Carregar apresentação
A apresentação está carregando. Por favor, espere

1
CAP 5 BAUM – Specifying the functional form (especificando a forma funcional)
Henrique Dantas Neder – prof. Instituto de Economia da Universidade Federal de Uberlândia

2
Erro de especificação A consistência do estimador da regressão linear requer que a função de regressão da amostra corresponda a função de regressão subjacente ou o verdadeiro modelo de regressão para a variável de resposta (dependente) y:
 y:")
3
Erro de especificação (cont.)
A teoria econômica freqüentemente fornece um guia na especificação do modelo, mas pode ser que ela não indique explicitamente como uma variável específica entre no modelo ou identifique a forma funcional. O modelo deve ser estimado em níveis para as variáveis; ou em uma estrutura logaritmica; como um polinomio em um ou mais dos regressores? Em geral a teoria se cala frente a estes pontos especificos e temos que utilizar estratégias empiricas.

4
Omissão de variáveis relevantes do modelo (subespecificação)
Suponha que o verdadeiro modelo (população) é: com k1 e k2 regressores em dois subconjuntos, mas regredimos y somente sobre as variáveis x1 :
 é: com k1 e k2 regressores em dois subconjuntos, mas regredimos y somente sobre as variáveis x1 :")
5
Omissão de variáveis (cont.)
A solução de mínimos quadrados ordinários é: A menos que ou , a estimativa de é viesada, desde que: onde

6
Omissão de variáveis (cont.)
é uma matriz k1xk2 refletindo a regressão de cada coluna de nas colunas de Se k1=k2 e a variável única em é correlacionada com a variável única em , podemos prever a direção do viés. Mas se tivermos múltiplas variáveis em cada conjunto não podemos prever a natureza do viés dos coeficientes.

7
Omissão de variáveis (cont.)
* OMISSAO DE VARIAVEIS RELEVANTES NO MODELO matrix drop _all * Vamos considerar o arquivo gpa2 do Wooldridge como dados de uma população use "f:\Minhas Webs\DADOS\DADOS WOOLDRIDGE\gpa2.dta", clear *Vamos verificar o tamanho N da população e calcular os valores dos parâmetros Count regress colgpa hsperc sat hsize matrix bpop = e(b) matrix list bpop matrix betapop = e(b) matrix betapop = betapop' matrix list betapop matrix beta1pop = J(2,1,0) matrix beta1pop[2,1] = betapop[1,1] matrix beta1pop[1,1] = betapop[4,1]
 matrix list bpop. matrix betapop = e(b) matrix betapop = betapop matrix list betapop. matrix beta1pop = J(2,1,0) matrix beta1pop[2,1] = betapop[1,1] matrix beta1pop[1,1] = betapop[4,1]")
8
Omissão de variáveis (cont.)
matrix beta2pop[1,1] = betapop[2,1] matrix beta2pop[2,1] = betapop[3,1] predict residuo, residuals * vamos selecionar uma amostra aleatória de tamanho n = 50 sample 50, count regress colgpa hsperc sat hsize regress colgpa hsperc * vamos gerar o valor da estimativa viesada do parâmetro beta1 matrix b = e(b) matrix list b gen const = 1 mkmat residuo, matrix(u) mkmat const hsperc, matrix(X1) mkmat sat hsize, matrix(X2) mkmat colgpa, matrix(Y)
 matrix list b gen const = 1 mkmat residuo, matrix(u) mkmat const hsperc, matrix(X1) mkmat sat hsize, matrix(X2) mkmat colgpa, matrix(Y)")
9
Omissão de variáveis (cont.)
* Vamos calcular a estimativa do parâmetro beta1 nesta ultima regressão * (com omissão da variável sat) utilizando álgebra linear e empregando * a expressão da pagina 116 do Baum matrix betahat1 = inv(X1'*X1)*X1'*Y matrix list betahat1 matrix P1 = inv(X1'*X1)*X1' matrix P2 = inv(X1'*X1)*X1'*X2 matrix betahat2 = beta1pop + P2*beta2pop + P1*u matrix list betahat2
 utilizando álgebra linear e empregando. * a expressão da pagina 116 do Baum. matrix betahat1 = inv(X1 *X1)*X1 *Y. matrix list betahat1. matrix P1 = inv(X1 *X1)*X1 matrix P2 = inv(X1 *X1)*X1 *X2. matrix betahat2 = beta1pop + P2*beta2pop + P1*u. matrix list betahat2.")
11
Omissão de variáveis (cont.)
Wooldridge (2006) apresenta na pg 90 um quadro resumo para modelos de 2 variáveis: Corr(x1,x2 > 0) Corr(x1,x2)<0 β2>0 Viés positivo Viés negativo β2<0 Se a correlação entre X1 e X2 é nula na população, as estimativas de regressão são consistentes mas provavelmente serão viesadas em amostras finitas.
 apresenta na pg 90 um quadro resumo para modelos de 2 variáveis: Corr(x1,x2 > 0) Corr(x1,x2)<0. β2>0. Viés positivo. Viés negativo. β2<0. Se a correlação entre X1 e X2 é nula na população, as estimativas de regressão são consistentes mas provavelmente serão viesadas em amostras finitas.")
12
Omissão de variáveis (cont.)
Mais a frente será abordado um dos métodos para corrigir o viés devido a omissão de variáveis: em Baum, pg 216 é mostrado como o método das variáveis instrumentais pode solucionar o problema. Considere a relação entre a variável SAT (escores de testes de aptidão de estudantes), expend (gastos por aluno) e poverty (a proporção de pobres em cada distrito):
, expend (gastos por aluno) e poverty (a proporção de pobres em cada distrito):")
13
Omissão de variáveis (cont.)
Não podemos estimar esta equação porque não temos acesso a dados distritais sobre pobreza. Entretanto, este fator tem uma importante função no resultado educacional, sendo uma proxy da qualidade do ambiente familiar do estudante. Se temos uma proxy para pobreza, podemos incluí-la no modelo, como por exemplo, a renda mediana do distrito.

14
Omissão de variáveis (cont.)
O sucesso desta estratégia dependerá da força da correlação entre esta proxy e a pobreza que é uma variável não observável. Se não temos uma proxy disponível, podemos estimar a equação ignorando a pobreza: O termo (processo) de perturbação aleatória nesta equação é composto por
 de perturbação aleatória. nesta equação é composto por.")
15
Omissão de variáveis (cont.)
Se expend e poverty são correlacionadas – e provavelmente são – a regressão gerará estimativas viesadas e inconsistentes de e porque a hipótese de média condicional nula é violada. Para derivar estimativas consistentes na equação temos que encontrar uma variável instrumental, ou seja, uma variável que seja não correlacionada com os fatores não observáveis que afetam a variável dependente (inclusive a variável poverty) e altamente correlacionada com expend.
 e altamente correlacionada com expend.")
16
Omissão de variáveis (cont.)
Um possível instrumento para poverty seria a relação estudante-professor no distrito (stratio) já que ela deve ser negativamente correlacionada com expend. O método IV aqui poderia consistir em estimar um modelo em dois estágios:
 já que ela deve ser negativamente correlacionada com expend. O método IV aqui poderia consistir em estimar um modelo em dois estágios:")
17
Omissão de variáveis (cont.)
Primeiramente estimamos o valor da variável expend através da segunda equação do sistema anterior. Em seguida utilizamos o valor desta estimativa como um dos regressores na primeira equação (expendhat).
.")
18
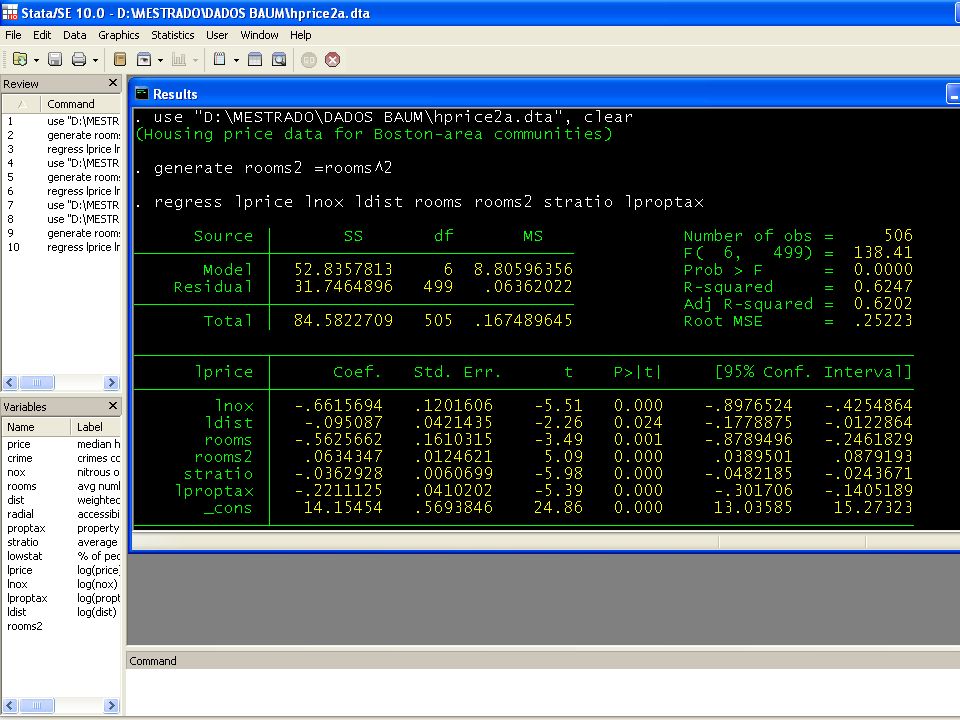
Gráficos de adição de variáveis
Tomando cada regressor por vez, o gráfico de adição de variáveis (“added-variable plot”) é baseado em duas séries de resíduos: A série c1 contem os resíduos da regressão de y contra todas as variáveis x exceto a variável xk que está sendo “testada”. A série c2 representa a informaçao (resíduo) de y que nao pode ser explicada por todos os outros regressores (exceto xk). O gráfico de adiçao de variáveis para xk é o diagrama de dispersao de c2 (no eixo dos y) versus c1 (no eixo dos x).
 é baseado em duas séries de resíduos: A série c1 contem os resíduos da regressão de y contra todas as variáveis x exceto a variável xk que está sendo testada . A série c2 representa a informaçao (resíduo) de y que nao pode ser explicada por todos os outros regressores (exceto xk). O gráfico de adiçao de variáveis para xk é o diagrama de dispersao de c2 (no eixo dos y) versus c1 (no eixo dos x).")
19
Gráficos de adição de variáveis
Dois casos opostos são de interesse: 1) Se a maioria dos pontos estao em torno de uma linha horizontal na ordenada zero, a variável xk é irrelevante. 2) Se a maioria dos pontos estao em volta de uma linha vertical com abscissa zero o gráfico está indicando quase perfeita multicolinearidade. Se a inclinaçao de uma eventual relaçao linear entre c1 e c2 é significativa, xk tem uma importante contribuição no modelo além dos outros regressores.
 Se a maioria dos pontos estao em torno de uma linha horizontal na ordenada zero, a variável xk é irrelevante. 2) Se a maioria dos pontos estao em volta de uma linha vertical com abscissa zero o gráfico está indicando quase perfeita multicolinearidade. Se a inclinaçao de uma eventual relaçao linear entre c1 e c2 é significativa, xk tem uma importante contribuição no modelo além dos outros regressores.")
23
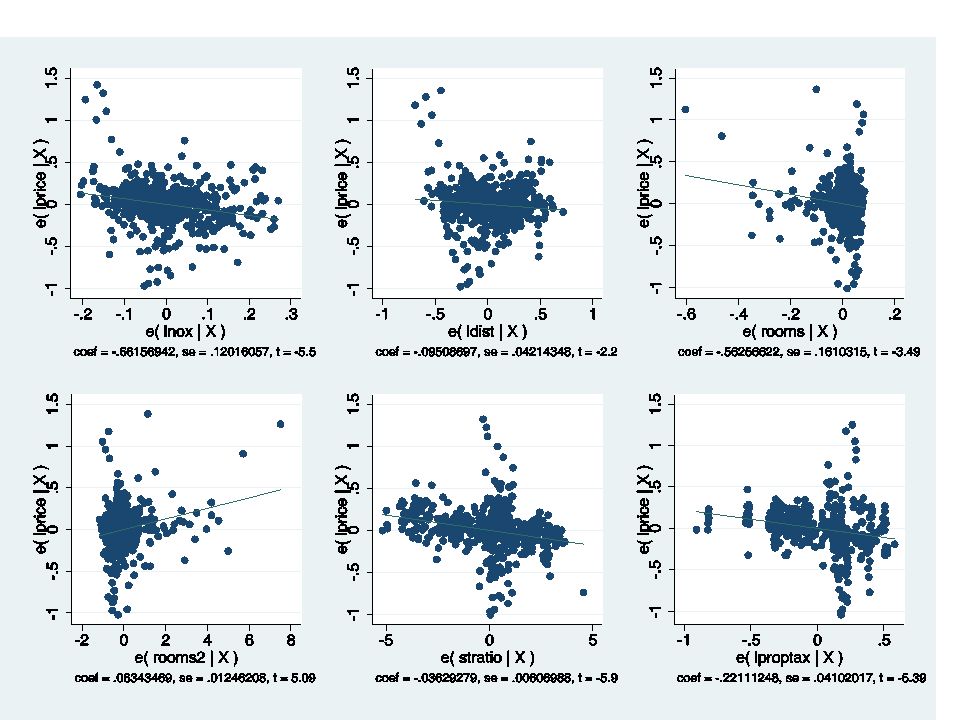
Gráficos de adição de variáveis
Temos diversos “outliers” (observaçoes que estão fora da linha), particularmante evidentes para os gráficos lnox e ldist. Baixos valores de E[lnox|X] e E[ldist|X] sao associados com preços mais elevados do que aqueles preditos pelo modelo. As estatisticas t testam a hipotese de que a linha de mínimos quadrados tem uma inclinaçao significativa (≠ 0). Estes testes sao identicos ao da regressao original.
, particularmante evidentes para os gráficos lnox e ldist. Baixos valores de E[lnox|X] e E[ldist|X] sao associados com preços mais elevados do que aqueles preditos pelo modelo. As estatisticas t testam a hipotese de que a linha de mínimos quadrados tem uma inclinaçao significativa (≠ 0). Estes testes sao identicos ao da regressao original.")
24
Incluindo variáveis irrelevantes no modelo (sobreespecificaçao)
Incluir variáveis irrelevantes no modelo na viola a hipótese de média condicional nula (pois seus coeficientes na população – parâmetros são nulos). Suponha que o verdadeiro modelo é: Mas incluímos erroneamente diversas variáveis x2 no nosso modelo de regressão.
. Suponha que o verdadeiro modelo é: Mas incluímos erroneamente diversas variáveis x2 no nosso modelo de regressão.")
25
Incluindo variáveis irrelevantes no modelo (sobre-especificação)
Incluir variáveis irrelevantes no modelo não afeta o não viés das variáveis relevantes incluídas no modelo. Wooldridge(2006) lembra que para qualquer valor de , incluindo Então concluímos que para qualquer valor de No entanto, isto terá indesejáveis efeitos na variância dos estimadores, como será visto mais tarde.
 lembra que para qualquer valor de , incluindo . Então concluímos que. para qualquer valor de . No entanto, isto terá indesejáveis efeitos na variância dos estimadores, como será visto mais tarde.")
26
Incluindo variáveis irrelevantes no modelo (sobre-especificação)
Baum (pg 121) analisando estimadores os efeitos da sobre- especificação nas propriedades dos OLS da regressão afirma que: Incluir variáveis irrelevantes mantém as propriedades de não viés e consistência dos estimadores de No entanto os estimadores terão variância mais elevada (menos precisos) do que se o modelo fosse corretamente especificado. Claramente, sobre-especificar custa mais do que sub- especificar o modelo e o modelo sobre-especificado gera estimativas não viesadas e consistentes para todos os seus parâmetros, inclusive os dos regressores irrelevantes, que tendem a zero.
 analisando estimadores os efeitos da sobre- especificação nas propriedades dos OLS da regressão afirma que: Incluir variáveis irrelevantes mantém as propriedades de não viés e consistência dos estimadores de . No entanto os estimadores terão variância mais elevada (menos precisos) do que se o modelo fosse corretamente especificado. Claramente, sobre-especificar custa mais do que sub- especificar o modelo e o modelo sobre-especificado gera estimativas não viesadas e consistentes para todos os seus parâmetros, inclusive os dos regressores irrelevantes, que tendem a zero.")
27
A assimetria do erro de especificação
Os custos do dois tipos de erro de especificação são assimétricos. Disto se conclui que uma estratégia melhor é iniciar com uma especificação geral (mesmo que sobre-especificada) e impor ao modelo restrições apropriadas. Muitas investigações empíricas contem muita busca por especificação (nesta estratégia do geral para o particular).
 e impor ao modelo restrições apropriadas. Muitas investigações empíricas contem muita busca por especificação (nesta estratégia do geral para o particular).")
28
A assimetria do erro de especificação
Limites da inferência estatística: podemos rodar 20 regressões a partir de 20 amostras aleatórias simples selecionadas de uma mesma população onde determinado regressor não existe no modelo verdadeiro, mas ao nível de significância de 5 % podemos esperar que uma destas 20 regressões amostrais mostre erroneamente uma relação entre a variável dependente e este regressor sobre-especificado .

29
Sub-especificação da forma funcional
O modelo pode não refletir a relação algébrica correta entre a variável dependente e os regressores. Por exemplo, o verdadeiro modelo da população tem uma forma funcional quadrática e o estimamos na amostra como uma relação linear, omitindo o termo do regressor elevado ao quadrado:

30
Sub-especificação da forma funcional
Em um sentido este problema é mais simples de lidar do que o problema de omissão de variáveis: na sub-especificação da forma funcional temos todas as variáveis consideradas e temos somente que escolher a forma apropriada em que elas entram na equação de regressão.

31
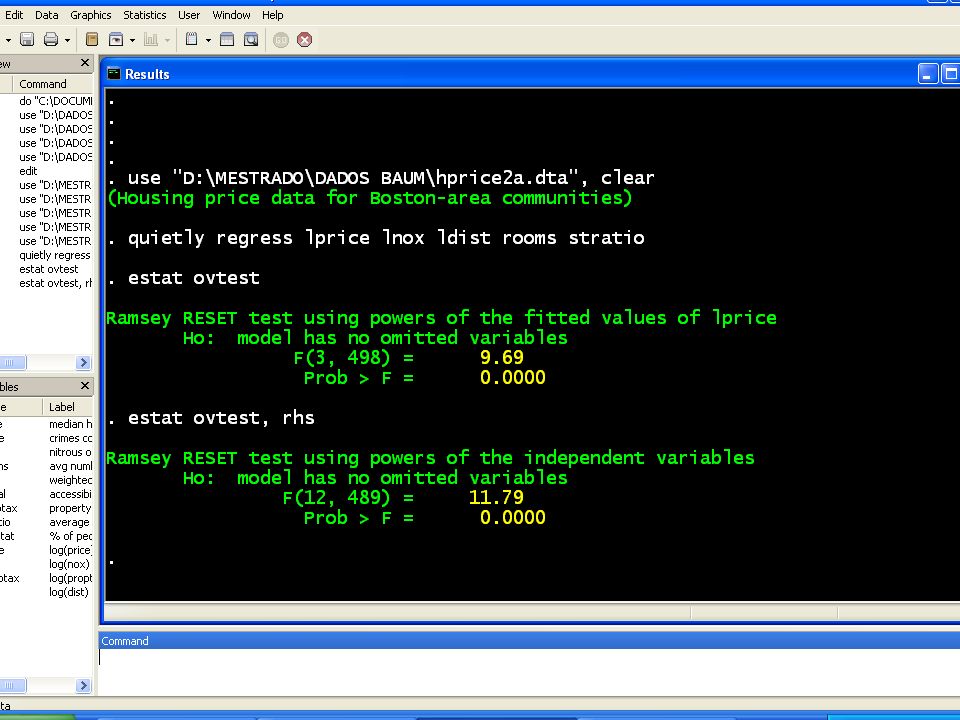
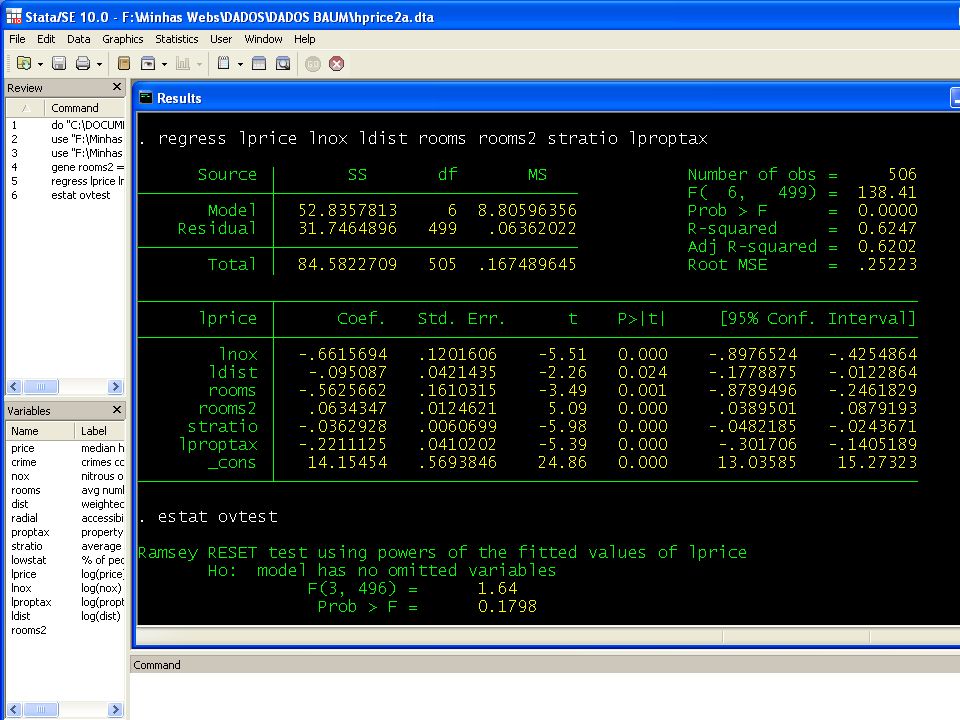
O teste RESET de Ramsey O teste RESET (regression specification error test) executa uma regressão aumentada que inclui os regressores originais, potencias dos valores preditos da regressão original e potencias dos regressores originais. H0: os coeficientes dos regressores adicionais = 0 O teste é simplesmente um teste Wald. Ele baseia-se na idéia de que polinômios em podem aproximar uma variedade de relações funcionais entre y e os regressores x.
 executa uma regressão aumentada que inclui os regressores originais, potencias dos valores preditos da regressão original e potencias dos regressores originais. H0: os coeficientes dos regressores adicionais = 0. O teste é simplesmente um teste Wald. Ele baseia-se na idéia de que polinômios em. podem aproximar uma variedade de relações funcionais entre y e os regressores x.")
34
Gráfico para verificação da especificação
comando rvpplot ou menu Statistics => Linear models and related => Regression Diagnostics => Residual-versus-predictor plot O gráfico mostra que a hipótese de homocedasticidade é violada

35
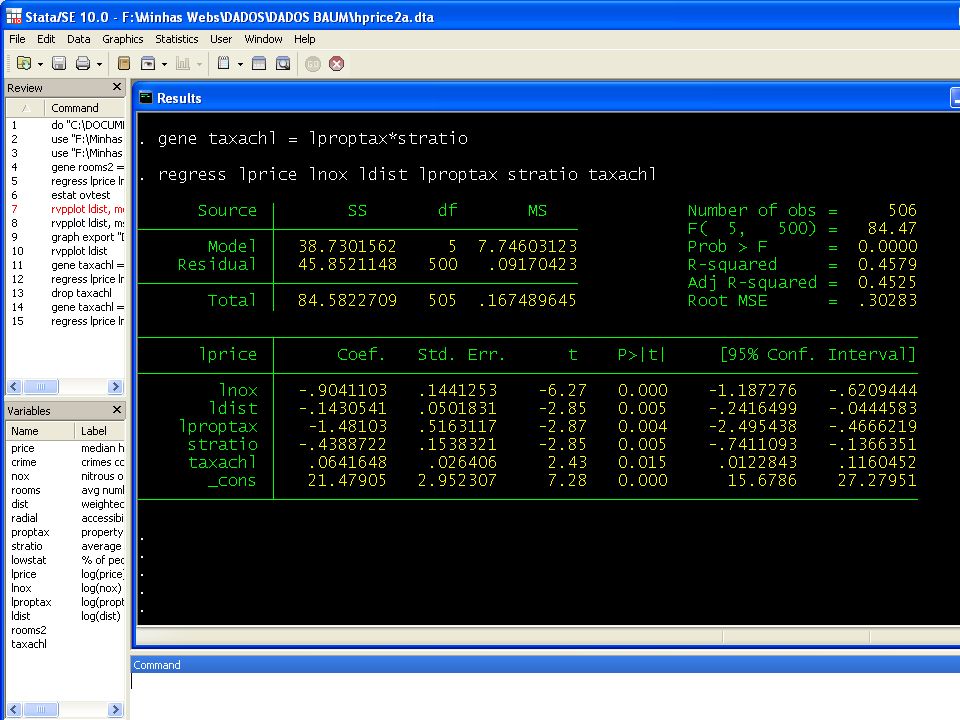
Erro de especificação – termos de interação
Podemos considerar que no verdadeiro modelo da população é uma função de , de forma que o modelo deve ser especificado como: O efeito de xj depende de xl

37
Erro de especificação – termos de interação
Neste ultimo modelo estamos incluindo uma variável – taxachl – que é a interação entre lproptax – o logaritmo da média dos impostos de propriedades da comunidade e stratio – a relação estudante-professor no nosso modelo de determinação de preços de casas. Como o coeficiente do termo de interação é negativo, interpreta-se que a derivada parcial negativa de lprice com relação a lproptax (stratio) torna-se menos negativa (aproxima-se de zero) para maiores níveis de stratio (lproptax).
 torna-se menos negativa (aproxima-se de zero) para maiores níveis de stratio (lproptax).")
Apresentações semelhantes