Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Capítulo 7 Conhecendo os Dados

2
Técnicas para extrair informações e gerar conhecimento de conjuntos de dados

3
Conhecendo os Dados O objetivo da análise exploratória de dados é examinar a estrutura subjacente dos dados e aprender sobre os relacionamentos sistemáticos entre muitas variáveis. A análise exploratória de dados inclui um conjunto de ferramentas gráficas e descritivas, para explorar os dados, como pré-requisito para uma análise de dados mais formal (Predição e Testes de Hipóteses), e como parte integral formal da construção de modelos.
, e como parte integral formal da construção de modelos..")
4
A AEA facilita a descoberta de conhecimentos não esperados, como também ajuda a confirmar o esperado. Como uma importante etapa em Data Mining, a AED emprega técnicas estatísticas descritivas e gráficas para estudar um conjunto de dados, detectando outliers e anomalias, e testando as suposições do modelo. A AED é um importante pré-requisito para se alcançar o sucesso em qualquer projeto de data mining.

5
Distribuições de Freqüências
organização dos dados de acordo com as ocorrências dos diferentes resultados observados. Pode ser apresentada: em tabela ou em gráfico; com freqüências absolutas, relativas ou porcentagens.

6
Exemplo (com variável qualitativa)
Códigos: nenhum grau de instrução compl e to, 2 - primeiro grau completo e 3 - segundo grau co m pleto. Resultados observados em cada fam í lia:

7
Distribuição de Freqüências
Grau de instrução (Conj. Resid. Monte Verde). Grau de In s tru ção Fr e qüên cia Percent a gem n e nhum 6 15,0 pr i meiro grau 11 27,5 segu n do grau 23 57,5 Total 40 100,0
. Grau de In. s. tru. ção. Fr. e. qüên. cia. Percent. a. gem. n. e. nhum ,0. pr. i. meiro grau ,5. segu. n. do grau ,5. Total ,0.")
8
Gráfico de Barras Grau de Instrução do Chefe da Casa segundo grau
4 8 12 16 20 24 segundo grau primeiro grau nenhum número de famílias

9
Gráfico de Barras Grau de Instrução do Chefe da Casa segundo grau
primeiro grau nenhum 4 8 12 16 20 24 número de famílias

10
Gráfico em colunas

11
Gráfico de Setores (Proporções)
Grau de Instrução do Chefe da Casa nenhum (15,0 %) segundo grau (57,5 %) primeiro grau (27,5 %)
 segundo grau. (57,5 %) primeiro grau. (27,5 %)")
12
Gráfico de Setores Multivariado

13
Gráfico de Barras Multivariado

14
Exemplo (com variável discreta)
Numa rede de computadores, a quantidade de máquinas que costumam estar ligadas, por dia

15
Distribuição de Freqüências
Máquinas em uso 20 21 22 23 24 25 26 Total Freqüência (absoluta) 2 4 6 5 1 20 Proporção (%) 0,10 (10%) 0,20 (20%) 0,30 (30%) 0,25 (25%) 0,00 (0,0%) 0,05 ( 5%) 1,00 (100%)
 Proporção (%) 0,10 (10%) 0,20 (20%) 0,30 (30%) 0,25 (25%) 0,00 (0,0%) 0,05 ( 5%) 1,00 (100%)")
16
Gráfico de colunas

17
Exemplo (com variável contínua)
Tempo (em segundos) para carga de um aplicativo num sistema compartilhado (50 observações): 5,2 6,4 5,7 8,3 7,0 5,4 4,8 9,1 5,5 6,2 4, ,7 6,3 5,1 8,4 6,2 8,9 7,3 5, ,8 5,6 6,8 5,0 6,7 8,2 7,1 4, ,0 8,2 9,9 5,4 5,6 5,7 6,2 4, ,1 6,0 4,7 18,1 5,3 4,9 5,0 5,7 6, ,0 6,8 7,3 6,9 6,5 5,9
 para carga de um aplicativo num sistema compartilhado (50 observações): 5,2 6,4 5,7 8,3 7,0 5,4 4,8 9,1. 5,5 6,2 4,9 5,7 6,3 5,1 8,4 6,2. 8,9 7,3 5,4 4,8 5,6 6,8 5,0 6,7. 8,2 7,1 4,9 5,0 8,2 9,9 5,4 5,6. 5,7 6,2 4,9 5,1 6,0 4,7 18,1 5,3. 4,9 5,0 5,7 6,3 6,0 6,8 7,3 6,9. 6,5 5,9.")
18
DADOS: 5,2 6,4 5,7 8,3 7,0 5,4 4,8 9,1 5,5 6,2 4, ,7 6,3 5,1 8,4 6,2 8,9 7,3 5, ,8 5,6 6,8 5,0 6,7 8,2 7,1 4, ,0 8,2 9,9 5,4 5,6 5,7 6,2 4, ,1 6,0 4,7 18,1 5,3 4,9 5,0 5,7 6, ,0 6,8 7,3 6,9 6,5 5,9 4,7 18,1 4 5 6 7 ... 19

19
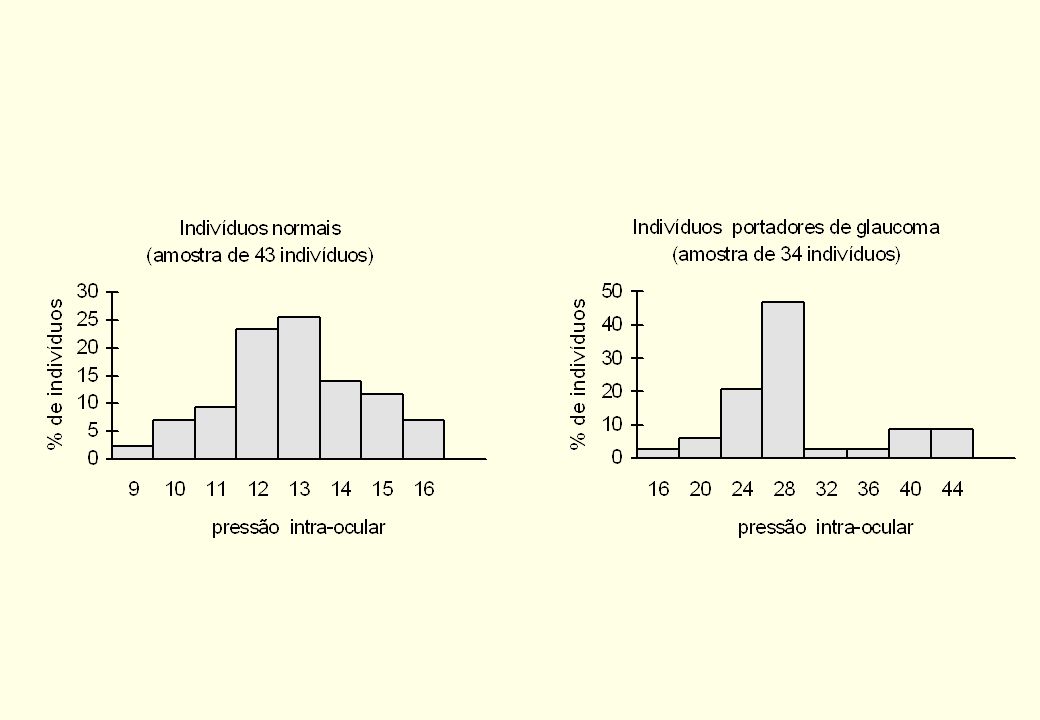
Histograma do tempo (em segundos) para carga de um aplicativo num sistema compartilhado (50 observações).
 para carga de um aplicativo num sistema compartilhado (50 observações).")
21
Conjunto de dados: são 92 observações relativas à preços de automóveis.

22
Verificar a variabilidade
outliers OUTLIERS: OU

23
Conjunto de dados: preços de fechamento de ações da telebrás

24
Série temporal

25
Medidas Descritivas Existem medidas quantitativas que servem para descrever, resumidamente, características das distribuições. As mais utilizadas são a média e o desvio padrão.

26
Média (X) A média aritmética simples ( X ) é a soma dos valores dividida pelo número de observações. X = X n

27
Exemplo Deseja-se estudar o número de falhas no envio de mensagens, considerando três algoritmos diferentes para o envio dos pacotes: Algoritmo A (8 observações) Algoritmo B (8 observações) Algoritmo C (7 observações)
 Algoritmo B (8 observações) Algoritmo C (7 observações)")
28
Exemplo Número de falhas a cada 10.000 mensagens enviadas.
B: C:

29
Comparação dos três algoritmos pela média
falhas média A 22 B 22 C 22

30
Diagramas de Pontos A B C 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
A B C Número de falhas Algoritmo

31
Média Geométrica A média geométrica é apropriada para médias de taxas ou números índices. Por exemplo: 1) estimar a taxa média de retorno após três anos de investimento, sendo 10% no primeiro, 50% no segundo e 30% no terceiro ano;
 estimar a taxa média de retorno após três anos de investimento, sendo 10% no primeiro, 50% no segundo e 30% no terceiro ano;")
32
Exemplo Média de relações: Relação média entre capital e dívida é:

33
Exemplo Média de taxas de variação:
Um investidor aplicou em 2001, R$ 500,00. Após um ano o saldo é de R$ 550,00. Reaplicou esta quantia e, ao final de mais um ano, o montante era de R$ 590,00. Qual a taxa média de aumento?

34
Medidas Robustas de Locação
Média “Winsorized”: a média “winsorized” compensa a presença de valores extremos no cálculo da média, atribuindo a estes, o valor de um determinado percentil da distribuição. Por exemplo: estimando a média “winsorized” de 95%, os 2,5% dos valores menores corresponderão ao 2,5 percentil da distribuição, enquanto os 2,5% dos valores maiores receberão o valor do 97,5 percentil da distribuição. Média aparada (Trimmed): a média aparada é calculada excluindo-se uma dada percentagem dos valores mais baixos e mais altos e, então, fazer a média com os valores restantes. Por exemplo, excluindo os 2,5% dos valores inferiores e superiores e usando os dados remanescentes, temos a média aparada de 5%. A média aparada não é afetada por valores discrepantes (outliers) como a média aritmética. A média aparada é usada, por exemplo, em classificação em esportes para minimizar as classificações extremas, possivelmente causadas por julgamentos tendenciosos.
: a média aparada é calculada excluindo-se uma dada percentagem dos valores mais baixos e mais altos e, então, fazer a média com os valores restantes. Por exemplo, excluindo os 2,5% dos valores inferiores e superiores e usando os dados remanescentes, temos a média aparada de 5%. A média aparada não é afetada por valores discrepantes (outliers) como a média aritmética. A média aparada é usada, por exemplo, em classificação em esportes para minimizar as classificações extremas, possivelmente causadas por julgamentos tendenciosos.")
35
Exemplo Medidas da variável IDADE de funcionários de um empresa:
Média “winzored:” Média aparada:

36
Como medir a dispersão? Exemplo: A ( 20 21 21 22 22 23 23 24 )
distância (desvio) em relação à média
 em relação à média.")
37
Desvios Valores X 20 21 21 22 22 23 23 24 Média X 22 Desvios (X - X)

38
Desvios Desvios: Soma = 0

39
Desvios Quadráticos Soma Valores X 20 21 21 22 22 23 23 24 176 Média X
- Desvios X - X Desvios (X-X) 2 12 quadráticos
 quadráticos.")
40
Variância (S2) A variância (S2) é uma média dos desvios quadráticos. Por conveniência, usa-se (n-1) no denominador ao invés de n.
 no denominador ao invés de n.")
41
Exemplo No exemplo apresentado (algoritmo A), a variância é: 12 S2 =
7 12 = 1,71

42
Desvio Padrão (S) O desvio padrão (S) é a raiz quadrada da variância.
S = S2

43
Exemplo No exemplo apresentado (algoritmo A), o desvio padrão é:
, o desvio padrão é:")
44
Comparação dos três algoritmos pela média e desvio padrão
falhas X S A 22 1,31 B 22 4,00 C 22 3,16

45
Diagramas de pontos e valores de S
Algoritmo A (S = 1,31) Algoritmo B (S = 4,00) Algoritmo C (S = 3,16) Número de falhas
 Algoritmo B. (S = 4,00) Algoritmo C. (S = 3,16) Número de falhas.")
46
Medidas descritivas das notas finais dos alunos de três turmas
TABELA Medidas descritivas das notas finais dos alunos de três turmas Turma Número de Média Desvio alunos padrão A 20 6,0 3,3 B 40 8,0 1,5 C 30 9,0 2,6

47
Medida relativa de dispersão
Coeficiente de variação: desvio padrão média

48
Medida relativa de dispersão - - Exemplo
média = 2 desvio padrão = 1 coeficiente de variação = 0,5 média = 101 coeficiente de variação = 0,01 média = 200 desvio padrão = 100

49
Medidas baseadas na ordenação dos dados Quartil inferior mediana
25% Q I Quartil inferior M d mediana Q S Quartil superior

50
Cálculo da mediana Dados: {2, 0, 5, 7, 9, 1, 3, 4, 6, 8} n = 10; (n + 1) / 2 = 5,5 Md = 4,5

51
0 1 2 3 4 5 6 7 8 9 Cálculo dos quartis Md = 4,5 Qi = 2 Qs = 7 Ei = 0
Md = 4,5 Qi = 2 Qs = 7 Ei = 0 Es = 9

52
Exercício: Cálculo da mediana Dados: {2, 0, 5, 7, 9, 1, 3, 4, 6, 8, 100} n = 11; (n + 1) / 2 = 6 Md = 5

53
0 1 2 3 4 5 6 7 8 9 100 Exercício: Cálculo dos quartis Qi = 2,5
Qi = 2,5 Qs = 7,5 Ei = 0 Md = 5 Es = 100

54
Distância interquartílica
Medida de dispersão: Distância interquartílica O desvio inter-quartílico é uma medida robusta de dispersão. Ele é calculado por: Onde Q3 é o percentil 75, também chamado de quartil superior, e o Q1 é o percentil 25, também chamado de quartil inferior. Ele é uma boa medida de dispersão para distribuições assimétricas. Para dados normalmente distribuídos, o desvio inter-quartílico é aproximadamente igual a 1,35 vezes o desvio padrão. Medidas da variável IDADE de funcionários de um empresa, setor tecidos:

55
Distribuição da variável IDADE de funcionários de um empresa,seção: tecidos:

56
Média e mediana 50% dos valores 50% dos valores X 10 20 30 40 50 60 70
10 20 30 40 50 60 70 M = 22,5 X d = 24,7

57
Média e mediana

58
Diagrama em caixas (Box Plot)
25% 25% 25% 25% 25% 25% 25% 25% Ÿ

59
Diagrama em caixas 28 Renda 23 familiar 18 (sal. mín.) 13 8 3 Monte
Encosta outlier Verde do Morro

60
Cálculo dos outliers: Onde QI é o quartil inferior ou primeiro quartil da distribuição; QS é o quartil superior ou terceiro quartil da distribuição. O valor 1,5 pode ser alterado.

61
Gráfico Normal de Probabilidade (Normal Probability Plot)
Verificar assimetria (assimétrico à direita) Normalidade da distribuição Presença de outliers Se há falta de ajuste, e os dados apresentar um padrão (forma de S), então a variável deve ser transformada (log).
 Normalidade da distribuição. Presença de outliers. Se há falta de ajuste, e os dados apresentar um padrão (forma de S), então a variável deve ser transformada (log).")
62
zj = F-1 [(3*j-1)/(3*N+1)] Gráfico Normal de Probabilidades:
Os valores de zj para o j-ésimo valor (rank, posto) de uma variável com N observações, é calculado por: zj = F-1 [(3*j-1)/(3*N+1)] Onde -1 converte os valores de probabilidade, p, em valores de z. Exemplo: para o arquivo de dados de automóveis, onde N=92 observações.
![zj = F-1 [(3*j-1)/(3*N+1)] Gráfico Normal de Probabilidades:](http://slideplayer.com.br/slide/349048/2/images/62/zj+%3D+F-1+%5B%283%2Aj-1%29%2F%283%2AN%2B1%29%5D+Gr%C3%A1fico+Normal+de+Probabilidades%3A.jpg "Os valores de zj para o j-ésimo valor (rank, posto) de uma variável com N observações, é calculado por: zj = F-1 [(3*j-1)/(3*N+1)] Onde -1 converte os valores de probabilidade, p, em valores de z. Exemplo: para o arquivo de dados de automóveis, onde N=92 observações.")
63
Erro Padrão e Intervalos de Confiança
Erro padrão: erro padrão é o desvio padrão da distribuição amostral de uma dada estatística. Erro padrão mostra a quantidade de flutuação amostral que existe nas estatísticas estimadas em repetidas amostragens. O erro padrão de uma estatística depende do tamanho da amostra. Em geral, quanto maior o tamanho da amostra, menor é o erro padrão. Intervalo de confiança: o intervalo de confiança fornece uma faixa(amplitude) de valores, dentro da qual esperamos que o valor de um parâmetro desconhecido esteja incluído. Se amostras independentes são tomadas repetidamente de uma mesma população, e o intervalo de confiança é calculado para cada amostra, então, uma alta percentagem dos intervalos irão incluir o parâmetro desconhecido. A amplitude do intervalo fornece uma idéia sobre a incerteza da estimativa do parâmetro. Um intervalo com grande amplitude indica que mais dados devem ser coletados antes de se fazer inferências sobre o parâmetro.
 de valores, dentro da qual esperamos que o valor de um parâmetro desconhecido esteja incluído. Se amostras independentes são tomadas repetidamente de uma mesma população, e o intervalo de confiança é calculado para cada amostra, então, uma alta percentagem dos intervalos irão incluir o parâmetro desconhecido. A amplitude do intervalo fornece uma idéia sobre a incerteza da estimativa do parâmetro. Um intervalo com grande amplitude indica que mais dados devem ser coletados antes de se fazer inferências sobre o parâmetro.")
64
Erro padrão e intervalo de confiança para uma média
Erro padrão e intervalo de confiança de 95% da variável IDADE de funcionários de um empresa, setor tecidos: t=2,015368

65
Transformações Vários procedimentos estatísticos e as redes neurais, são baseados na suposição de que os dados provêm de uma distribuição normal ou, então, mais ou menos simétrica (redes neurais funcionam melhor para distribuições simétricas). Porém, em muitas situações práticas, a distribuição dos dados da amostra é assimétrica e pode conter valores discrepantes. Pode-se realizar uma transformação nos dados, de forma a se obter uma distribuição mais simétrica. Uma família de transformação freqüentemente utilizada é:
. Porém, em muitas situações práticas, a distribuição dos dados da amostra é assimétrica e pode conter valores discrepantes. Pode-se realizar uma transformação nos dados, de forma a se obter uma distribuição mais simétrica. Uma família de transformação freqüentemente utilizada é:")
66
Na prática, o que se faz é experimentar uma série de valores p, na seqüência:
..., -3,-2,-1,-1/2,-1/3,-1/4,0,1/4,1/3,1/2,1,2,3,... e para cada valor de p obtemos gráficos apropriados (histogramas, box plot, etc.) para os dados originais e transformados, de modo a escolhermos o valor mais adequado de p. Para distribuições assimétricas à direita, a transformação acima com 0<p<1 é apropriada, pois valores grandes de x decrescem mais, relativamente a valores pequenos. Para distribuições assimétricas à esquerda, tome p>1.
 para os dados originais e transformados, de modo a escolhermos o valor mais adequado de p. Para distribuições assimétricas à direita, a transformação acima com 0<p<1 é apropriada, pois valores grandes de x decrescem mais, relativamente a valores pequenos. Para distribuições assimétricas à esquerda, tome p>1.")
67
Exemplo: consideremos os dados da variável idade dos funcionários de uma empresa, cujo histograma fica: Distribuição assimétrica à direita, tentar valores de p entre 0 e 1.

68
Vamos considerar os seguintes valores de p: 0 (transformação logarítmica), ¼, 1/3(transformação raíz cúbica), ½ (transformação raíz quadrada)
, ¼, 1/3(transformação raíz cúbica), ½ (transformação raíz quadrada)")
69
Análise de Associação Geralmente estamos interessados em analisar o comportamento conjunto de duas ou mais variáveis. Os dados aparecem em forma de matriz, onde nas colunas temos as variáveis (campos) e nas linhas as observações (registros).
 e nas linhas as observações (registros).")
70
Variáveis Qualitativas
Objetivo: analisar as relações entre as colunas (variáveis), ou algumas vezes entre linhas (observações). O estudo das distribuições conjuntas é um poderoso instrumento para o entendimento do comportamento dos dados. Estas relações ou associações podem ser detectadas por meio de representações gráficas e medidas numéricas. Variáveis Qualitativas Exemplo: desejamos analisar o comportamento conjunto das variáveis sexo do funcionário e setor em que trabalha. A distribuição de freqüência conjunta é apresentada na tabela a seguir.
, ou algumas vezes entre linhas (observações). O estudo das distribuições conjuntas é um poderoso instrumento para o entendimento do comportamento dos dados. Estas relações ou associações podem ser detectadas por meio de representações gráficas e medidas numéricas. Variáveis Qualitativas. Exemplo: desejamos analisar o comportamento conjunto das variáveis sexo do funcionário e setor em que trabalha. A distribuição de freqüência conjunta é apresentada na tabela a seguir.")
71
Existem três possibilidades de expressarmos as proporções das caselas:
em relação ao total geral em relação ao total de cada linha em relação ao total de cada coluna A escolha é feita de acordo com os Objetivos do trabalho

72
Interpretação (foi fixado o total de colunas em 100%): podemos dizer que, entre os funcionários do sexo feminino, 47,76% trabalham as seção de tecidos e 38,81% trabalham na seção de presentes, calçados e confecções e, apenas 1,49% trabalham na seção de tapetes e cristais. Entre os funcionários do sexo masculino, 39,39% trabalham na seção de tecidos e 30,30% trabalham na seção de lustres, ferramentas e brinquedos e, 18,18% trabalham na seção de presentes, calçados e confecções.

73
1=feminino 2= masculino Interpretação: parece que estas duas variáveis estão pouco associadas.

74
Medida de associação: Coeficiente de Contingência
Onde: nij= número de elementos observados pertencentes à i-ésima categoria de X e j-ésima categoria de Y; r = número de linhas e s = no. de colunas da tabela. nij*= número de elementos esperados pertencentes à i-ésima categoria de X e j-ésima categoria de Y. O valor de C está entre 0 e 1 (porém, para alcançar o valor 1 precisa de uma correção). O valor de 2 varia de 0 até o infinito.
. O valor de 2 varia de 0 até o infinito.")
75
Freqüências esperadas considerando as variáveis como sendo não associadas
Cálculo da freqüência esperada

76
Este valor apresenta uma grandeza considerável.
O valor de C deveria variar de 0 a 1. Porém isso não acontece. Para evitar este inconveniente, costuma-se fazer uma correção no valor de C, o qual fica: Onde t é o mínimo entre o r e o s

77
Variáveis Quantitativas
Interpretação: podemos considerar que as variáveis estão medianamente associadas. Variáveis Quantitativas Gráfico de dispersão: indicado para estudar a associação entre duas variáveis quantitativas. Exemplo: consideremos os dados da variável X:idade e Y: tempo de profissão do funcionário, do setor de tecidos. O gráfico de dispersão está na figura a seguir.

78
Vemos que, parece haver uma associação direta (positiva) entre idade e tempo de serviço. A medida que aumenta a idade, aumenta o tempo como balconista.

79
Medida de correlação: Coeficiente de Correlação
O coeficiente de correlação varia na faixa de: -1 r 1 Para o exemplo, o coeficiente de correlação vale: R=0,66 Portanto, as duas variáveis estão correlacionadas. Esta correlação é de grau mediano para forte. Cálculo no próximo slide.

81
Matriz de correlação

82
Variáveis Quantitativas e Qualitativas
Esta análise pode ser conduzida por meio de medidas descritivas (média, mediana, desvio padrão , desvio inter-quartílico), polígonos de freqüências múltiplo, box-plot. Exemplo: consideremos os dados da variável qualitativa:tipo de carro e a variável quantitativa Y: preço. A representação gráfica, através de box plot múltiplo está na figura a seguir.
, polígonos de freqüências múltiplo, box-plot. Exemplo: consideremos os dados da variável qualitativa:tipo de carro e a variável quantitativa Y: preço. A representação gráfica, através de box plot múltiplo está na figura a seguir.")
83
O gráfico sugere uma dependência entre tipo de carro e preço dos automóveis. Os preços aumentam do tamanho pequeno (small), após vem os compactos e esportivos e finalmente os grandes, as vans e médios.
, após vem os compactos e esportivos e finalmente os grandes, as vans e médios..")
84
Medida de associação: Coeficiente de determinação
Sem usar a informação da variável categorizada(tipo de carro), a variância calculada para a variável quantitativa para todos os dados mede a dispersão dos dados globalmente. Se a variância dentro de cada categoria for pequena e menor do que a global, significa que a variável qualitativa melhora a capacidade de previsão da quantitativa e, portanto, existe uma relação entre as duas variáveis.
, a variância calculada para a variável quantitativa para todos os dados mede a dispersão dos dados globalmente. Se a variância dentro de cada categoria for pequena e menor do que a global, significa que a variável qualitativa melhora a capacidade de previsão da quantitativa e, portanto, existe uma relação entre as duas variáveis.")
85
Observe na tabela que temos uma categoria (Midsize) com variância maior do que a global e cinco categorias com variância menor do que a global. Parece que a variável qualitativa (tipo de carro) melhora a capacidade preditiva da variável quantitativa (preço). Cálculo da variância entre as categorias da variável qualitativa Onde k é o número de categorias (no nosso exemplo k=6) e vari denota a variância dentro da categoria i, onde i=1,2,...,k.
 e vari denota a variância dentro da categoria i, onde i=1,2,...,k.")
86
No exemplo, temos: Podemos definir o grau de associação através do cálculo do coeficiente de determinação, dado por: O coeficiente de determinação varia na faixa de: 0 R2 1

87
Exemplo: o coeficiente de determinação para o exemplo vale:
Podemos dizer que 36,08% da variação dos preços dos automóveis é explicada pelo tipo de carro.

88
Exemplo: vamos considerar as variáveis: Eficiência no consumo (MPG), Origem e os Preços. Vamos separar os preços por eficiência e origem. Observamos que para eficiência alta, os preços são similares, tanto para carros domésticos como para estrangeiros. Para eficiência baixa e origem doméstica, têm-se os carros com os maiores preços (porcentagem baixa, apenas 2%).
.")
89
Diagrama de dispersão tridimensional

91
Existem diversos softwares especializados em visualização de dados no mercado, com enfâse em data mining, entre eles: MineSet InfoZoon

Apresentações semelhantes


















>")
>")
>")
