Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Estimação Não-Paramétrica
EE-240/2009 Estimação Não-Paramétrica

2
Estimação Paramétrica
Assumir uma certa distribuição (normal, exponencial, Weibull, etc.) Estimar os parâmetros da distribuição a partir das observações Utilizar a distribuição com os parâmetros estimados.
 Estimar os parâmetros da distribuição a partir das observações. Utilizar a distribuição com os parâmetros estimados.")
3
Densidade Normal

4
30 observações

5
OK Função densidade de probabilidade estimada
(assumindo distribuição normal)
")
6
Uma Densidade Bimodal

7
30 observações

8
No Good! Função densidade de probabilidade estimada
(assumindo distribuição normal)
")
9
Métodos não-paramétricos
Nãoassumir um tipo específico de distribuição a priori Estimar a densidade de probabilidade a partir das observações Utilizar a densidade de probabilidade estimada.

10
Exemplo: Histograma (1)
")
11
30 observações

12
Divisão do intervalo em 10 trechos

13
Normalizar

14
Ajustar

15
Divisão do intervalo em 5 trechos

16
Divisão do intervalo em 20 trechos

17
60 observações

18
120 observações

19
240 observações

20
480 observações

21
960 observações

22
1920 observações

23
Divisão do intervalo em 10 trechos
30 observações

24
Divisão do intervalo em 20 trechos

25
3840 observações

26
“Kernel density estimation”:
K(x) = Função kernel de “área unitária” h = Parâmetro de alargamento (suavização)
 = Função kernel de área unitária h = Parâmetro de alargamento (suavização)")
27
h=1 h=1 Kernel Retangular, h=1

28
h=1 Kernel Retangular, h=1

29
h=1 Kernel Retangular, h=1

30
h=1 Kernel Retangular, h=1

31
h=1 Kernel Retangular, h=1

32
h=1 Kernel Retangular, h=1

33
h=1 Kernel Retangular, h=1

34
h=1 Kernel Retangular, h=1

35
h=1 Kernel Retangular, h=1

36
h=1 Kernel Retangular, h=1

37
h=1 Kernel Retangular, h=1

38
h=2 Kernel Retangular, h=2

39
Kernel Retangular, h=2

40
Kernel Retangular, h=2

41
Kernel Retangular, h=2

42
Kernel Retangular, h=2

43
Kernel Retangular, h=2

44
Kernel Retangular, h=2

45
Kernel Retangular, h=2

46
Kernel Retangular, h=2

47
Kernel Retangular, h=2

48
Kernel Retangular, h=2

49
Kernel Triangular, h=1

50
Kernel Triangular, h=1

51
Kernel Triangular, h=1

52
Kernel Triangular, h=1

53
Kernel Triangular, h=1

54
Kernel Triangular, h=1

55
Kernel Triangular, h=1

56
Kernel Triangular, h=1

57
Kernel Triangular, h=1

58
Kernel Triangular, h=1

59
Kernel Gaussiano, h=1

60
Kernel Gaussiano, h=1

61
Kernel Gaussiano, h=1

62
Kernel Gaussiano, h=1

63
Kernel Gaussiano, h=1

64
Kernel Gaussiano, h=1

65
Kernel Gaussiano, h=1

66
Kernel Gaussiano, h=1

67
Kernel Gaussiano, h=1

68
Kernel Gaussiano, h=1

69
Kernel Gaussiano, h=1

70
Kernel Gaussiano, h=1

71
Kernel Triangular, h=1

72
Kernel Gaussiano, h=1

73
Kernel Gaussiano, h=1

74
Kernel Gaussiano, h=1

75
Kernel Gaussiano, h=1

76
[F,XI]=KSDENSITY(X) computes a probability density estimate of the sample in the vector X. KSDENSITY evaluates the density estimate at 100 points covering the range of the data. F is the vector of density values and XI is the set of 100 points. The estimate is based on a normal kernel function, using a window parameter (bandwidth) that is a function of thenumber of points in X. F=KSDENSITY(X,XI) specifies the vector XI of values where the density estimate is to be evaluated. (Matlab Statistics Toolbox)
![[F,XI]=KSDENSITY(X) computes a probability density estimate of the sample in the vector X. KSDENSITY evaluates the density estimate at 100 points covering the range of the data. F is the vector of density values and XI is the set of 100 points. The estimate is based on a normal kernel function, using a window parameter (bandwidth) that is a function of thenumber of points in X.](http://slideplayer.com.br/slide/344568/2/images/76/%5BF%2CXI%5D%3DKSDENSITY%28X%29+computes+a+probability+density+estimate+of+the+sample+in+the+vector+X.+KSDENSITY+evaluates+the+density+estimate+at+100+points+covering+the+range+of+the+data.+F+is+the+vector+of+density+values+and+XI+is+the+set+of+100+points.+The+estimate+is+based+on+a+normal+kernel+function%2C+using+a+window+parameter+%28bandwidth%29+that+is+a+function+of+thenumber+of+points+in+X..jpg "F=KSDENSITY(X,XI) specifies the vector XI of values where the density estimate is to be evaluated. (Matlab Statistics Toolbox)")
77
Vantagens Métodos paramétricos:
Propriedades teóricas bem-estabelecidas. Métodos não-paramétricos: Dispensam a escolha a priori de um tipo de distribuição. Aplicabilidade mais ampla. Simplicidade de uso.

78
Desvantagens Métodos paramétricos: Métodos não-paramétricos:
Podem levar a resultados inadequados se a população não seguir a distribuição assumida na análise. Métodos não-paramétricos: Requerem um número maior de amostras para atingir a mesma “qualidade” de ajuste. Maior dificuldade para o estabelecimento de propriedades teóricas.

79
Bootstrap

80
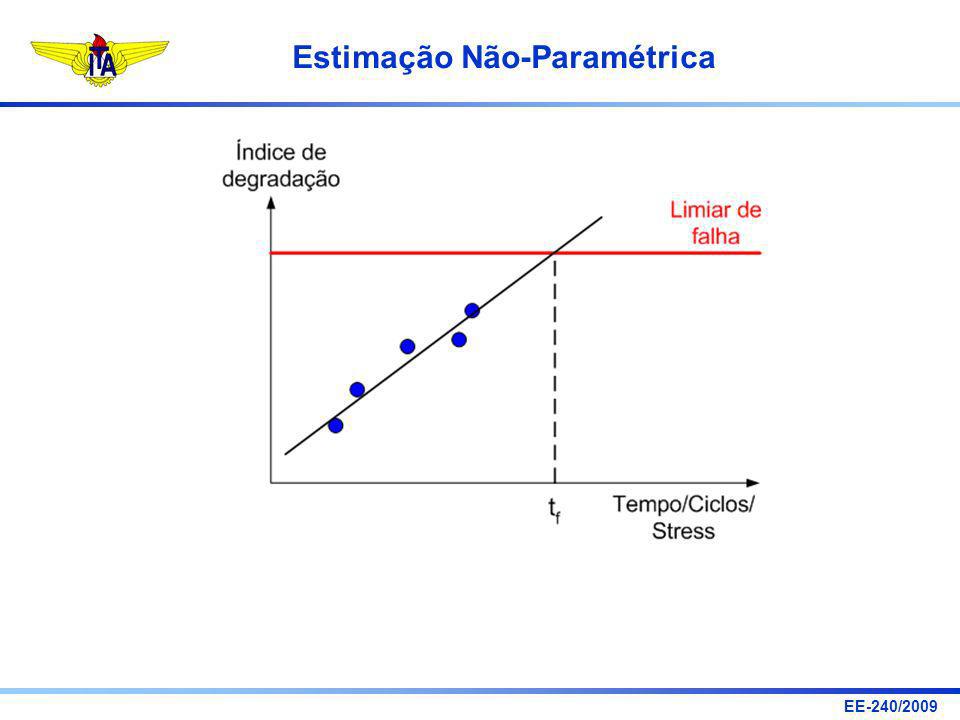
Motivação: Em muitos casos, pode não ser trivial obter o intervalo de confiança para uma dada estimativa. Exemplo (prognóstico baseado em análise de tendência): Previsão da Remaining Useful Life com base na série histórica de um índice de degradação.
: Previsão da Remaining Useful Life com base na série histórica de um índice de degradação.")
82
Pode não ser possível obter o intervalo de confiança de forma analítica se os dados não se conformarem às hipóteses usuais (ruído gaussiano, homoscedástico, etc.)
")
83
Bootstrap: Técnica de reamostragem (com reposição) que pode ser empregada para obter informações sobre a incerteza associada a uma estimativa.
 que pode ser empregada para obter informações sobre a incerteza associada a uma estimativa.")
84
Amostragem com reposição
Reamostragem Conjunto original Bootstrap

85
Reamostragem Conjunto original Bootstrap

86
Reamostragem Conjunto original Bootstrap

87
Reamostragem Conjunto original Bootstrap

88
Reamostragem Conjunto original Bootstrap

89
Reamostragem Conjunto original Bootstrap

90
Reamostragem Conjunto original Bootstrap

91
Bootstrap 1 Conjunto original Bootstrap 2 Reamostragens Bootstrap 3

92
Uso de Bootstrap em estimação
Considere que uma variável y tenha sido estimada a partir de n observações de uma variável x: Sejam X1, X2, ..., XN bootstraps gerados a partir de X. Seja ainda: Pode-se então levantar estatísticas com base nas N estimativas resultantes.

93
Exemplo 1: Estimativa da Mediana
Amostra de 10 observações gerada a partir de uma distribuição uniforme no intervalo [0, 10] (números inteiros): X = { 10, 2, 6, 5, 9, 8, 5, 0, 8 }. Cálculo da mediana: Xordenado = { 0, 2, 5, 5, 6, 8, 8, 9, 10 }
: X = { 10, 2, 6, 5, 9, 8, 5, 0, 8 }. Cálculo da mediana: Xordenado = { 0, 2, 5, 5, 6, 8, 8, 9, 10 }")
94
Estimativas obtidas (em ordem crescente):
Intervalo de confiança para a estimativa (70% de confiança 5-6):
:")
95
Exemplo 2 Estimativa de Mediana
Amostra de 30 observações gerada a partir de uma distribuição uniforme no intervalo [0, 10]:

96
Exemplo 2 Estimativa de Mediana
Amostra de 30 observações gerada a partir de uma distribuição uniforme no intervalo [0, 10]: Em 69 dos 100 bootstraps, a mediana obtida estava no intervalo [4, 6]. Intervalo [4, 6] 69% de confiança.

97
Densidade de probabilidade para o resultado obtido por Bootstrap
Pode-se aplicar o método das janelas de Parzen aos resultados obtidos a partir dos bootstraps. Neste caso, o resultado de cada bootstrap é considerado uma “observação” da grandeza a ser estimada.

98
Exemplo anterior com kernel gaussiano

99
Bootstrap e análise de tendência

100
d d t t d d t t

101
BOOTSTRP Bootstrap statistics.
BOOTSTRP(NBOOT,BOOTFUN,...) draws NBOOT bootstrap data samples and analyzes them using the function, BOOTFUN. NBOOT must be a positive integer. The third and later arguments are the data; BOOTSTRP passes bootstrap samples of the data to BOOTFUN. (Matlab Statistics Toolbox)
 draws NBOOT bootstrap data samples and analyzes them using the function, BOOTFUN. NBOOT must be a positive integer. The third and later arguments are the data; BOOTSTRP passes bootstrap samples of the data to BOOTFUN. (Matlab Statistics Toolbox)")
102
Muito Obrigado!

Apresentações semelhantes




 de variáveis aleatórias X1, X2, ..., Xn, cuja distribuição conjunta é desconhecida, inferir propriedades desta distribuição.>")








 MPEP – Mestrado Profissional em Produção Prof. Armando Z. Milioni.>")





