Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Probit ordenado

2
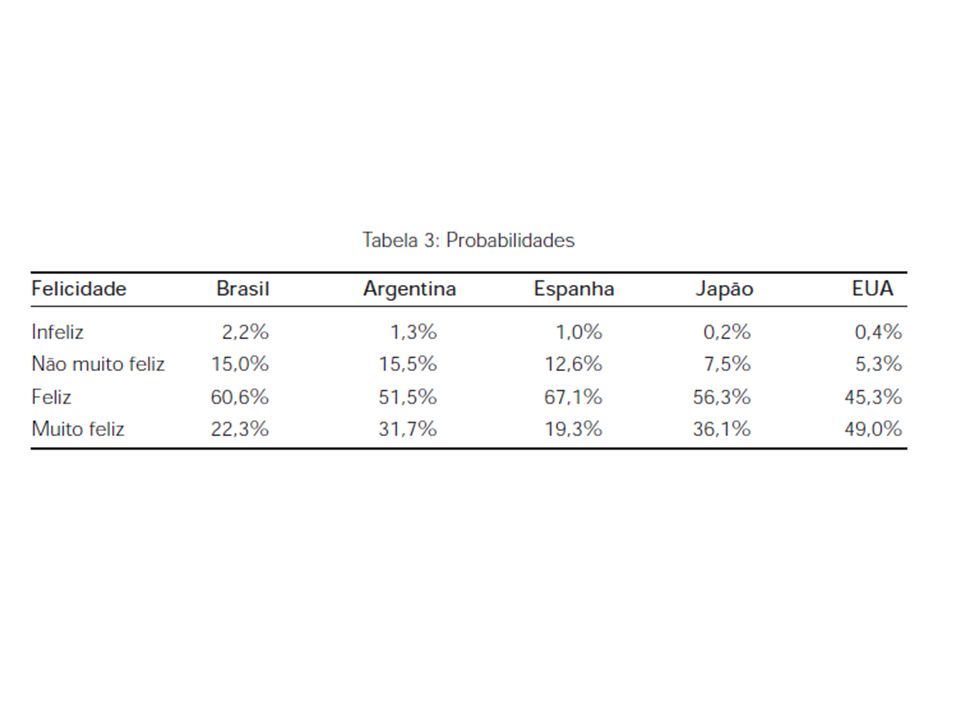
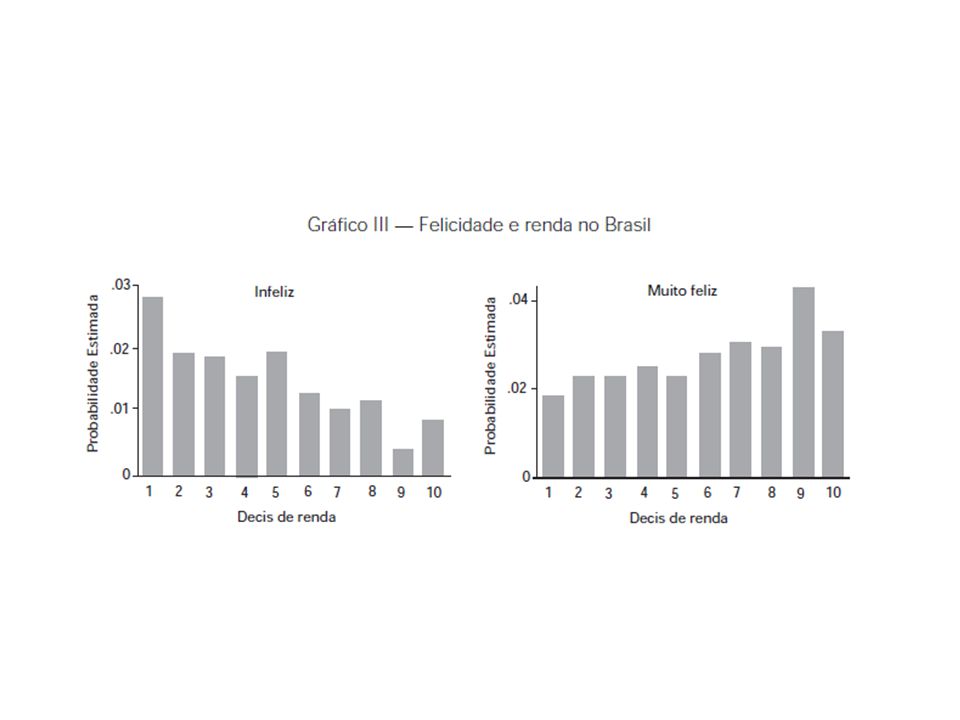
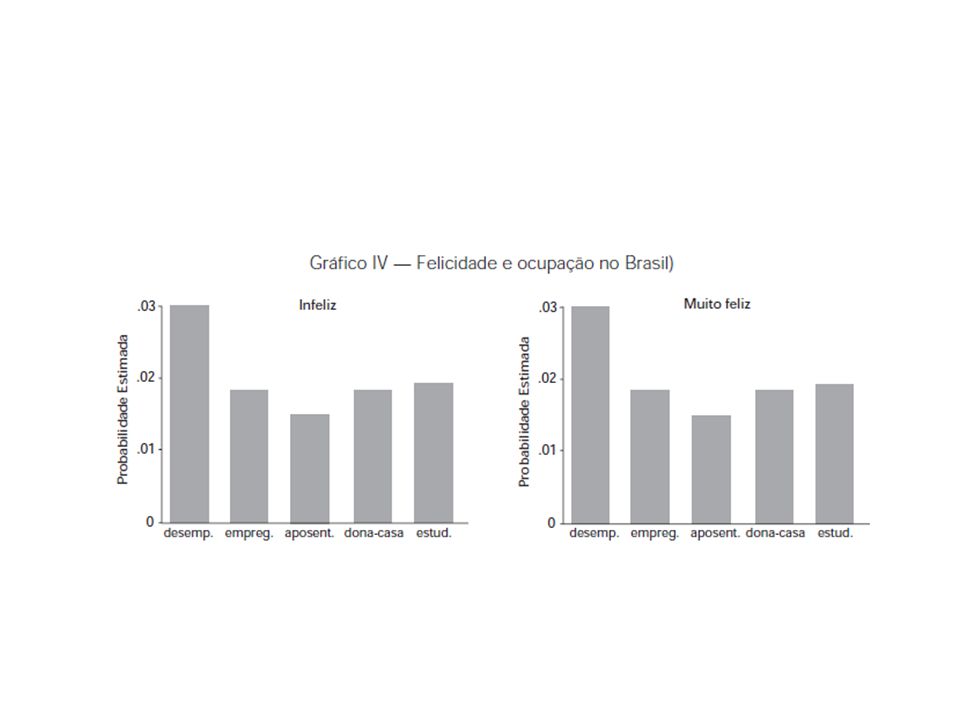
Alguns exemplos Artigo: Corbi e Menezes-Filho (2006). Os determinantes empíricos da felicidade no Brasil. REP, vol. 26, n. 4, out-dez. Investigar os determinantes empíricos da felicidade no Brasil através de uma base de dados ainda pouco utilizada no país, o World Values Survey (Pesquisa Mundial de Valores). Analisar a associação de algumas variáveis sócioeconômicas, tais como renda, desemprego, educação, sexo, estado civil e idade, com a felicidade dos indivíduos. A renda e o desemprego serão examinados de forma a compreendermos de que maneira eles podem influir no nível de felicidade dos indivíduos.
. Analisar a associação de algumas variáveis sócioeconômicas, tais como renda, desemprego, educação, sexo, estado civil e idade, com a felicidade dos indivíduos. A renda e o desemprego serão examinados de forma a compreendermos de que maneira eles podem influir no nível de felicidade dos indivíduos.")
3
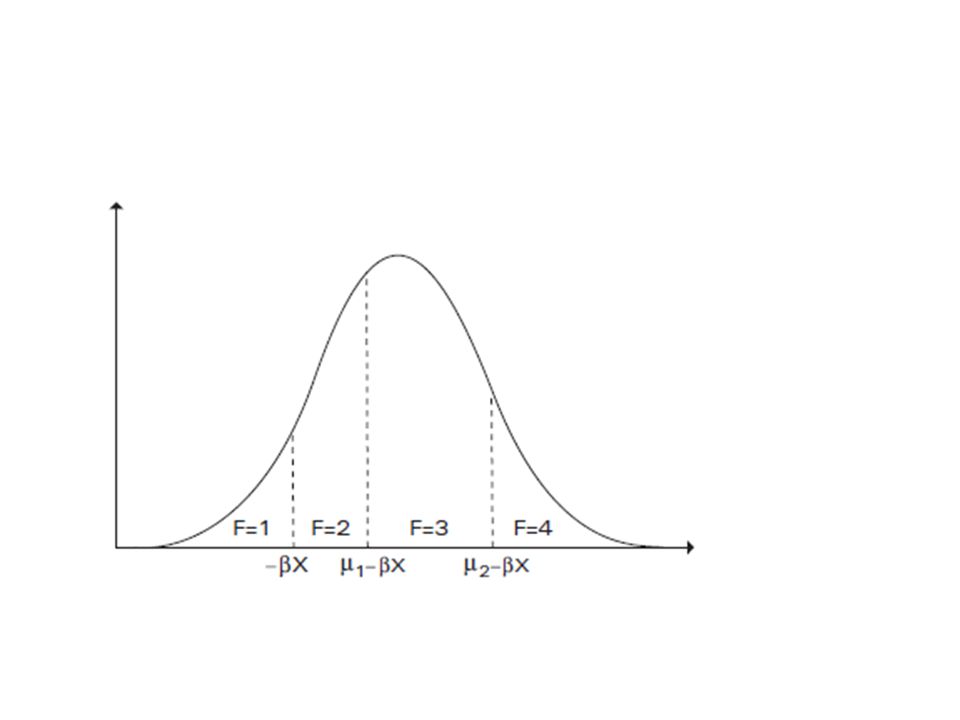
Medida de Felicidade O modelo de probit ordenado é um modelo multinomial, e sua variável dependente assume valores que estabelecem um certo ordenamento dos dados, não de forma linear, mas sim de forma a ranquear os possíveis resultados. A variável latente F associa números às respostas individuais, da seguinte forma: 1 para “infeliz”, 2 para não “muito feliz”, 3 para “feliz” e 4 para “muito feliz”.

9
Multinomial: exemplo

10
Banco de dados Várias marcas de um produto estão no mercado.
Iremos explicar as escolhas dos consumidores por estas marcas considerando as seguintes variáveis explicativas: sexo (female) e idade (age). Por exemplo, há um estudo que afirma que as mulheres escolhem mais cameras digitas Kodak e que homens preferem Canon.
 e idade (age). Por exemplo, há um estudo que afirma que as mulheres escolhem mais cameras digitas Kodak e que homens preferem Canon.")
12
mlogit brand female age, base(1)
Iteration 0: log likelihood = Iteration 1: log likelihood = Iteration 2: log likelihood = Iteration 3: log likelihood = Iteration 4: log likelihood = Multinomial logistic regression Number of obs = LR chi2(4) = Prob > chi2 = Log likelihood = Pseudo R = brand | Coef. Std. Err z P>|z| [95% Conf. Interval] | female | age | _cons | | female | age | _cons | (brand==1 is the base outcome) git brand female age, base(1)
 = Prob > chi2 = Log likelihood = Pseudo R2 = brand | Coef. Std. Err. z P>|z| [95% Conf. Interval] | female | age | _cons | | female | age | _cons | (brand==1 is the base outcome) git brand female age, base(1)")
13
Alguns resultados Para a mudança de uma unidade da variável idade, o log da razão entre as duas probabilidades, P(brand=2)/P(brand=1), irá aumentar em e o log da razão das duas probabilidades P(brand=3)/P(brand=1) irá aumentar em Podemos dizer que, em geral, as pessoas mais velhas irão preferir brand 2 ou 3.
/P(brand=1), irá aumentar em e o log da razão das duas probabilidades P(brand=3)/P(brand=1) irá aumentar em Podemos dizer que, em geral, as pessoas mais velhas irão preferir brand 2 ou 3.")
14
A razão entre a probabilidade de escolher uma categoria e a probabilidade de escolher a categoria de referência é denominada de risco relativo (odds). Os resultados podem ser interpretados em termos de risco relativo. Podemos dizer que para mudança de uma unidade da idade, esperamos que o risco relativo de escolher brand 2 ao invés de brand 1 aumente de exp(.3682) = O risco relativo é maior para pessoas mais velhas. Para a variável female, a razão do risco relativo de escolher brand 2 ao invés de 1 para mulheres e homens é exp(.5238) = 1.69. Rrr no mlogit dá o risco relativo no Stata. (mlogit, rrr)
 = O risco relativo é maior para pessoas mais velhas. Para a variável female, a razão do risco relativo de escolher brand 2 ao invés de 1 para mulheres e homens é exp(.5238) = Rrr no mlogit dá o risco relativo no Stata. (mlogit, rrr)")
15
line p1 age if female ==0 || line p1 age if female==1, legend(order(1 "male" 2 "female"))
)")
Apresentações semelhantes
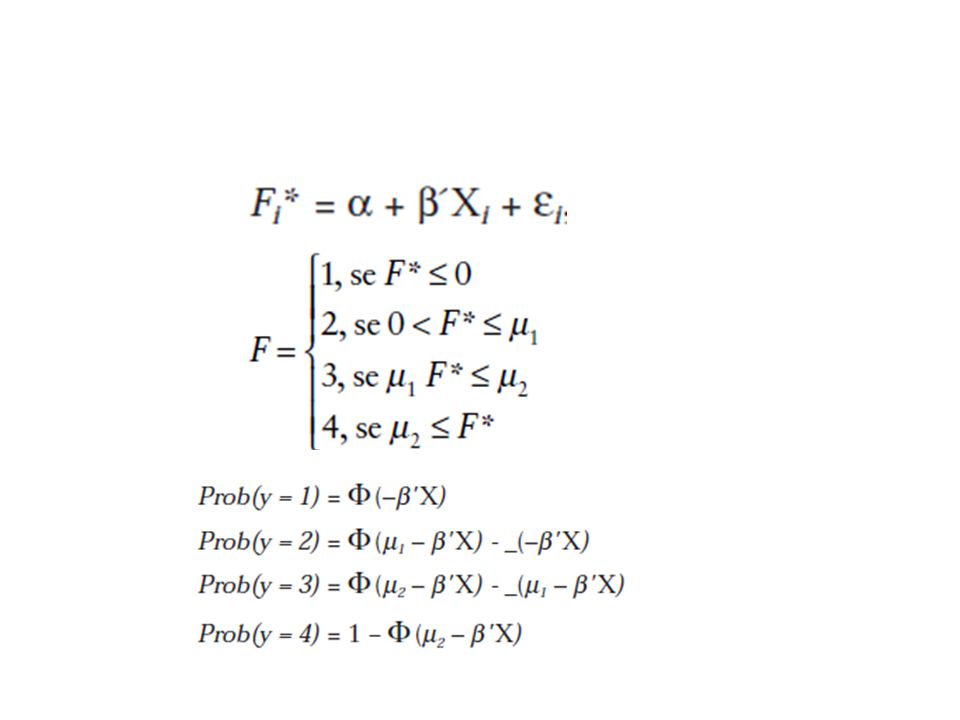















>")
>")
>")


