Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Amostragem em Pesquisas Sócio-Econômicas
Henrique Dantas Neder Prof. Universidade Federal de Uberlândia Introdução Termos e Definições de Amostragem Métodos de Seleção de Amostras Amostragem aleatória ou probabilística Amostragem por quotas Amostragem Sistemática

2
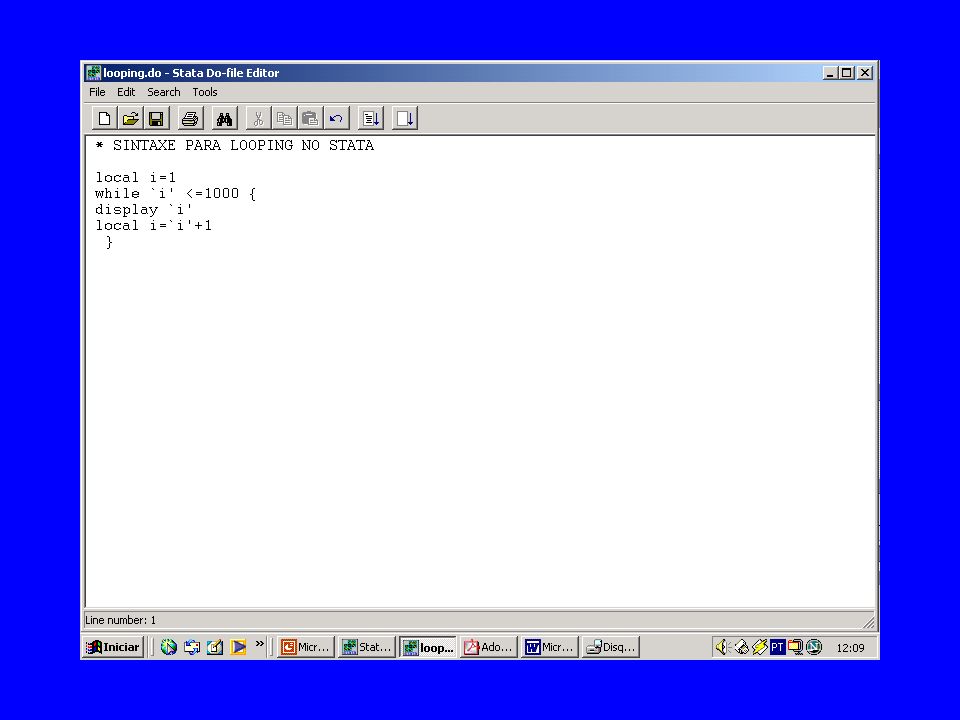
AMOSTRAGEM SISTEMÁTICA
1a. Calcula-se o tamanho do intervalo sistemático. Este é igual a: onde Int uma função que aplicada ao argumento produz o maior inteiro menor do que este argumento. Por exemplo, se N = 1000 e n = 90 . 2a. Escolhe-se um número aleatório entre 1 e I, no caso do exemplo entre 1 e 11. Digamos que seja escolhido o número 9. 3a. Os elementos escolhidos na população para entrar na amostra são: primeiro número aleatório = A; A + I; A +2I; A + 3I; .... No caso do exemplo: O que dá a seguinte seqüência: 9o.; 20o. ; 31o. ;42o.;.....

3
A escolha do número aleatório pode ser feita empregando-se uma tabela de números aleatórios. Mas um procedimento mais fácil é utilizar no Excel a função ALEATORIOENTRE (escreva em qualquer célula da planilha a fórmula =ALEATORIOENTRE(1,11). Quando apertar a tecla entre o programa retorna um número aleatório dentro do intervalo fechado [1,11]
. Quando apertar a tecla entre o programa retorna um número aleatório dentro do intervalo fechado [1,11].")
4
Desenhos de Amostras Amostragem Aleatória Simples Se tivermos, por exemplo, uma população de tamanho N = 100 e selecionarmos n = 10, teremos amostras distintas de 10 elementos em uma população de tamanho 100 Utilizar a função ALEATORIOENTRE do Excel para selecionar a amostra, desde que todos os elementos da população estejam rotulados com números na seqüência 1 a N. Se tivermos n = 10 e N = 100 devemos ativar 10 vezes a função =ALEATORIOENTRE(1,100).
.")
5
Amostragem com probabilidade desigual
1000 70 130750 Empresa Número de empregados Número de empregados acumulado Intervalo 1 100 1-100 2 200 300 3 50 350 4 500 850 ... 999 130680

6
Amostra Aleatória Estratificada
Subdivide-se a população em K estratos e seleciona-se aleatoriamente alguns elementos amostrais de cada estrato populacional Amostragem por Conglomerados Subdivide-se a população em conglomerados e seleciona-se aleatoriamente um conjunto de conglomerados. O conglomerado é chamado de unidade de amostragem primária (UPA). Dentro de cada UPA (conglomerado) selecionada todos os indivíduos são incluídos na amostra. Exemplo: as escolas da rede municipal de ensino são os conglomerados e os alunos são as unidades de amostragem secundária (USA).
. Dentro de cada UPA (conglomerado) selecionada todos os indivíduos são incluídos na amostra. Exemplo: as escolas da rede municipal de ensino são os conglomerados e os alunos são as unidades de amostragem secundária (USA).")
7
Amostragem por Conglomerados em Múltiplos Estágios
Seleciona-se aleatoriamente os conglomerados (UPAs) e dentro de cada UPA selecionado seleciona-se aleatoriamente as USAs.Os UPAs podem ser selecionados com probabilidade proporcional ao tamanho (PPT) Exemplo: Na PNAD (Pesquisa Nacional por Amostra Domiciliar) são selecionados primeiramente os municípios (UPAs) com Probabilidade proporcional ao tamanho (número de domicílios). Posteriormente, em cada município selecionado, seleciona-se os Setores censitários (USAs) e finalmente, dentro de cada USA selecionada, são escolhidos aleatoriamete os domicílios.
 e dentro de cada UPA selecionado seleciona-se aleatoriamente as USAs.Os UPAs podem ser selecionados com probabilidade proporcional ao tamanho (PPT) Exemplo: Na PNAD (Pesquisa Nacional por Amostra Domiciliar) são selecionados primeiramente os municípios (UPAs) com Probabilidade proporcional ao tamanho (número de domicílios). Posteriormente, em cada município selecionado, seleciona-se os Setores censitários (USAs) e finalmente, dentro de cada USA selecionada, são escolhidos aleatoriamete os domicílios.")
8
Figura 1 – Ilustração Do Teorema Do Limite Central Para Uma Distribuição log-normal

9
Quadro 1 – Simulação de uma amostragem com reposição
de uma população hipotética de 5 elementos

10
Quadro 4 – Principais Estimadores utilizados em amostragem
Parâmetro Representação do parâmetro Estimador Representação do estimador Variância do estimador Média populacional Média amostral Total populacional Total amostral expandido Proporção populacional Proporção amostral Total de indivíduos na população com determinada característica

11
Tabela 4 – Tamanho amostral para uma Amostra Aleatória
Simples (AAS) com objetivo de estimar para um dado desvio-padrão da população e (população infinita)
 com objetivo de estimar para um dado. desvio-padrão da população e (população infinita)")
12
Tabela 5 – Tamanho amostral para uma Amostra Aleatória
Simples com objetivo de estimar uma proporção populacional p para diversos valores de , p e erro (população infinita)
")
16
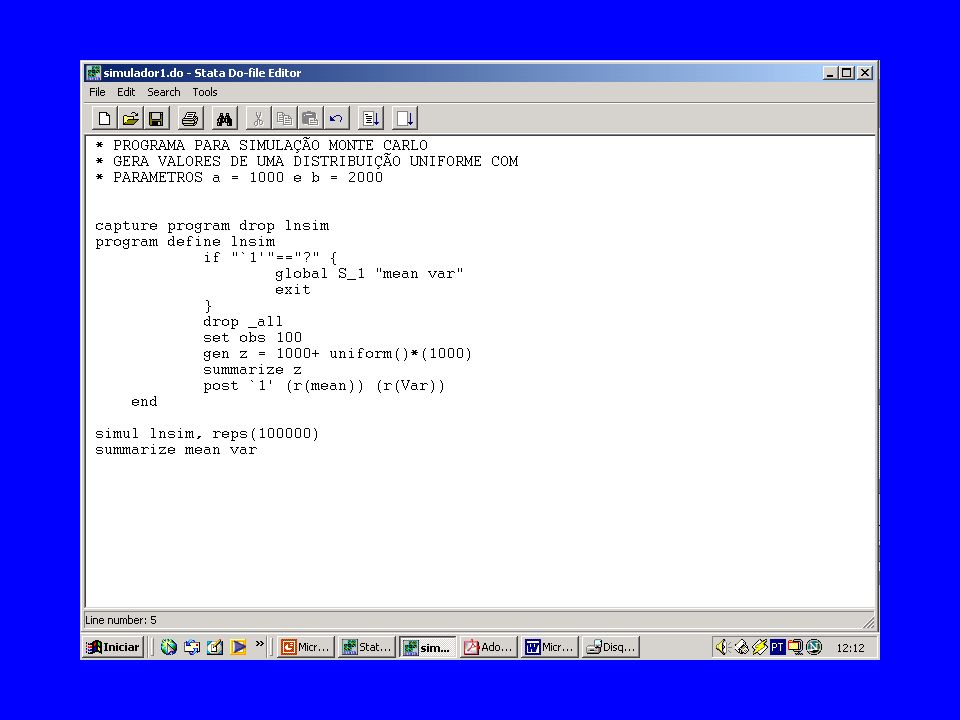
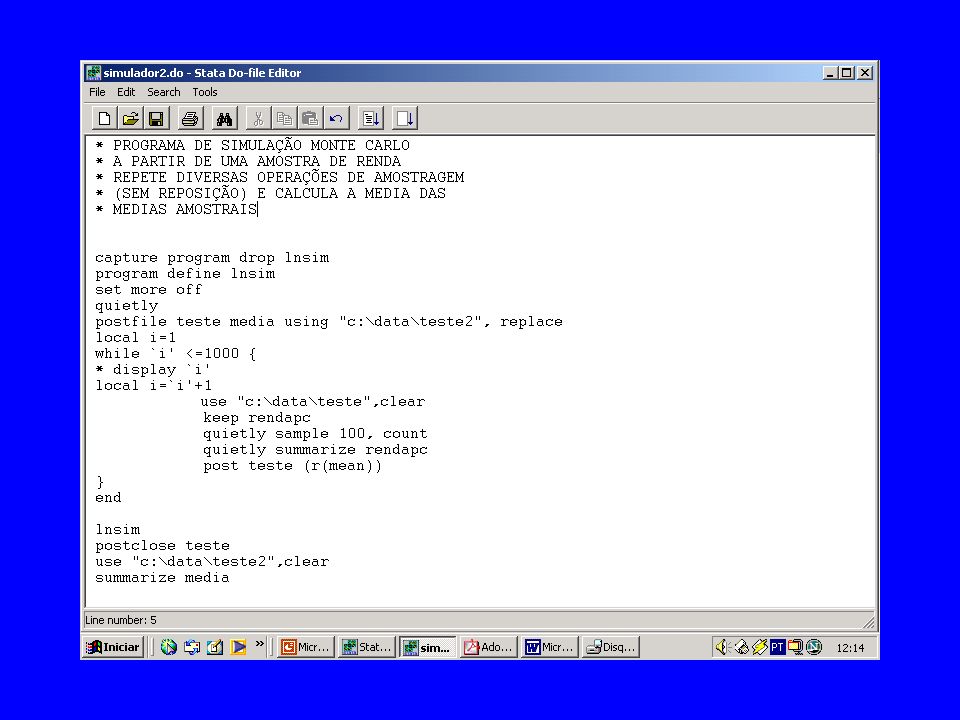
BOOTSTRAPPING Em muitas situações de análise de dados de amostras, não é possível fazer estimativas porque as fórmulas das variâncias dos estimadores simplesmente não existem ou porque analiticamente podem ser obtidas através de métodos muito exaustivos. Nestes casos uma solução prática para obtermos intervalos de confiança é o uso da técnica estatística conhecida na literatura como bootstrapping. Nesta técnica obtém-se a partir de uma única amostra um número grande de replicações que são amostras de mesmo tamanho com reposição selecionadas da amostra original.

17
A lógica por trás do bootstrapping é a seguinte: “em alguns casos a distribuição amostral pode ser derivada analiticamente. Por exemplo, se a população é distribuída normalmente e desejamos estimar médias, a distribuição amostral para a média é uma “t” de Student com n-1 graus de liberdade. Em outros casos, derivar a distribuição amostral é muito difícil, como no caso de médias estimadas de populações não normais (e com tamanhos de amostras pequenos, sem possibilidade de aplicação do Teorema do Limite Central)” (Stata Reference Manual, 2001).
 (Stata Reference Manual, 2001)..")
18
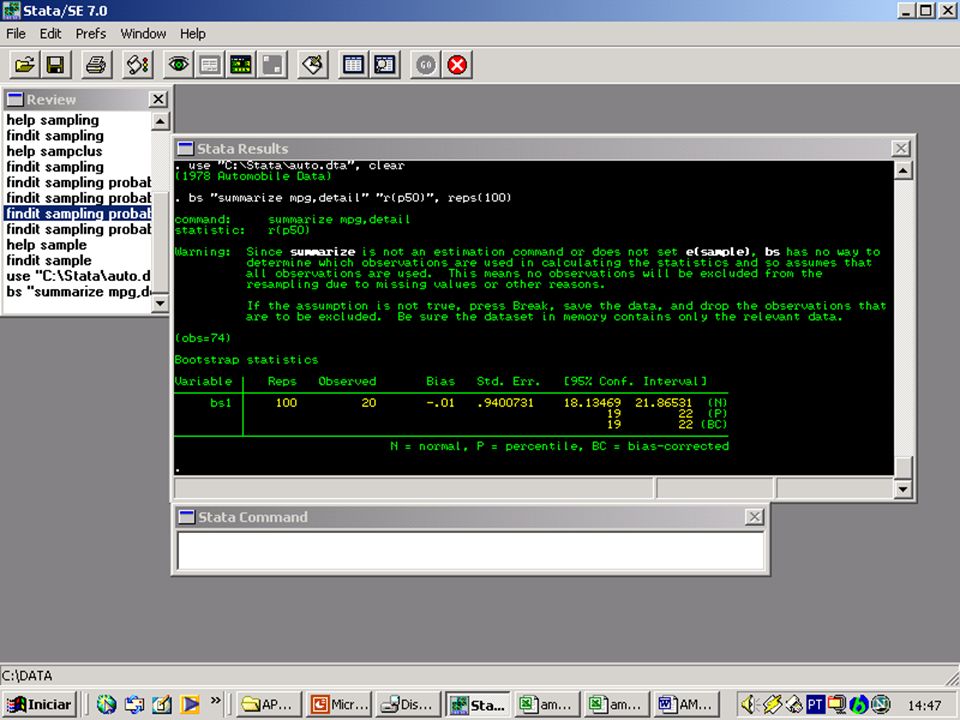
Se conhecermos a distribuição da população, podemos obter a distribuição amostral por simulação: podemos selecionar aleatoriamente amostras de tamanho n, de cada uma calcular o valor da estatística e desta forma construir uma distribuição para esta estatística. A técnica do bootstrapping faz precisamente isto, mas ela usa a distribuição observada na amostra no lugar da distribuição verdadeira da população. Portanto, esta técnica se baseia na hipótese de que a distribuição observada é uma boa estimativa da distribuição da população subjacente. Para exemplificar suponhamos que desejamos estimar um intervalo de confiança para a mediana da variável mpg através de uma amostra de 74 observações. No Stata podemos utilizar o seguinte comando: bs "summarize mpg,detail" "r(p50)", reps(100)
 , reps(100)")
20
bs "reg mpg weight foreign" "_b[weight] _b[foreign]", reps(100)
![bs reg mpg weight foreign _b[weight] _b[foreign] , reps(100)](http://slideplayer.com.br/slide/46011/1/images/20/bs+reg+mpg+weight+foreign+_b%5Bweight%5D+_b%5Bforeign%5D+%2C+reps%28100%29.jpg "bs reg mpg weight foreign _b[weight] _b[foreign] , reps(100)")
21
ALGUNS EXEMPLOS DE APLICAÇÕES DE AMOSTRAGEM
Nesta parte da apresentação serão mostrados alguns estudos de casos correspondendo a algumas experiências relacionadas a amostragem em pesquisas sócio-econômicas. Um primeiro estudo de caso refere-se a uma pesquisa das condições sociais das famílias de baixa renda de Uberlândia

22
Tabela A. 10 – distribuição da amostra por bairros e
pesos (fatores) de expansão da amostra
 de expansão da amostra.")
Apresentações semelhantes


















>")

