Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Regressão Linear Múltipla
Rejane Sobrino Pinheiro Tânia Guillén de Torres

2
Regressão linear múltipla
Introdução Pode ser vista como uma extensão da regressão simples Mais de uma variável independente é considerada. Lidar com mais de uma variável é mais difícil, pois: É mais difícil escolher o melhor modelo, uma vez que diversas variáveis candidatas podem existir É mais difícil visualizar a aparência do modelo ajustado, mais difícil a representação gráfica em mais de 3 dimensões Às vezes, é difícil interpretar o modelo ajustado Cálculos difíceis de serem executados sem auxílio de computador

3
Exemplo: Supondo dados de peso, altura e idade de 12 crianças:
A regressão múltipla pode ser usada para estudar o peso e sua variação em função da altura e idade das crianças.

4
Modelo O modelo de Regressão Linear Múltipla é representado pela equação: As constantes: 0, 1, 2, ...,k, são os parâmetros populacionais. Os estimadores são representadas por: Um exemplo de regressão linear múltipla pode ser dado a partir da inclusão de um termo de ordem mais elevada, como X2. Embora seja a mesma variável (X), esta pode ser interpretada como uma segunda variável (X2).
, esta pode ser interpretada como uma segunda variável (X2).")
5
Usos da Regressão Múltipla
Ajustar dados: estudar o efeito de uma variável X, ajustando ou levando em conta outras variáveis independentes. Obter uma equação para predizer valores de Y a partir dos valores de várias variáveis X1, X2, ...,Xk . Explorar as relações entre múltiplas variáveis ( X1, X2, ..., Xk ) para determinar que variáveis influenciam Y.
 para determinar que variáveis influenciam Y.")
6
A solução dos mínimos quadrados é a que minimiza a soma dos quadrados dos desvios entre os valores observados e a superfície de regressão ajustada.

7
Pressupostos da Regressão Linear Múltipla
Os pressupostos da regressão linear simples podem ser estendidos para a regressão linear múltipla Existência: Para uma combinação específica das variáveis independentes X1, X2, ...,Xk, Y é uma variável aleatória com uma certa distribuição de probabilidade, com média e variância finitas. Independência: As observações de Y são estatisticamente independentes umas das outras. Este pressuposto é violado quando mais de uma observação é feita de um mesmo indivíduo.

8
Pressupostos da Regressão Linear Múltipla (cont...)
3.Linearidade: O valor médio de Y para cada combinação específica de X1, X2, ...,Xk é uma função linear de X1, X2, ...,Xk. Ou componente de erro do modelo, refletindo a diferença entre o valor observado para um indivíduo e a verdadeira resposta média para o conjunto de indivíduos de mesmas características. A relação entre Y e Xi é linear ou é bem aproximada por uma função linear.

9
Pressupostos da Regressão Múltipla (cont...)
4. Homocedasticidade: A variância de Y é a mesma para qualquer combinação fixa de X1, X2, ...,Xk. Este pressuposto pode parecer muito restritivo. Heterocedasticidade deve ser considerada somente quando os dados apresentarem óbvia e significante não homogeneidade das variâncias. Em geral, não considerar a homocedasticidade não acarreta efeitos adversos nos resultados. 5. Amostra aleatória ou representativa da população.

10
Pressupostos da Regressão Múltipla (cont...)
6. Normalidade: para uma combinação fixa de X1, X2, ..., Xk, a variável Y tem distribuição normal. Y ~ N ( , 2) Ou de modo equivalente ~N (0, 2)
 Ou de modo equivalente. ~N (0, 2)")
11
Pressupostos da Regressão Múltipla
7. Normalidade de Y Este pressuposto não é necessário para o ajuste do modelo usando os mínimos quadrados, mas é importante para a realização da inferência. Os testes de hipóteses paramétricos usuais e os cálculos dos intervalos de confiança utilizados nas análises de regressão são bastante robustos, de modo que somente em casos em que a distribuição de Y se afaste muito da distribuição normal os resultados gerados serão inadequados. No caso de não normalidade, transformações matemáticas de Y podem gerar conjunto de dados com distribuição aproximadamente normal (Log Y, Y); no caso de variável Y categórica nominal ou ordinal, métodos de regressão alternativos são necessários (logística - dados binários, Poisson - dados discretos) A Homocedasticidade e a Normalidade se aplicam à distribuição condicional de Y | X1, X2, ...,Xk
; no caso de variável Y categórica nominal ou ordinal, métodos de regressão alternativos são necessários (logística - dados binários, Poisson - dados discretos) A Homocedasticidade e a Normalidade se aplicam à distribuição condicional de Y | X1, X2, ...,Xk.")
12
Determinando a melhor estimativa para o modelo de regressão múltipla
A abordagem dos mínimos quadrados Minimiza a soma dos quadrados dos erros ou as distâncias entre os valores observados (Yi) e os valores preditos pelo modelo ajustado.
 e os valores preditos pelo modelo ajustado.")
13
A solução de mínimos quadrados consiste nos valores de
A solução de mínimos quadrados consiste nos valores de (chamados de estimadores de mínimos quadrados) para os quais a soma da equação anterior é mínima. Cada um dos estimadores é uma função linear dos valores de Y. Se os valores de Y são normalmente distribuídos e são independentes entre si, os estimadores terão distribuição normal, com desvios padrões facilmente computáveis.
 para os quais a soma da equação anterior é mínima. Cada um dos estimadores é uma função linear dos valores de Y. Se os valores de Y são normalmente distribuídos e são independentes entre si, os estimadores terão distribuição normal, com desvios padrões facilmente computáveis.")
14
Supondo dados de peso, altura e idade de 12 crianças:
Exemplo: Supondo dados de peso, altura e idade de 12 crianças: A velocidade do efeito da idade diminui com o passar da idade Apresentar o efeito da idade para determinadas faixas: Peso1 para crianças de X anos Peso2 para crianças de Z anos X – Z Peso1 - Peso2

15
Interpretação dos coeficientes
O coeficiente apresentado na tabela refere-se ao coeficiente parcial da regressão e difere do da regressão simples considerando a relação de cada variável independente em separado. O coeficiente expressa o aumento médio em Y dado um aumento de 1 unidade de X, sem considerar o efeito de qualquer outra variável independente (mantendo todos os outros fatores constantes). Para um aumento de 1 unidade na altura, há um aumento médio de no peso, para crianças de mesma idade.
. Para um aumento de 1 unidade na altura, há um aumento médio de no peso, para crianças de mesma idade.")
16
O coeficiente da regressão padronizado
Interesse em ordenar os coeficientes por grau de importância na predição de Y. Difícil comparar os coeficientes da regressão para saber qual variável independente possui maior associação com a variável dependente Y, pois cada variável está em uma unidade diferente. O coeficiente padronizado permite comparação da importância de cada variável para a predição de Y. Se X aumenta em 1 desvio padrão (Sx), indo para x + Sx, então Y aumentaria .Sx unidades. Caso seja desejado que o aumento em Y seja dado em desvios padrões de Y, podemos dividir a expressão por SY, para saber quantos desvios padrões possui o termo .Sx .Sx/Sy O coeficiente padronizado da regressão (standard estimates) representa o aumento médio em Y (expresso em unidades de desvio padrão de Y) por um aumento de 1 desvio padrão em X, depois de ajustado por todas as outras variáveis do modelo
, indo para x + Sx, então Y aumentaria .Sx unidades. Caso seja desejado que o aumento em Y seja dado em desvios padrões de Y, podemos dividir a expressão por SY, para saber quantos desvios padrões possui o termo .Sx. .Sx/Sy. O coeficiente padronizado da regressão (standard estimates) representa o aumento médio em Y (expresso em unidades de desvio padrão de Y) por um aumento de 1 desvio padrão em X, depois de ajustado por todas as outras variáveis do modelo.")
17
padronizado

18
Se fizermos gráficos separados entre as diversas variáveis, poderemos ter uma visão de pedaços ou projeções da superfície ajustada. Suponhamos que a superfície seja um plano (relação linear entre todos os fatores).
..")
19
SSY= SSR + SSE R2 = (SSY-SSE)/SSY
A tabela ANOVA da Regressão Múltipla Como no modelo de Regressão Simples: SSY= SSR + SSE R2 = (SSY-SSE)/SSY R2 sempre cresce à medida que mais variáveis são incluídas no modelo. Um acréscimo muito pequeno em R2 pode não apresentar importância prática ou importância estatística. Variação total não explicada = Variação devida à regressão + variação residual não explicada
/SSY. R2 sempre cresce à medida que mais variáveis são incluídas no modelo. Um acréscimo muito pequeno em R2 pode não apresentar importância prática ou importância estatística. Variação total não explicada = Variação devida à regressão + variação residual não explicada.")
20
P = Fcrítico = Fk,n-k-1,1-

21
SSY SSE Aqui, trabalha-se com os dados originais

22
Modelo 1: PESO = 0 + 1 ALTURA +
^ 1 Modelo 1: PESOi = ALTURA + i

23
Modelo 2: PESO = 0 + 1 IDADE +

24
Modelo 3: PESO = 0 + 1 ALTURA + 2IDADE +
O modelo 3 possui melhor ajuste dos 3 modelos apresentados (maior R2).
.")
25
Modelo 4: PESO = 0 + 1 ALTURA + 2IDADE + 3(IDADE)2 +
R2 modelo 3 = e R2 modelo 4 = ==> 0.780? Modelo 3 mais parcimonioso. Efito da colinearidade – fx pequena de idade; e a relação deve ser uma reta

26
Teste de hipótese em Regressão Múltipla
Uma vez que o modelo está ajustado, algumas questões com respeito ao ajuste e sobre a contribuição de cada variável independente para a predição de Y são importantes. São 3 questões básicas a serem respondidas: 1. Teste sobre a contribuição global de todas as variáveis tratadas coletivamente, o conjunto completo das variáveis (ou, equivalentemente, o modelo ajustado propriamente dito) contribui significativamente para a predição de Y? 2. Teste da adição de uma variável a adição de uma variável independente em particular melhora significativamente a predição de Y (a predição que foi alcançada pelas variáveis já existentes no modelo)? 3. Teste sobre a inclusão de um grupo de variáveis a adição de um conjunto de variáveis independentes melhora significativamente a predição de Y obtida pelas outras variáveis já previamente incluídas no modelo?
 contribui significativamente para a predição de Y 2. Teste da adição de uma variável a adição de uma variável independente em particular melhora significativamente a predição de Y (a predição que foi alcançada pelas variáveis já existentes no modelo) 3. Teste sobre a inclusão de um grupo de variáveis a adição de um conjunto de variáveis independentes melhora significativamente a predição de Y obtida pelas outras variáveis já previamente incluídas no modelo")
27
Estas perguntas são tipicamente respondidas com a realização de testes de hipóteses.
Os testes podem ser expressos via o teste F. Em alguns casos, este teste pode ser equivalentemente realizado usando-se o teste t. Todo teste F em regressão envolve uma razão de variâncias estimadas MS = SS/graus de liberdade Fcrítico=Fnumerador, denominador, 1-nível de significância do teste

28
1. Teste para o modelo global
Um modelo contendo k variáveis independentes como a seguir: A hipótese nula para este teste: "Todas as k variáveis independentes consideradas conjuntamente não explicam significativa quantidade de variação de Y“ H0: 1 = 2 = ... = k = 0 H1: ao menos 1 0 (pelo menos 1 variável contribui significativamente para a predição de Y) Sob a hipótese H0, o modelo completo pode ser resumido ao intercepto 0 Se uma variável auxiliar na predição (determinado 0), H0 é rejeitada mesmo que os outros 's sejam = 0.
 Sob a hipótese H0, o modelo completo pode ser resumido ao intercepto 0. Se uma variável auxiliar na predição (determinado 0), H0 é rejeitada mesmo que os outros s sejam = 0.")
29
Para realização do teste, usam-se os termos médios quadráticos do modelo e do resíduo, como na regressão simples, para cálculo da estatística F:

30
O teste F calculado pode ser comparado com o ponto crítico da dstribuição F Fk,n-k-1,1-
nível de significância. H0 é rejeitada se o valor calculado exceder o valor crítico. F pode ser escrito em função de R2.

31
Se os erros têm distribuição normal e se H0 é verdadeira, a estatística F tem distribuição F com k e n-k-1 graus de liberdade. Para um nível de significância , temos que: F crítico: Fk,n-k-1,1- rejeita H0 para F calculado maior que F crítico. Interpretação de H0 rejeitada a amostra sugere que as variáveis independentes consideradas cojuntamente ajudam na predição da variável dependente Y. Não significa que todas as variáveios sejam necessárias para a predição de Y. Modelo mais parcimonioso pode ser adotado?

32
2. O teste F parcial A partir da tabela ANOVA, informação adicional pode ser obtida com respeito ao ganho na predição pela inclusão de variáveis independentes. X1 = ALTURA , X2 = IDADE , X3 = (IDADE)2 1. X1 = ALTURA sozinha prediz Y? 2. A inclusão de X2 = IDADE contribui significativamente para a predição de Y, após considerar (ou controlar por) X1? 3. A inclusão de X3 - (IDADE)2 - contribui significativamente para a predição de Y, após controlar por X1 e X2? SS(X1) soma dos quadrados explicada por somente X1 para predição de Y. SS(X2|X1) soma dos quadrados explicada extra pela inclusão de X2 em adição à X1 para predição de Y. SS(X3|X1,X2) soma dos quadrados explicada extra pela inclusão de X3 em adição à X1 e X2 para predição de Y
2. 1. X1 = ALTURA sozinha prediz Y 2. A inclusão de X2 = IDADE contribui significativamente para a predição de Y, após considerar (ou controlar por) X1 3. A inclusão de X3 - (IDADE)2 - contribui significativamente para a predição de Y, após controlar por X1 e X2 SS(X1) soma dos quadrados explicada por somente X1 para predição de Y. SS(X2|X1) soma dos quadrados explicada extra pela inclusão de X2 em adição à X1 para predição de Y. SS(X3|X1,X2) soma dos quadrados explicada extra pela inclusão de X3 em adição à X1 e X2 para predição de Y.")
33
Para responder à pergunta 1, basta ajustar um modelo linear simples (X1 = ALTURA).
SSY = SSR + SSE F = MSR extra MSE completo FIXO Y X x1 SSR2 SSY SSE2 SSR1 SSE1 SSR1,2

34
299.33 n-k-1 F=103.9/1 / (195.19+0.24)/9 12-k-1 SS(X1) = 588.92
SS(X2|X1) = SSR (X2|X1) = = SSE (X2|X1) = = SS(X3|X1,X2) = SSR (X3|X1,X2) = = SSE (X3|X1,X2) = = 0.24 SSR do modelo linear simples e SSE = ( ) 10 (8+1+1) g.l. = 299.33 n-k-1 588/(299.33/10) X1 X2|X1 X3|X1,X2 F=103.9/1 / ( )/9 12-k-1
 = SSR (X2|X1) = = SSE (X2|X1) = = SS(X3|X1,X2) = SSR (X3|X1,X2) = = SSE (X3|X1,X2) = = SSR do modelo linear simples e SSE = ( ) 10 (8+1+1) g.l = n-k /(299.33/10) X1. X2|X1. X3|X1,X2. F=103.9/1 / ( )/9. 12-k-1.")
35
n-k-1 588/(299.33/10) X1 X2|X1 X3|X1,X2
 X1 X2|X1 X3|X1,X2")
36
Y = 0 + 1X1 + 2X2 +...+ pXp + *X* +
n-(p+1)-1 n- k-1 = p+1 9 g.l. 195.43 X1 X2|X1 X3|X1,X2 F=103.9/1 / ( )/9 12-k-1
-1 n- k-1 = p+1. 9 g.l X1. X2|X1. X3|X1,X2. F=103.9/1 / ( )/9. 12-k-1.")
37
SS(X3|X1,X2) = SSR (X3|X1,X2) = 693. 06 - 692. 82 = 0
SS(X3|X1,X2) = SSR (X3|X1,X2) = = SSE (X3|X1,X2) = = 0.24 n-k-1 p+1 8 g.l. 195.19 X1 X2|X1 X3|X1,X2
 = SSR (X3|X1,X2) = = SSE (X3|X1,X2) = = n-k-1 p+1. 8 g.l X1. X2|X1. X3|X1,X2.")
38
O teste F para testar se existe uma regressão linear significante quando usa-se apenas X1 = ALTURA para predição de Y é dada por: Para responder às perguntas 2 e 3, devemos usar o teste F parcial. Este teste avalia se a inclusão de uma variável independente específica, mantendo as já existentes no modelo, contribui significativamente para a predição de Y. O teste auxilia na exclusão de variáveis que não auxiliam na modelagem, mantendo o modelo mais parcimonioso preditores "importantes".

39
A hipótese nula - Teste parcial
Incluir X* melhora significativamente a predição de Y (outros X's já estão no modelo)? H0: "X* NÃO melhora significativamente a predição de Y, dados X1, X2,...,Xp existentes no modelo” H0: * = 0 no modelo Y = 0 + 1X1 + 2X pXp + *X* + O teste essencialmente compara 2 modelos: o completo e o reduzido O objetivo é determinar qual modelo é mais apropriado, baseado na informação adicional que X* fornece para Y, além da já fornecida por X1, X2,...,Xp
 H0: X* NÃO melhora significativamente a predição de Y, dados X1, X2,...,Xp existentes no modelo H0: * = 0 no modelo Y = 0 + 1X1 + 2X pXp + *X* + O teste essencialmente compara 2 modelos: o completo e o reduzido. O objetivo é determinar qual modelo é mais apropriado, baseado na informação adicional que X* fornece para Y, além da já fornecida por X1, X2,...,Xp.")
40
- = O procedimento do teste
Para realizar o teste F parcial, deve-se computar a soma dos quadrados extra pela adiçao de X*, que aparece na tabela ANOVA como SSR X*| X1, X2,...,Xp Ou mais compactadamente: Como SSY = SSR + SSE, podemos também fazer: reduzido completo Soma dos quadrados Extra pela inclusão de X*, dados X1, X2,...,Xp Soma dos quadrados da Regressão pela inclusão de X*, dados X1, X2,...,Xp Soma dos quadrados da Regressão dados X1, X2,...,Xp - = SS (X*| X1, X2,...,Xp) = SS Regressão (X1, X2,...,Xp, X*) - SS Regressão (X1, X2,...,Xp) SS (X*| X1, X2,...,Xp) = SS Resíduo (X1, X2,...,Xp) - SS Resíduo (X1, X2,...,Xp, X*)
 = SS Regressão (X1, X2,...,Xp, X*) - SS Regressão (X1, X2,...,Xp) SS (X*| X1, X2,...,Xp) = SS Resíduo (X1, X2,...,Xp) - SS Resíduo (X1, X2,...,Xp, X*)")
41
Comparação de 2 modelos: completo e o reduzido
Modelo completo: Y = 0 + 1X1 + 2X pXp + *X* + Modelo reduzido: Y = 0 + 1X1 + 2X pXp + H0: * = 0 n-k-1

42
Comparação de 2 modelos: completo e o reduzido H0: * = 0
SS(X2|X1) = SSR(X1,X2) - SSR (X1) = = SS(X3|X1, X2) = SSR(X1,X2, X3) - SSR (X1, X2) = 693, = 0.24 SSE(completo) = Fcrítico=F1,n-p-2,1- = F1,9,0.95 = não rejeita H0 F1,9,0.90 = 3.36 rejeita H0 a um nível de 0.10
 = SSR(X1,X2) - SSR (X1) = = SS(X3|X1, X2) = SSR(X1,X2, X3) - SSR (X1, X2) = 693, = SSE(completo) = Fcrítico=F1,n-p-2,1- = F1,9,0.95 = 5.12 não rejeita H0. F1,9,0.90 = 3.36 rejeita H0 a um nível de")
43
(IDADE)2, ALTURA X IDADE, (ALTURA)2
3. Teste F parcial múltiplo Testa a contribuição adicional de um conjunto de variáveis independentes na predição de Y. Testa a inclusão simultânea de 2 ou mais variáveis. Por exemplo, variáveis que tenham características em comum, e que seja importante testá-las em conjunto, como as variáveis de ordem superior a 1: (IDADE)2, ALTURA X IDADE, (ALTURA)2 Ou variáveis de termo de ordem superior, que correspondam ao produto de variáveis de 1a. ordem, como os termos de interação X1X2, X1,X3, X2X3. Muitas vezes é de interesse conhecer o efeito das interações em conjunto, antes de considerar cada termo individualmente. Este procedimento pode reduzir o trabalho de testes individuais, uma vez que variáveis podem ser retiradas do modelo em conjunto.
2, ALTURA X IDADE, (ALTURA)2. Ou variáveis de termo de ordem superior, que correspondam ao produto de variáveis de 1a. ordem, como os termos de interação X1X2, X1,X3, X2X3. Muitas vezes é de interesse conhecer o efeito das interações em conjunto, antes de considerar cada termo individualmente. Este procedimento pode reduzir o trabalho de testes individuais, uma vez que variáveis podem ser retiradas do modelo em conjunto.")
44
Hipótese nula Modelo completo: Y = 0 + 1X1 + 2X pXp + *1X*1 + *2X* *kX*k + Modelo reduzido: Y = 0 + 1X1 + 2X pXp + H0: "X*1 , X*2 , ..., X*k NÃO melhoram significativamente a predição de Y.” H0: *1 = *2 = ... = *k = 0

45
SS Regressão (X1, X2, ..., Xp, X*1, X*2, ..., X*k) -
O procedimento Necessitamos calcular a soma dos quadrados EXTRA devida à inclusão dos X*i do modelo completo. SS(X*1, X*2, ..., X*k|X1, X2, ..., Xp) = SS Regressão (X1, X2, ..., Xp, X*1, X*2, ..., X*k) - SS Regressão (X1, X2, ..., Xp) = SS Resíduo (X1, X2, ..., Xp) SS Resíduo (X1, X2, ..., Xp, X*1, X*2, ..., X*k) p k parâmetros
 = SS Regressão (X1, X2, ..., Xp, X*1, X*2, ..., X*k) - SS Regressão (X1, X2, ..., Xp) = SS Resíduo (X1, X2, ..., Xp) - SS Resíduo (X1, X2, ..., Xp, X*1, X*2, ..., X*k) p k parâmetros.")
46
A estatística F:

47
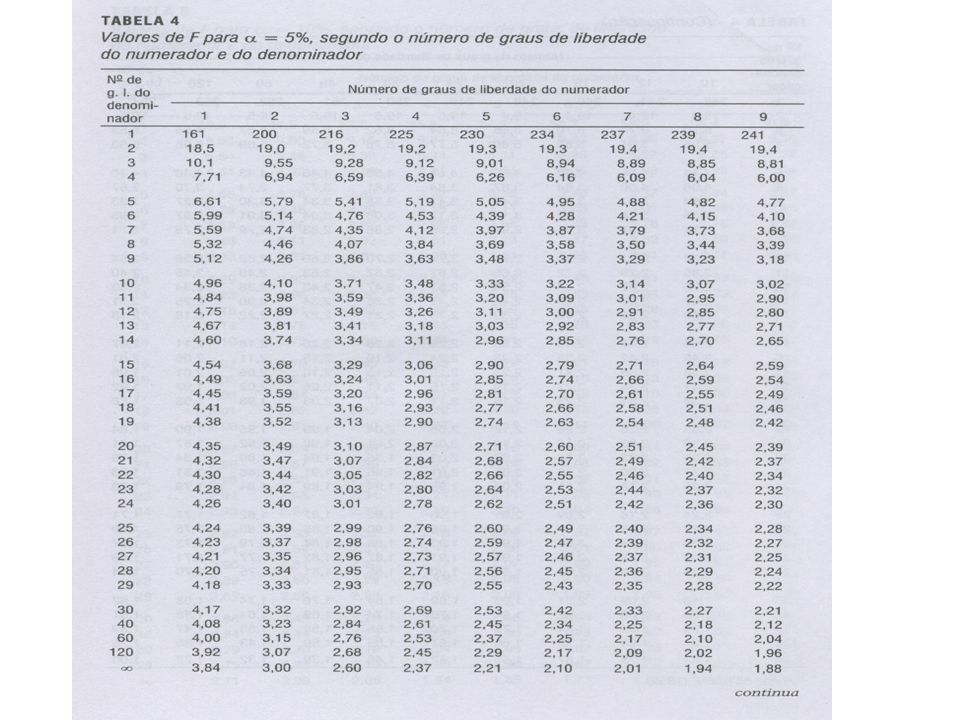
Fcrítico= Fk,(n-p-k-1),1- = F2,12-1-2-1),0.95 = F2,8,0.90 = 4.46
A estatística F: Exemplo: Inclusão de idade no modelo que já tem ALTURA IDADE e IDADE2. Fcrítico= Fk,(n-p-k-1),1- = F2, ),0.95 = F2,8,0.90 = 4.46 F calculado menor que o Fcrítico não rejeita H0
,1- = F2, ),0.95 = F2,8,0.90 = F calculado menor que o Fcrítico não rejeita H0.")
48
Para testar se rPESO,(IDADE)2|ALTURA, IDADE = 0,
Testando a significância estatística do coeficiente parcial teste F parcial H0: rYX|Z1,...,Zp = 0 Exemplo: Para testar se rPESO,(IDADE)2|ALTURA, IDADE = 0, encontra-se F[(IDADE)2|ALTURA, IDADE] e compara-se com F1,12-2-2,0.90 = F1,8,0.90=3.46 MSE = SSE(X3|X1,X2)/df = /(11-2-1) = /8=24.399 F calculado < F crítico --> NÃO rejeita H0 --> (IDADE)2 não contribui para a predição de PESO.
2|ALTURA, IDADE = 0, encontra-se F[(IDADE)2|ALTURA, IDADE] e. compara-se com F1,12-2-2,0.90 = F1,8,0.90=3.46. MSE = SSE(X3|X1,X2)/df = /(11-2-1) = /8= F calculado < F crítico --> NÃO rejeita H0 --> (IDADE)2 não contribui para a predição de PESO.")
49
Modelo A: PESO = 0 + 1 ALTURA +
Modelo B: PESO = 0 + 1 ALTURA + 2IDADE +

Apresentações semelhantes