegíveis para participar do programa efetivamente participam do programa,

5
Regressão Idéia: esse instrumental permite verificar a relação entre as características que afetam o indicador de impacto, inclusive o programa, independente uma das outras. A regressão linear permite ver a relação entre múltiplas variáveis com o indicador de impacto.

6
Objetivo O objetivo da análise de regressão é encontrar uma função linear que permita: Descrever e compreender a relação entre uma variável dependente e uma ou mais variáveis independentes. 6

7
Modelo de Regressão Linear Simples- Exemplo 1
Suponha que o objetivo é verificar a relação entre o número de efetivo policial alocado nos municípios e o número de homicídios nestes município, para realizar projeções de alocação policial. A tabela seguinte registra uma amostra representativa extraída dos registros dos municípios, com número de efetivo policial e número de crime. Analisar a possibilidade de definir um modelo que represente a relação entre as duas variáveis ou amostras.

8
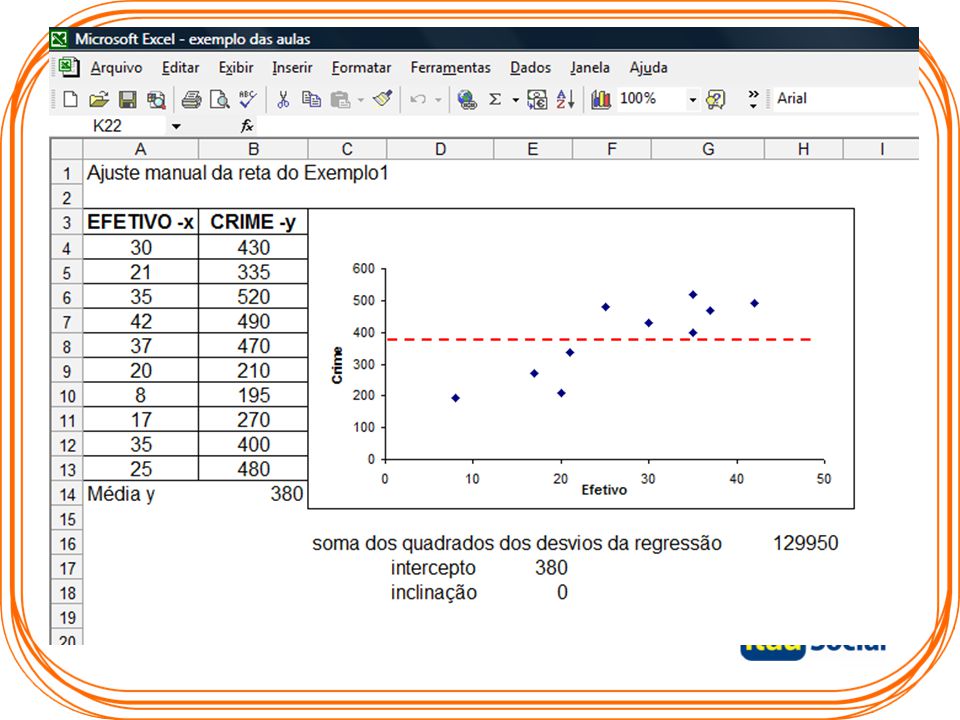
Solução Para analisar a relação entre as duas variáveis no Exemplo 1, foi construído o gráfico de dispersão dos crimes em função do efetivo policial. Nesse gráfico pode-se ver que os municípios com mais policiais têm mais crimes.

9
O gráfico de dispersão mostra que os crimes e o efetivo estão correlacionados de forma positiva.
A linha tracejada foi ajustada tentando equilibrar os pontos acima da reta com os pontos abaixo dela. Essa reta é uma das muitas possíveis retas que poderiam ser ajustadas.

10
Modelo do Ajuste de uma Reta
O ajuste de uma reta é um modelo de regressão linear que relaciona a variável dependente y e a variável independente x por meio da equação de uma reta do tipo: É importante observar que, da mesma forma como a média resume uma variável aleatória, a reta de regressão resume a relação linear entre duas variáveis aleatórias e, conseqüentemente, da forma como a média varia entre amostras do mesmo tamanho extraídas da mesma população, as retas também variarão entre amostras da mesma população. 10

11
Exemplo: Relação quadrática entre y e x
Observação A linearedade contida na função da regressão linear é referente apenas aos parâmetros, não nas variáveis. Assim o método permite construir funções lineares nos parâmetros, mas que expressão relação não linear entre as variáveis y e x. Exemplo: Relação quadrática entre y e x 11

12
Voltando ao Exemplo 1 O objetivo do Exemplo 1 é ajustar uma reta a partir dos valores das amostras retiradas da população, considerando que a alocação de efetivo é a variável independente x, e os crimes, a variável dependente y. Uma primeira forma de fazer isso é ajustar manualmente essa reta tentando equilibrar os pontos acima e abaixo dessa reta, como foi feito no gráfico do Exemplo 1. Como esse procedimento permite o ajuste de diversas retas, é necessário estabelecer um objetivo de eficiência de ajuste possível de medir, como é mostrado a seguir.

13
Critério de ajuste 1: Uma primeira forma é ajustar uma reta horizontal de valor igual à média dos valores da variável dependente y, que é uma reta de regressão com b=0. Esse critério não necessita de regressão.

15
Critério de ajuste 2: Outra forma é ajustar uma reta que divida os pontos observados de forma que a soma dos desvios seja nula. Entretanto, como há muitas retas que cumprem com essa condição, esse critério não poderá ser utilizado.

16
Critério de ajuste da regressão
Outra forma é ajustar uma reta de forma que minimize a soma dos quadrados dos desvios, (lembre a definição de variância). O objetivo da regressão é encontrar os coeficientes a e b da reta de regressão que minimizam a soma dos quadrados dos desvios dos valores da amostra y com relação aos correspondentes valores da reta de regressão. Lembrando que: A variância faz o somatório dos quadrados dos desvios no numerador
. O objetivo da regressão é encontrar os coeficientes a e b da reta de regressão que minimizam a soma dos quadrados dos desvios dos valores da amostra y com relação aos correspondentes valores da reta de regressão. Lembrando que: A variância faz o somatório dos quadrados dos desvios no numerador.")
17
Interpretando: O coeficiente “b” é a declividade da reta e define o aumento ou diminuição da variável y por unidade de variação da variável x. A constante “a” é o valor de y quando x=0

18
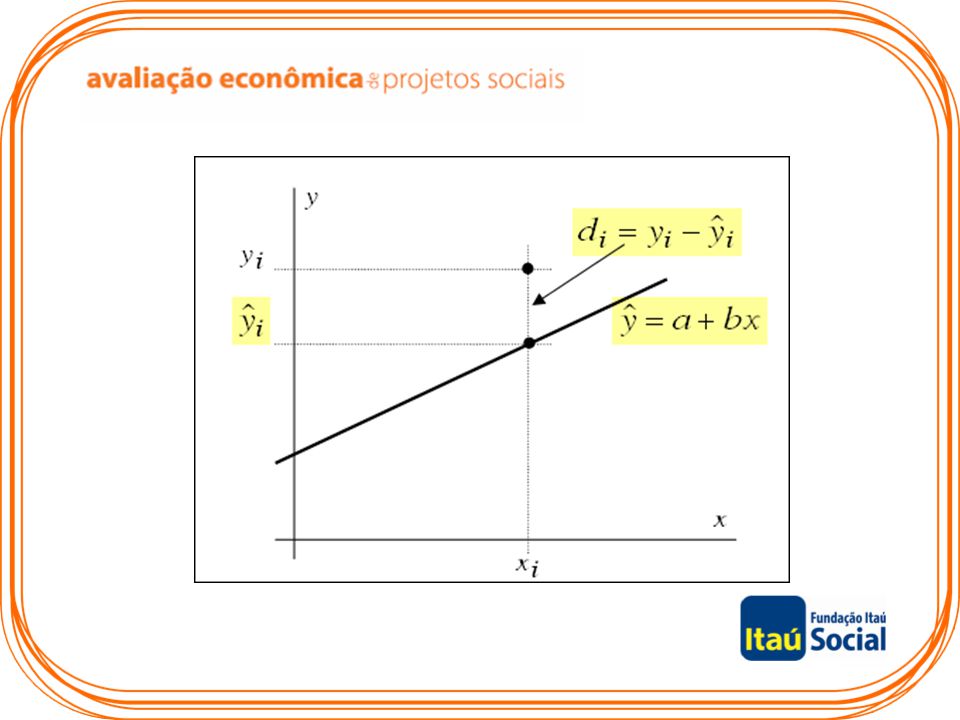
Estimação No modelo estimado para o ajuste da reta se verifica que:
Para um único valor de xi pode haver um ou mais valores de yi. Por exemplo, no gráfico de dispersão do exemplo 1 para x=35 há dois valores das variáveis dependentes y=400 e y=520. Mas há apenas um único estimado para cada valor de xi. Para cada valor de xi há uma diferença entre o valor observado yi e o valor estimado Essa diferença é denominada desvio (di).
.")
20
Y=117,07+9,73X Lembrar que como estamos trabalhando com amostra temos que ter um teste para ver se na população este resultado é válido. O teste agora, em vez de usar a distribuição Z usa a distribuição t. H0: se b = 0 e H1: b ≠ 0. Usa-se o teste da distribuição t de Student porque ela é mais adequada para pequenas amostras. Quando o número de observações aumenta a distribuição t tende a Normal. Assim para garantir as análise se regressão utilizam apenas o teste t. O calculo do coeficiente t é similar ao do teste Z aprendido anteriormente, mas não entraremos nos detalhes nesta aula. Podemos olhar na tabela t assim como fizemos na tabela Z O resultado da regressão já traz calculado o Pvalue ou Valor-P que é a probabilidade de erro em rejeitarmos H0.

22
Variável Omitida Será que não existe mais dada que afeta o crime além do efetivo policial? Quando omitimos variáveis que deveriam estar presentes em uma equação de regressão o efeito omitido estará contido no termo do erro, fazendo com que a reta não seja bem ajustada. Veremos a frente o que acontece no exemplo anterior quando incluimos a variável populaçao na regressão.

23
Regressão Linear Múltipla
O modelo de regressão linear que foi apresentado é o mais simples deles e nem sempre atende à modelagem mais complexa, como a de avaliação de impacto. Por exemplo, como vimos no Exemplo 1, o número de crimes não dependem somente do efetivo, pois há uma parte da variação dos crimes que não é explicada pelo efetivo policial.

24
O desenvolvimento da equação de regressão linear múltipla é similar ao da equação de regressão linear simples incluindo a dependência de duas ou mais variáveis independentes. A ferramenta de análise Regressão realizam análises de regressão múltipla.

25
Regressão Linear Multipla
Dispondo de um grupo de amostras do mesmo tamanho, sendo uma variável dependente y e n variáveis independentes xi, o objetivo é determinar os coeficientes da equação da reta: cujos coeficientes minimizam a soma dos quadrados dos desvios da variável com relação a y.

26
Exemplo 2 Neste exemplo, queremos relacionar a quantidade de crime y com o número de efetivo x1 e o tamanho da população (x2 em milhares). Para encontrar essa relação linear foi extraída a amostra de valores de municípios.

27
O coeficiente do efetivo passa a ser negativo.

28
Observações Importantíssimas
Os coeficientes estimados medem a relação da variável x com y livre do efeito das demais variáveis incluídas no modelo. Como a distância de yi a , (ou desvio) não é zero para todas as observações, existe um erro de estimação quando falamos em regressão linear. Y^ e o y estimado 28
 não é zero para todas as observações, existe um erro de estimação quando falamos em regressão linear. Y^ e o y estimado. 28.")
29
Problema da avaliação Relembrando:
Impacto = ATT = E[Yp, P=1] - E[Ysp, P=1] Não observamos Ysp quando P=1. Se E[Ysp, P=1] ≠ E[Yc, P=0] Erro: ε= E[Ysp, P=1] - E[Yc, P=0] (1) O ATT é dado por: ATT = E[Yp, P=1] - E[Yc, P=0] + ε (2) Substituindo (1) em (2) ATT = E[Yp, P=1] - E[Yc, P=0] + {E[Ysp, P=1] - E[Yc, P=0] } Viés ou erro Yc = indicador de impacto dos nao participantes do grupo controle 29
 O ATT é dado por: ATT = E[Yp, P=1] - E[Yc, P=0] + ε (2) Substituindo (1) em (2) ATT = E[Yp, P=1] - E[Yc, P=0] + {E[Ysp, P=1] - E[Yc, P=0] } Viés ou erro. Yc = indicador de impacto dos nao participantes do grupo controle. 29.")
30
O Erro ou Viés O Erro é causado pelas características diferentes entre tratado e controle que levam à que o indicador de impacto seja diferente entre os grupos. 30

31
Como fazer então... ...quando temos um grupo de controle com características diferentes do grupo de tratamento, características essas que afetam o indicador de interesse? Aplicamos a regressão para controlarmos o impacto do programa do efeito das variáveis que tornam os grupos tratado e controle diferentes.

32
Regressão Aplicada à Avaliação de Impacto
Procedimentos: Quais são as características que tornam os grupos diferentes e que afetam o indicador de impacto individual? Em um programa para melhorar o desempenho escolar das crianças poderia ser: educação dos pais, renda familiar, região onde moram, saneamento básico, se participam de outro programa social, ...

33
Procedimentos ‘Estimar a regressão em que o indicador de impacto é a variável dependente. As variáveis independentes são uma dummy para a participação do programa e as demais variáveis que tornam os grupos diferentes e que afetam o indicador de impacto. Ou seja, queremos olhar o efeito da participação no programa (dummy de participação) livre do efeito das demais características que tornam os grupos diferentes e afetam esse indicador.
 livre do efeito das demais características que tornam os grupos diferentes e afetam esse indicador.")
34
Modelo de Regressão Linear
Para isso vamos escrever a seguinte equação: Indicador de impacto = + *programa + *x2 + *x3 +*x4+...+ Programa = 1 se o indivíduo participa do programa. Programa = 0 se o indivíduo não participa do programa.

35
Interpretação identifica o indicador de impacto de quem recebe zero em todas as variáveis. , , ,... indicam a relação/associação de cada variável com o indicador de impacto, livre do efeito das demais variáveis incluídas no modelo. é o erro que existe por não conseguirmos determinar perfeitamente o indicador de impacto

36
Impacto “” mede o impacto de participar do programa sobre o indicador de impacto, livre do efeito das outras variáveis incluídas. Mas não esqueçam, temos que fazer o teste t de hipótese para ver se o resultado se mantém na população. H0: = 0 H1: ≠ 0

37
Ou seja: A regressão linear nos dará uma medida de (e dos demais coeficientes), bem como o teste t e o p-valor dos coeficientes. Vários programas estatísticos podem ser usados para ‘estimar’ essa equação...

38
Limitações do método em avaliação
Se tratado e controle forem muito diferentes teremos viés no impacto estimado decorrentes de: Variáveis Omitidas (observáveis e não observáveis) Ausência de suporte comum 38
 Ausência de suporte comum. 38.")
39
Na prática Obter observações de Y para participantes e para não participantes [Y é o indicador para o qual queremos avaliar se houve impacto]. Criar a variável programa (1 para quem participou e zero para quem não participou). Obter observações das variáveis que afetam o indicador de interesse e que são diferentes entre os participantes e os não participantes.
![Na prática Obter observações de Y para participantes e para não participantes [Y é o indicador para o qual queremos avaliar se houve impacto].](http://slideplayer.com.br/slide/2612004/9/images/39/Na+pr%C3%A1tica+Obter+observa%C3%A7%C3%B5es+de+Y+para+participantes+e+para+n%C3%A3o+participantes+%5BY+%C3%A9+o+indicador+para+o+qual+queremos+avaliar+se+houve+impacto%5D..jpg "Criar a variável programa (1 para quem participou e zero para quem não participou). Obter observações das variáveis que afetam o indicador de interesse e que são diferentes entre os participantes e os não participantes.")
40
Y = + *programa + *X1 + *X2 + ;
Estimar a equação: Y = + *programa + *X1 + *X2 + ; Y = indicador de resultado de interesse. programa = variável de interesse (igual a 1 caso o indivíduo tenha participado do programa). X1, X2 = variáveis que são correlacionadas com o Y e que são diferentes entre os grupos de tratamento e de controle.
. X1, X2 = variáveis que são correlacionadas com o Y e que são diferentes entre os grupos de tratamento e de controle.")
41
Comentários Finais Aula de hoje: aprendemos a realizar a avaliação de impacto quando a seleção de tratados e não-tratados não foi aleatória. Na próxima aula: aprenderemos um método para aperfeiçoar a seleção dos controles de forma que a aplicação do método aprendido hoje será mais confiável.

Apresentações semelhantes